Hadoop 数据仓库建设实践(理论结合实践)_hadoop完成数据预处理、建立数据仓库、进行数据分析和数据导出(1)-程序员宅基地
技术标签: 2024年程序员学习 数据分析 数据仓库 hadoop
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
但是数据平台已然成为了一个机构和组织的关键基础设施,已经像“水电煤”一样不可或缺了。
既然是“水电煤”,那么还需要自己“发电”和“供水”吗?为什么要自己搭建物理数据平台并负责维护呢?目前技术的发展实际上也给出了否定的答案,未来的数据和数据平台就如同业务系统一样,都会在云端(可能是公有云,也可能是专有云)。随需随用,所以基于云的数据平台解决方案势必会成为主流。
业务背景
我们就假设某虚拟的、全国连锁的大型零售超市 FutureRetailer 为对象(国外的对标公司为沃尔玛、家乐福、乐购等),为其搭建基于 Hadoop 的数据仓库。之所以选择零售业务,是因为大家都非常熟悉其业务,包括全国连锁业务形态、收银台购物流程、商品供应、商品库存管理等。
并且 FutureRetailer 在全国的各个城市内运营着数以千计的超市 ,根据城市的人口规模和大小不同,门店也不同,比如对于一线或者重点二线城市,其门店可能数以十计甚至几十计,在某些三四级城市或者乡镇来说,可能只有一个甚至没有。其每一个门店都包含了完整各类商品包含杂货、日常生活用品、水果生鲜、肉类、蔬菜、冷冻食品、花卉等。
所以,对于 FutureRetailer 来说,数据仓库平台对其至关重要。因为数据平台是其数据化运营的前提和基础,基于数据仓库平台生成的各种销售报表和库存报表是公司管理层和各个城市运营人员以及门店运营人员决策的主要依据。
- 整个公司的整体销售趋势如何?
- 是否应该对某些滞销的商品进行促销?
- 客户是否在流失?
- 某些畅销商品是否应该及时补货 如何择自营商品从而利润最大化?
以上这些我们都需要通过及时、准确和精炼过的数据来支持。
同时对于 FutureRetailer 来说,过去的数据分析只是一个方面,更为重要的是对于未来的预测和分析。比如未来商品销售估计,并据此制订采购计划 。随着新零售的兴起,未来的消费者需要的是更为个性化的服务和产品,如何将这种个性化的商品和服务提供给消费者?

马爸爸也说过:“纯电商时代过去了,未来十年是新零售的时代”。
对 FutureRetailer 来说,未来的购物也许将会是如下情景:
1 )一位资深 FutureRetailer 会员,其近年来购买商品的种类、型号、时间 、支付方式、会员卡基本信息、住址、联系方式,以及由此生成的会员购买商品档次评级、消费评级、退款评价等都被数据平台详细记录。
2 )会员步入超市或者开车进入超市停车场, FutureRetailer 车牌识别系统、视频系统或者 WiFi 网络(如果会员通过手机接人)捕获到会员来访,预测会员可能的购买清单,井有针对性地生成促销和优惠信息 。比如,会员上次拿起某件商品仔细查看了商品价格但没有购买,那么 FutureRetailer 此次将推荐另一个高性价比的同款商品给会员。
3 )会员到收银台结账, FutureRetailer 会预测下次会员的来访时间,并更新采购计划和清单等。
上述所有智能化的、个性化的购买行为必须借助数据平台的支撑。
Hadoop 数据仓库架构设计
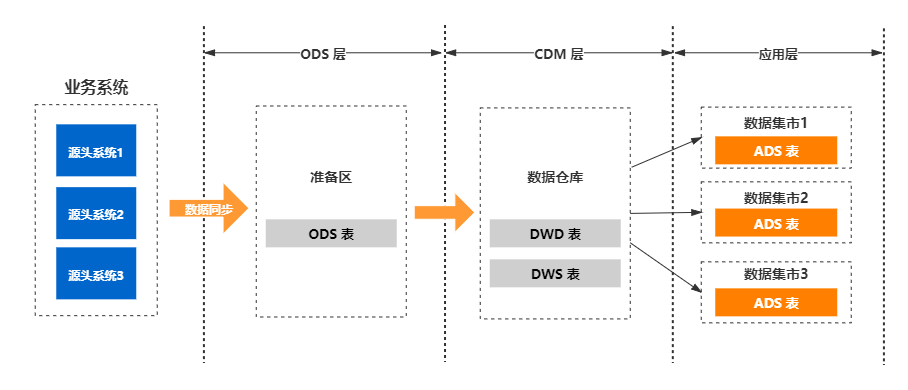
首先介绍基于 Hadoop 的数据仓库逻辑架构,在 Hadoop 数据仓库的实际设计中,通常出于可维护性、性能成本以及使用便捷性考虑,会对数据仓库中的表进行分层。
来自于源头操作性系统的数据表通常会原封不动地存储一份,这称为 ODS ( Operation Data Store )层 。ODS 层通常也被称为准备区( staging area ),它们是后续数据仓库层(即基于 Kimball 维度建模生成的事实表和维度表层,以及基于这些事实表和明细表加工的汇总层数据)加工数据的来源。同时 ODS 层也存储着历史的增量或者全量数据。
数据仓库层(DW层)是 Hadoop 数据平台的主体内容。
数据仓库层的数据是 ODS 层数据经过 ETL 清洗、转换、加载生成的。 Hadoop 数据仓库的 DW 层通常都是基于 Kimball 的维度建模理论来构建的,并通过 维度一致性 和 数据总线 来保证各个子主题的维度一致性。
DW 层的数据一定是清洗过的、干净的、一致的、规范的、准确的数据。数据平台的下游用户将会直接使用 DW 层数据,而 ODS 层数据原则上不允许下游用户直接接触和访问。
此外,处于性能、重复计算和使用便捷性考虑, DW 层数据除了保存基于 Kimball 维度建模的最细校度的事实表和维度表(即 DW 层的明细层),还会基于它们生成一层汇总数据(即 DW 的汇总层)。
汇总层的设计 主要是出于性能以及避免重复计算考虑。实际数据仓库的汇总层如何设计以及主要对哪些维度进行汇总等,需要根据业务需求以及明细层实际汇总频率来确定,原则上,业务使用频繁的维度需要对这些维度建立汇总层,汇总的指标可以和业务需求方共同设计完成。
在 DW 层的基础上,各个业务方或者部门可以建立自己的 数据集市( Data Mart ),此层一般称为 应用层 。应用层的数据来源于 DW 层,原则上不允许应用层直接访问 ODS 层,相比 DW 层,应用层只包含部门或者业务方自己关心的明细层和汇总层数据。
不同于 DW 层字段和指标的通用性,应用层可以包含自己业务或者部门特殊的指标或者字段,但是如果需要横向和其他部门对比, 必须采用公共层公用的指标和字段 。
采用上述“ ODS 层→ DW 层→应用层”的数据仓库逻辑架构如图所示:
项目实际中,采用上述分层架构可以有以下好处:
- 屏蔽源头系统业务变更、系统变更对于下游用户的影晌: 如果源头系统业务发生变更,相关的变更由 DW 层来处理,对下游用户透明,无须改动下游用户的代码和逻辑。
- 屏蔽源头业务系统的复杂性: 源头系统可能极为繁杂,而且表命名、字段命名 、字段含义等可能五花八门,通过 DW 层来规范和屏蔽所有这些复杂性,保证下游数据用户使用数据的便捷和规范。
- 避免重复计算和存储: 通过汇总层的引人,避免了下游用户逻辑的重复计算, 节省了用户的开发时间和精力,同时也节省了计算和存储。
- 数据仓库的可维护性: 分层的设计使得某一层的问题只在该层得到解决,无须更改下一层的代码和逻辑。
Hadoop 数据仓库规范设计
对于一个公司或者组织来说,使用数据的用户可能成百上千,如何降低大家对于数据使用的沟通成本、如何通过规范大家的行为来降低使用数据的风险,这些问题是必须加以考虑的。
我们在实际实践中,通常用数据仓库的规范来达到此目的。数据仓库的规范包括很多方面,如数据的命名规范、开发规范、流程规范、安全规范和质量规范等,下面将结合 FutureRetail 业务介绍常用的命名、开发和流程规范。
命名规范
命名的规范主要分为表命名的规范和字段命名的规范。
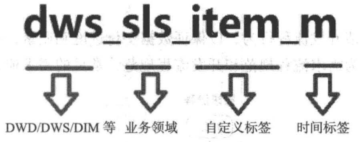
其中表命名的规范是为了让数据所有相关方对表包含的信息有一个共同的认知,比如属于哪一层(ODS、DWD、DWS、ADS)?哪个业务领域(销售、库存、促销)等?哪个维度(商品、买家、卖家、类目等)?哪个时间跨度(天、月、年、实时)?增量还是全量?
基于此,数据平台建设者应该首先规定数据仓库分层、业务领域、常见维度和时间跨度等的英文缩写,并据此给出表的命名规范。
开发规范
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)
[外链图片转存中…(img-fH2og87X-1713706863336)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
智能推荐
攻防世界_难度8_happy_puzzle_攻防世界困难模式攻略图文-程序员宅基地
文章浏览阅读645次。这个肯定是末尾的IDAT了,因为IDAT必须要满了才会开始一下个IDAT,这个明显就是末尾的IDAT了。,对应下面的create_head()代码。,对应下面的create_tail()代码。不要考虑爆破,我已经试了一下,太多情况了。题目来源:UNCTF。_攻防世界困难模式攻略图文
达梦数据库的导出(备份)、导入_达梦数据库导入导出-程序员宅基地
文章浏览阅读2.9k次,点赞3次,收藏10次。偶尔会用到,记录、分享。1. 数据库导出1.1 切换到dmdba用户su - dmdba1.2 进入达梦数据库安装路径的bin目录,执行导库操作 导出语句:./dexp cwy_init/[email protected]:5236 file=cwy_init.dmp log=cwy_init_exp.log 注释: cwy_init/init_123..._达梦数据库导入导出
js引入kindeditor富文本编辑器的使用_kindeditor.js-程序员宅基地
文章浏览阅读1.9k次。1. 在官网上下载KindEditor文件,可以删掉不需要要到的jsp,asp,asp.net和php文件夹。接着把文件夹放到项目文件目录下。2. 修改html文件,在页面引入js文件:<script type="text/javascript" src="./kindeditor/kindeditor-all.js"></script><script type="text/javascript" src="./kindeditor/lang/zh-CN.js"_kindeditor.js
STM32学习过程记录11——基于STM32G431CBU6硬件SPI+DMA的高效WS2812B控制方法-程序员宅基地
文章浏览阅读2.3k次,点赞6次,收藏14次。SPI的详情简介不必赘述。假设我们通过SPI发送0xAA,我们的数据线就会变为10101010,通过修改不同的内容,即可修改SPI中0和1的持续时间。比如0xF0即为前半周期为高电平,后半周期为低电平的状态。在SPI的通信模式中,CPHA配置会影响该实验,下图展示了不同采样位置的SPI时序图[1]。CPOL = 0,CPHA = 1:CLK空闲状态 = 低电平,数据在下降沿采样,并在上升沿移出CPOL = 0,CPHA = 0:CLK空闲状态 = 低电平,数据在上升沿采样,并在下降沿移出。_stm32g431cbu6
计算机网络-数据链路层_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏8次。数据链路层习题自测问题1.数据链路(即逻辑链路)与链路(即物理链路)有何区别?“电路接通了”与”数据链路接通了”的区别何在?2.数据链路层中的链路控制包括哪些功能?试讨论数据链路层做成可靠的链路层有哪些优点和缺点。3.网络适配器的作用是什么?网络适配器工作在哪一层?4.数据链路层的三个基本问题(帧定界、透明传输和差错检测)为什么都必须加以解决?5.如果在数据链路层不进行帧定界,会发生什么问题?6.PPP协议的主要特点是什么?为什么PPP不使用帧的编号?PPP适用于什么情况?为什么PPP协议不_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输
软件测试工程师移民加拿大_无证移民,未受过软件工程师的教育(第1部分)-程序员宅基地
文章浏览阅读587次。软件测试工程师移民加拿大 无证移民,未受过软件工程师的教育(第1部分) (Undocumented Immigrant With No Education to Software Engineer(Part 1))Before I start, I want you to please bear with me on the way I write, I have very little gen...
随便推点
Thinkpad X250 secure boot failed 启动失败问题解决_安装完系统提示secureboot failure-程序员宅基地
文章浏览阅读304次。Thinkpad X250笔记本电脑,装的是FreeBSD,进入BIOS修改虚拟化配置(其后可能是误设置了安全开机),保存退出后系统无法启动,显示:secure boot failed ,把自己惊出一身冷汗,因为这台笔记本刚好还没开始做备份.....根据错误提示,到bios里面去找相关配置,在Security里面找到了Secure Boot选项,发现果然被设置为Enabled,将其修改为Disabled ,再开机,终于正常启动了。_安装完系统提示secureboot failure
C++如何做字符串分割(5种方法)_c++ 字符串分割-程序员宅基地
文章浏览阅读10w+次,点赞93次,收藏352次。1、用strtok函数进行字符串分割原型: char *strtok(char *str, const char *delim);功能:分解字符串为一组字符串。参数说明:str为要分解的字符串,delim为分隔符字符串。返回值:从str开头开始的一个个被分割的串。当没有被分割的串时则返回NULL。其它:strtok函数线程不安全,可以使用strtok_r替代。示例://借助strtok实现split#include <string.h>#include <stdio.h&_c++ 字符串分割
2013第四届蓝桥杯 C/C++本科A组 真题答案解析_2013年第四届c a组蓝桥杯省赛真题解答-程序员宅基地
文章浏览阅读2.3k次。1 .高斯日记 大数学家高斯有个好习惯:无论如何都要记日记。他的日记有个与众不同的地方,他从不注明年月日,而是用一个整数代替,比如:4210后来人们知道,那个整数就是日期,它表示那一天是高斯出生后的第几天。这或许也是个好习惯,它时时刻刻提醒着主人:日子又过去一天,还有多少时光可以用于浪费呢?高斯出生于:1777年4月30日。在高斯发现的一个重要定理的日记_2013年第四届c a组蓝桥杯省赛真题解答
基于供需算法优化的核极限学习机(KELM)分类算法-程序员宅基地
文章浏览阅读851次,点赞17次,收藏22次。摘要:本文利用供需算法对核极限学习机(KELM)进行优化,并用于分类。
metasploitable2渗透测试_metasploitable2怎么进入-程序员宅基地
文章浏览阅读1.1k次。一、系统弱密码登录1、在kali上执行命令行telnet 192.168.26.1292、Login和password都输入msfadmin3、登录成功,进入系统4、测试如下:二、MySQL弱密码登录:1、在kali上执行mysql –h 192.168.26.129 –u root2、登录成功,进入MySQL系统3、测试效果:三、PostgreSQL弱密码登录1、在Kali上执行psql -h 192.168.26.129 –U post..._metasploitable2怎么进入
Python学习之路:从入门到精通的指南_python人工智能开发从入门到精通pdf-程序员宅基地
文章浏览阅读257次。本文将为初学者提供Python学习的详细指南,从Python的历史、基础语法和数据类型到面向对象编程、模块和库的使用。通过本文,您将能够掌握Python编程的核心概念,为今后的编程学习和实践打下坚实基础。_python人工智能开发从入门到精通pdf