最全NLP语料资源集合及其构建现状-程序员宅基地

作者刘焕勇,语言学硕士,目前就职于中国科学院软件研究所,主要从事信息抽取,知识图谱,情感分析, 社会计算等自然语言处理研发工作,兴趣包括:语言资源构建、信息抽取与知识图谱、舆情监测与社会计算。
本项目包含中文自然语言处理的语料集合,包括语义词、领域共时、历时语料库、评测语料库等。本项目简单谈谈自己对语言资源的感想以及目前自己进行语言资源构建的现状。
介绍
语言资源,本身是一个宽泛的概念,即语言+资源,语言指的是资源的限定域,资源=资+源,是资料的来源或者汇总,加在一起,也就形成了这样一种界定:任何语言单位形成的集合,都可以称为语言资源。语言资源是自然语言处理任务中的一个必不可少的组成部分,一方面语言资源是相关语言处理任务的支撑,为语言处理任务提供先验知识进行辅助,另一方面,语言处理任务也为语言资源提出了需求,并能够对语言资源的搭建、扩充起到技术性的支持作用。因此,随着自然语言处理技术的不断发展,自然语言处理需求在各个领域的不断扩张、应用,相关语言资源的构建占据了越来越为重要的地位。作者在硕士期间所在的研究机构为国家语言资源监测与研究平面媒体中心,深受导师所传授的语言资源观影响,毕业后在实际的学习、工作过程中,动手实践,形成了自己的一些浅薄的语言资源认识,现在写出来,供大家一起讨论,主要介绍一些自己对语言资源的搜索,搭建过程中的一些心得以及自己目前在语言资源建设上的一些工作。
语言资源的分类
介绍中说到,任何语言单位的集合都可以称为语言资源,比如我有一个个人的口头禅集合,这个就可以称为一个语言资源库,在你实际生活中进行言语活动时,你其实就在使用这个语言资源库。再比如说,一个班级中的学生名单,其实也可以当作是一种语言资源,这个语言资源在进行班级学生点名、考核的时候也大有帮助。当然,此处所讨论的语言资源是从自然语言处理应用的角度上出发的。总的来说,我把它归为以下两种类型:
1、领域语料库
领域语料库,是从语料的这个角度来讲的,这里的语料,界定成文本级别(以自然语句为基础级别形成的文本集合,即可以是句子、段落、篇章等)。领域语料库,可以根据不同的划分规则而形成不同的语料类别:
1)根据所属领域,可以进一步细化成不同领域的语料库。包括金融领域语料、医药领域语料、教育领域语料、文学领域语料等等。
2)根据所属目的,可以进一步细化为:评测语料(为自然语言处理技术pk而人工构造的一些评测语料,如ACE,MUC等国际评测中所出现的如semeval2014,snli等);工具语料(指供自然语言处理技术提供资源支撑的语料)
3)根据语料加工程度的不同,可进一步分为:熟语料(指在自然语言单位上添加人工的标签标注,如经过分词、词性标注、命名实体识别、依存句法标注形成的语料),生语料(指直接收集而未经加工形成的语言资源集,如常见的微博语料,新闻语料等)
4)根据语料语种的不同,可进一步分为:单语语料和多语语料,多语语料指的是平行语料,常见于机器翻译任务中的双语对齐语料(汉-阿平行语料库,汉-英平行语料库)等。
5)根据语料规模的不同,可以进一步分为:小型语料库,中型语料库,大型语料库。至于小型、中型、大型的界定,可根据实际领域语料的规模而动态调整。
2、领域词库
领域词库,指以句级以下语言单位形成的语言资源库,这个层级的语言单位可以是笔画、偏旁部首、字、词、短语等。同样的,领域词库也可以进一步细分。
1)领域特征词库。这里所说的领域特征词库,指的是与领域强相关,具有领域区别能力形成的词语集合,如体育领域中常见的“篮球”、“足球”等词,文学领域常见的“令狐冲”、“鲁迅”等词,又如敏感词库等,这些词常常可作为分类特征而存在。
2)语法语义词库。语义词库的侧重点在与语言的语法层面和语义层面:
语法词库:北大的语法信息词典,北大的实体概念词典、Hownet语义词典这三类词典,这几个语法词库,在对词的语法功能上都做了不同的工作,对词的内部结构信息进行了详细的标注,如北大的语法信息词典,以词类为划分标准讲汉语的常用词进行了划分,并对词性、搭配(前接成分和后接成分)进行了详细的标注;Hownet语义词典从义项的角度对词的义元进行了分解和注释。
语义词库:这类语义词,侧重点不在词语的内部语法结构,而在词语的整体语义上。这类词库,常见的词库有哈工大发布的同义词词林扩展版,这个词库将同义词按照语义的相近程度进行了不同层次的聚类,可以作为同义词扩展提供帮助。另一个是情感分析任务中常用的情感词典,这类词典主要公开的词典包括大连理工大学信息检索实验室公开的情感本体词库、hownet、香港中文大学、台湾清华大学公开的情感词库(具体包括情感词库、否定词库、强度词库)等。另外,工业界,有boson公开的微博情感词库(词的规模比较大,但标注信息不是很精准)。还有的,则是中文的反义词库等,这个可以参考我的github项目,里面对这些词库也有一些涉及。
语言资源的问题
语言资源的搭建,指的是语言资源的整个搭建过程。其实是要解决四个问题,一个是语言资源的收集问题;二是语言资源的融合标准化问题;三是语言资源的动态更新问题;四是语言资源的共享与联盟问题。下面就这四点展开阐述:
1、语言资源收集的问题。语言资源搜索过程中有三步走策略,在这个步骤完成之后,会得到一系列的词库。这些词库可能初期不会特别完善,往往还需要人工使用启发式规则进行人工去噪的工作。
2、语言资源的融合标准化问题。通过不同方式收集起来的语言资源,往往会存在一个格式不对称的问题,这有点像知识图谱中的知识融合问题。因此,为了解决这个问题,我们通常需要制定一个标准化的语言资源格式,例如,在构建情感词表的过程当中,有的情感词表没有强度标记,有的强度值范围不一样,有的情感词表的标记不一,这个时候往往需要标准化,给定一个标准化的样式,再将不同来源的情感词按照这个标记做相应的调整。我在实际的工作过程中,常常把这种问题类别成知识图谱构建过程中的schema搭建问题,信息抽取过程中的slot-definition问题。先把规范和标准搭好,再去统一标准化。
3、语言资源的动态更新问题。知识和信息的价值,在很大程度上都在于它的一种实时性,语言资源作为一种常识性知识库,能够保证自身的一种与时俱进,将能够最大限度地发挥自身的价值。而从实践的角度上来说,语言资源的动态更新,可以靠人工去维持,去动态及时更新,也可以建立一种动态监测和更新机制,让机器自动地去更新。这类其实可以参考知识图谱更新的相关工作。
4、语言资源的共享与联盟问题。语言资源是否共享,其实是一个与业务敏感以及开源意识想结合的一种决策,有的资源因为某种业务敏感或者开源意识不够open而无法共享,当然还有其他因素成分在,不过,语言资源最好是需要共享的,这样能够最大力度的发挥语言资源在各个领域的应用。语言资源的联盟问题,更像是对开源语言资源的一种链接与互联。这类问题是对当前的资源零散、碎片化问题的一个思考,前面也说到,目前情感分析的词表有很多个,语法和语义词库也有很多个,但每个人在构建时的出发点不同,构建者也分布在不同的高校或机构当中,这些资源虽然在个数上会有增长,但随着时间的推移,这种零散化的现象将会越来越严重。
语言资源的实践
本项目以采集公开的人民日报与参考消息为例进行历时的新闻采集为例, 公开网站中公开了1946-2003年的人民日报语料,1957-2002年的参考消息语料, 采集这种具有长远历史信息的语料对于历史人文研究以及语言演变有重大意义,本项目放在newspaper目录下。
运行方式: scrapy crawl travel
主要函数包括:
class TravelSpider(scrapy.Spider):
name = 'travel'
'''资讯采集主控函数'''
def start_requests(self):
Data = BuildData()
date_list = Data.create_dates()
for date in date_list:
print(date)
date_url = 'http://www.laoziliao.net/ckxx/%s'%date
param = {
'url': date_url, 'date': date}
yield scrapy.Request(url=date_url, meta=param, callback=self.get_urllist, dont_filter=True)
'''获取页面新闻列表'''
def get_urllist(self, response):
selector = etree.HTML(response.text)
date_url = response.meta['url']
urls = [i.split('#')[0] for i in selector.xpath('//ul/li/a/@href') if date_url in i]
for url in set(urls):
param = {
'url':url , 'date': response.meta['date']}
yield scrapy.Request(url=url, meta=param, callback=self.page_parser, dont_filter=True)
'''新闻字段内容解析'''
def page_parser(self, response):
selector = etree.HTML(response.text)
articles = selector.xpath('//div[@class="article"]')
titles = selector.xpath('//h2/text()')
contents = []
for article in articles:
content = article.xpath('string(.)')
contents.append(content)
papers = zip(titles, contents)
for i in papers:
item = TravelspiderItem()
item['url'] = response.meta['url']
item['date'] = response.meta['date']
item['title'] = i[0]
item['content'] = i[1]
yield item
return
语言资源构建现状
作者在学习和工作之余,根据语言资源搭建策略,构建起了语义词库、领域词库、领域语料库、评测语料库。种类约53种,具体如下:
语义知识库
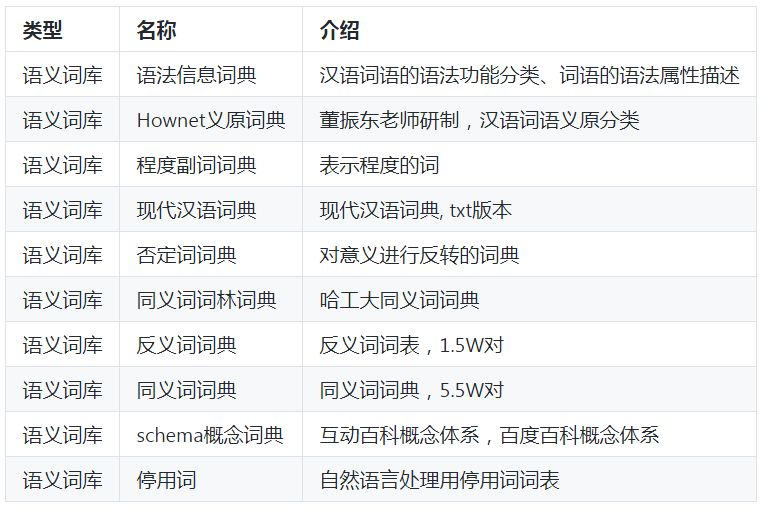
领域词库
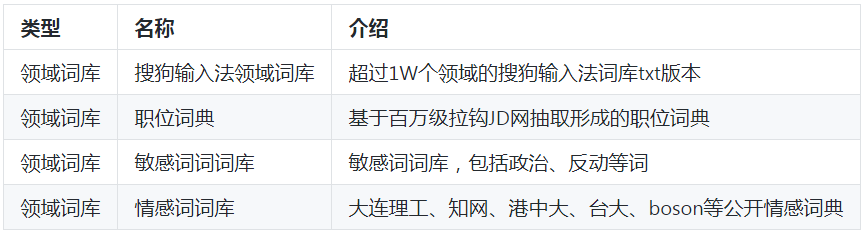
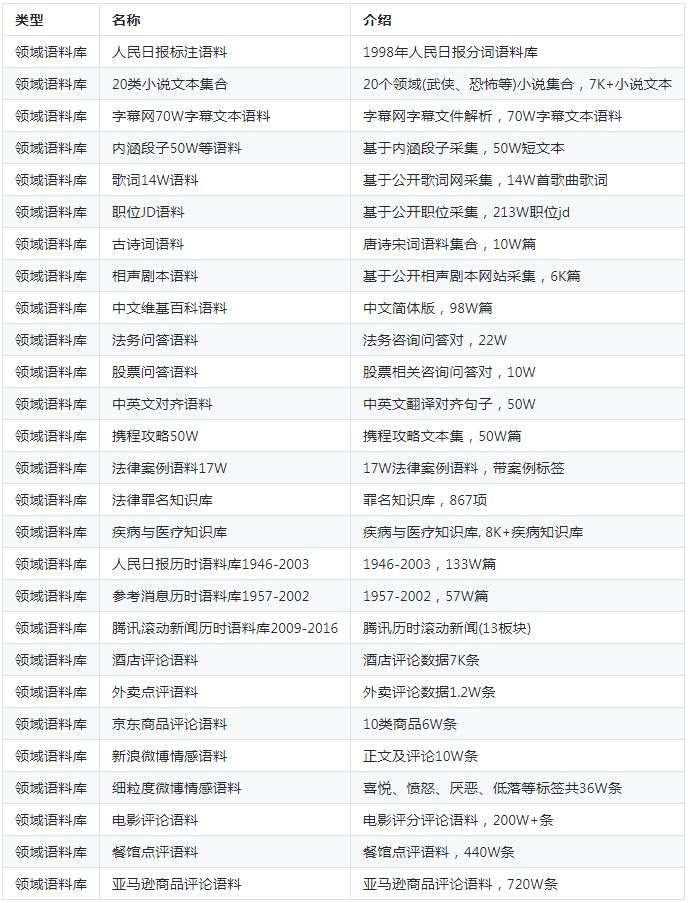
领域语料库
评测语料库

总结
1、本项目阐述了语言资源的相关感想,并给出了目前语言资源的构建现状,目前为止收集了四个大类共53小类的语言资源数据集。
2、本项目中所涉及到的报告内容均来源于网上公开资源,对此免责声明。
3、如果有需要用到以上作者收集到的这些语料库,可以联系作者获取。
4、自然语言处理,是人工智能皇冠上的一颗明珠,懂语言者得天下,语言资源在自然语言处理中扮演着举足轻重的作用,懂语言资源者,分得天下。目前开放的网络环境,对语言资源的大繁荣提供了很大的契机。语言资源构建是一门学问,也是一种手段,现在自然语言处理技术也对语言资源的构建提供了技术上的支持,如何把握语言资源搜索策略,搭建策略,重点解决语言资源的动态更新、共享与联盟问题,将是语言资源建设未来需要解决的问题。
如有自然语言处理、知识图谱、事理图谱、社会计算、语言资源建设等问题或合作,可联系我:
1、我的github项目介绍:https://liuhuanyong.github.io
2、我的csdn博客:https://blog.csdn.net/lhy2014
3、刘焕勇,中国科学院软件研究所,[email protected]
原文地址:
https://github.com/liuhuanyong/ChineseNLPCorpus
(*本文仅代表作者独立观点,转载请联系原作者)
公开课预告
◆
强化学习
◆
本期课程中,微软小冰全球首席架构师及研发总监周力博士将介绍微软小冰在全双工语音对话方面的最新成果,及其在智能硬件上的应用和未来将面临的更多技术产品挑战。

推荐阅读
智能推荐
oracle 12c 集群安装后的检查_12c查看crs状态-程序员宅基地
文章浏览阅读1.6k次。安装配置gi、安装数据库软件、dbca建库见下:http://blog.csdn.net/kadwf123/article/details/784299611、检查集群节点及状态:[root@rac2 ~]# olsnodes -srac1 Activerac2 Activerac3 Activerac4 Active[root@rac2 ~]_12c查看crs状态
解决jupyter notebook无法找到虚拟环境的问题_jupyter没有pytorch环境-程序员宅基地
文章浏览阅读1.3w次,点赞45次,收藏99次。我个人用的是anaconda3的一个python集成环境,自带jupyter notebook,但在我打开jupyter notebook界面后,却找不到对应的虚拟环境,原来是jupyter notebook只是通用于下载anaconda时自带的环境,其他环境要想使用必须手动下载一些库:1.首先进入到自己创建的虚拟环境(pytorch是虚拟环境的名字)activate pytorch2.在该环境下下载这个库conda install ipykernelconda install nb__jupyter没有pytorch环境
国内安装scoop的保姆教程_scoop-cn-程序员宅基地
文章浏览阅读5.2k次,点赞19次,收藏28次。选择scoop纯属意外,也是无奈,因为电脑用户被锁了管理员权限,所有exe安装程序都无法安装,只可以用绿色软件,最后被我发现scoop,省去了到处下载XXX绿色版的烦恼,当然scoop里需要管理员权限的软件也跟我无缘了(譬如everything)。推荐添加dorado这个bucket镜像,里面很多中文软件,但是部分国外的软件下载地址在github,可能无法下载。以上两个是官方bucket的国内镜像,所有软件建议优先从这里下载。上面可以看到很多bucket以及软件数。如果官网登陆不了可以试一下以下方式。_scoop-cn
Element ui colorpicker在Vue中的使用_vue el-color-picker-程序员宅基地
文章浏览阅读4.5k次,点赞2次,收藏3次。首先要有一个color-picker组件 <el-color-picker v-model="headcolor"></el-color-picker>在data里面data() { return {headcolor: ’ #278add ’ //这里可以选择一个默认的颜色} }然后在你想要改变颜色的地方用v-bind绑定就好了,例如:这里的:sty..._vue el-color-picker
迅为iTOP-4412精英版之烧写内核移植后的镜像_exynos 4412 刷机-程序员宅基地
文章浏览阅读640次。基于芯片日益增长的问题,所以内核开发者们引入了新的方法,就是在内核中只保留函数,而数据则不包含,由用户(应用程序员)自己把数据按照规定的格式编写,并放在约定的地方,为了不占用过多的内存,还要求数据以根精简的方式编写。boot启动时,传参给内核,告诉内核设备树文件和kernel的位置,内核启动时根据地址去找到设备树文件,再利用专用的编译器去反编译dtb文件,将dtb还原成数据结构,以供驱动的函数去调用。firmware是三星的一个固件的设备信息,因为找不到固件,所以内核启动不成功。_exynos 4412 刷机
Linux系统配置jdk_linux配置jdk-程序员宅基地
文章浏览阅读2w次,点赞24次,收藏42次。Linux系统配置jdkLinux学习教程,Linux入门教程(超详细)_linux配置jdk
随便推点
matlab(4):特殊符号的输入_matlab微米怎么输入-程序员宅基地
文章浏览阅读3.3k次,点赞5次,收藏19次。xlabel('\delta');ylabel('AUC');具体符号的对照表参照下图:_matlab微米怎么输入
C语言程序设计-文件(打开与关闭、顺序、二进制读写)-程序员宅基地
文章浏览阅读119次。顺序读写指的是按照文件中数据的顺序进行读取或写入。对于文本文件,可以使用fgets、fputs、fscanf、fprintf等函数进行顺序读写。在C语言中,对文件的操作通常涉及文件的打开、读写以及关闭。文件的打开使用fopen函数,而关闭则使用fclose函数。在C语言中,可以使用fread和fwrite函数进行二进制读写。 Biaoge 于2024-03-09 23:51发布 阅读量:7 ️文章类型:【 C语言程序设计 】在C语言中,用于打开文件的函数是____,用于关闭文件的函数是____。
Touchdesigner自学笔记之三_touchdesigner怎么让一个模型跟着鼠标移动-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏13次。跟随鼠标移动的粒子以grid(SOP)为partical(SOP)的资源模板,调整后连接【Geo组合+point spirit(MAT)】,在连接【feedback组合】适当调整。影响粒子动态的节点【metaball(SOP)+force(SOP)】添加mouse in(CHOP)鼠标位置到metaball的坐标,实现鼠标影响。..._touchdesigner怎么让一个模型跟着鼠标移动
【附源码】基于java的校园停车场管理系统的设计与实现61m0e9计算机毕设SSM_基于java技术的停车场管理系统实现与设计-程序员宅基地
文章浏览阅读178次。项目运行环境配置:Jdk1.8 + Tomcat7.0 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:Springboot + mybatis + Maven +mysql5.7或8.0+html+css+js等等组成,B/S模式 + Maven管理等等。环境需要1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。_基于java技术的停车场管理系统实现与设计
Android系统播放器MediaPlayer源码分析_android多媒体播放源码分析 时序图-程序员宅基地
文章浏览阅读3.5k次。前言对于MediaPlayer播放器的源码分析内容相对来说比较多,会从Java-&amp;gt;Jni-&amp;gt;C/C++慢慢分析,后面会慢慢更新。另外,博客只作为自己学习记录的一种方式,对于其他的不过多的评论。MediaPlayerDemopublic class MainActivity extends AppCompatActivity implements SurfaceHolder.Cal..._android多媒体播放源码分析 时序图
java 数据结构与算法 ——快速排序法-程序员宅基地
文章浏览阅读2.4k次,点赞41次,收藏13次。java 数据结构与算法 ——快速排序法_快速排序法