电商客户价值细分 - RFM 模型(中)_rfm使用均值还是中位数判断价值-程序员宅基地
技术标签: python 数据分析 big data 数据挖掘 Python 开发语言
4.1 RFM 模型的概念
RFM 模型是一个传统的数据分析模型,沿用至今约 60 年。
1961 年,乔治·卡利南在顾客的资料库中指出,最近一次消费、消费频率、消费金额三项数据可以较为客观地描绘顾客的轮廓。
企业针对近期有消费的“新客”、消费频率高的“常客”、消费金额高的“贵客”进行精准营销和广告投放,确实收到了意料之外的惊喜。
因此,这三项数据成为了衡量客户价值和客户创利能力的重要工具和手段。也是 RFM 模型的三个重要指标:
1)R(Recency):最近一次消费时间间隔,指用户最近一次消费时间距离现在的时间间隔;
2)F(Frequency):消费频率,指用户一段时间内消费了多少次;
3)M(Monetary):消费金额,指用户一段时间内的消费金额。

这里举个例子来说明 3 个指标是什么意思。
小钟有一家店铺,小王是这家店的用户,今天是 12 月 31 号。
小王最近一次在店铺买东西是这个月 12 号,最近一次消费距离现在过去了 19 天,所以小王的最近一次消费时间间隔(R)是 19 天。
如果我们对“一段时间”的定义是 12 月,该月小王在店铺有 2 次消费记录,那么小王的消费频率(F)是 2 次。
小王在 2 次消费过程中共消费 1314 元,则小王的消费金额(M)为 1314 元。
3 个指标针对的业务不同,定义也会有所不同。但是无论是什么业务,各指标都有如下的特征:
1)最近一次消费时间间隔(R):上一次消费时间离现在越近,再次消费的几率越大。即 R 值越小,用户的活跃度越大,用户的价值就越高;
2)消费频率(F):购买频率越高,说明用户对品牌产生一定的信任和情感维系。即 F 值越大,用户的忠诚度就越大,用户的价值就越高;
3)消费金额(M):消费金额越高,说明用户对产品的购买力越大。即 M 值越大,用户的购买力就越大,用户的价值就越高。
有高价值用户的存在,自然也会有低价值用户的存在,即每个指标数据的价值都有高低两种情况。
因此,把 3 个指标的价值组合起来看,会有 2 x 2 x 2 = 8 种组合。
如果把 R、F、M 的价值高低作为坐标轴,可以将用户划分为下图的 8 个类型:
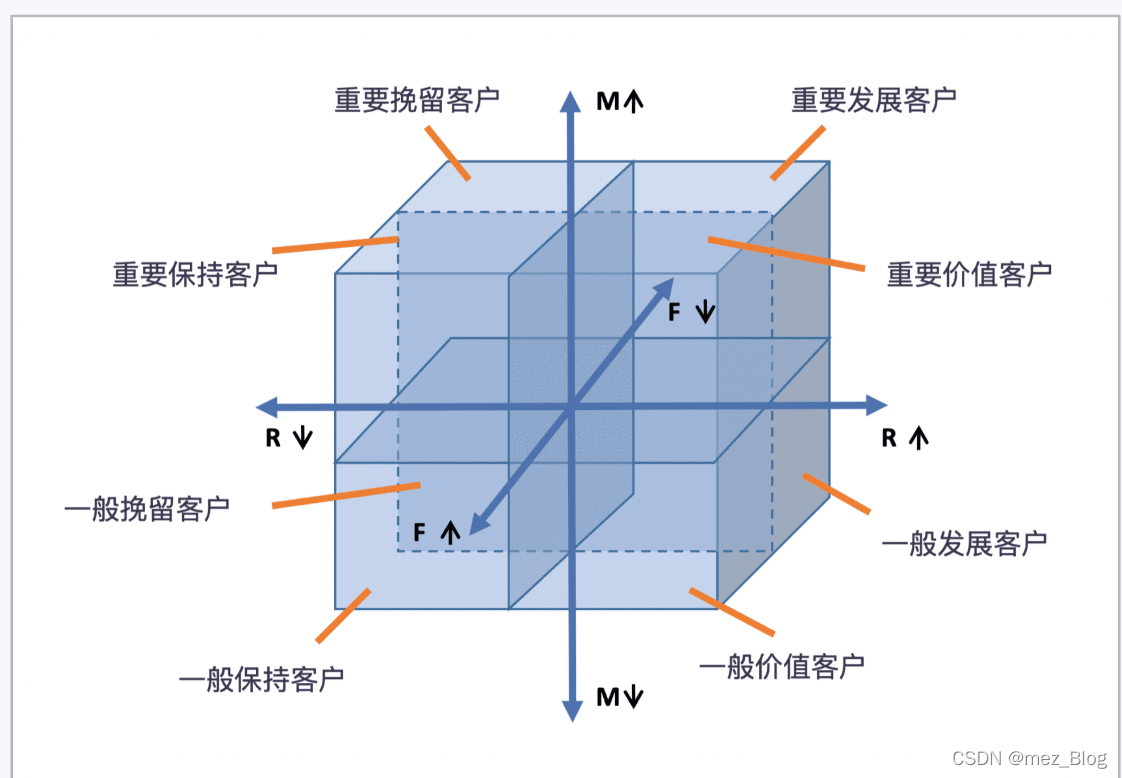
再将上图中的用户分类进行总结,可以得到下图的用户分类规则表。
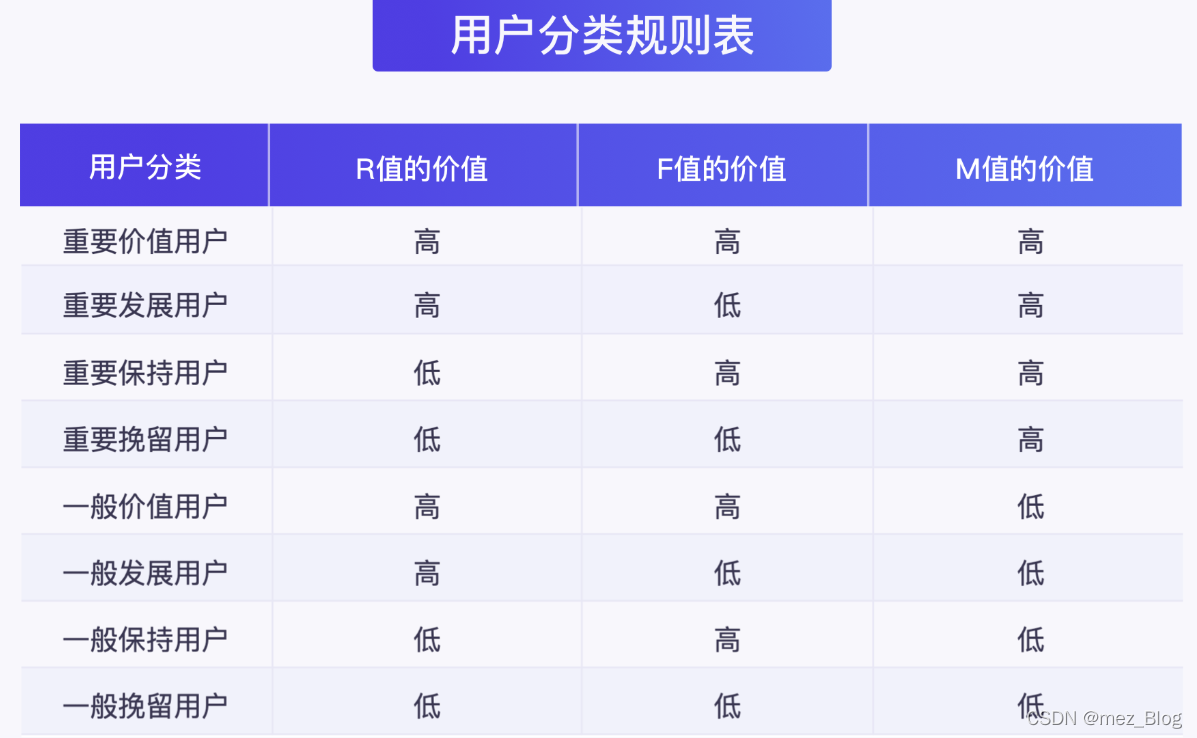
据 RFM 模型得到用户的分类后有什么用呢?一起来看下它的作用。
4.2 RFM 模型的作用
RFM 模型多用于精细化运营服务。单看 R、F、M 三个指标,其本身已经具备了一定的参考性:
一般来说,比起许久没有消费的顾客,消费时间间隔短的客户再次购买的几率较高。针对这类客户,可以采取唤醒或者刺激消费,如赠送打折券等。
消费频率高的客户,其忠诚度相对较高,可以规律性地提醒这类客户关于产品的一些优惠信息。
消费金额高的客户,客户价值也越高,可以提供专属该类客户的优惠价格。

如果根据 RFM 模型将用户细分为 8 类,还能进一步对不同价值的用户使用不同的运营策略,获取并保留关键性用户,针对价值高的客户制定促销策略。
比如重要价值用户,这类用户最近一次消费时间较近,消费频率高,消费金额高,需要提供 VIP 服务和个性化服务,提升品牌形象。
对于一般挽留用户,其最近一次消费时间较远,消费频率低,消费金额低,可以减少该类用户的营销成本和服务预算。
ok,RFM 模型的作用也了解完毕。接下来,我们具体看看 RFM 模型是如何根据用户分类规则表将用户分为 8 类。
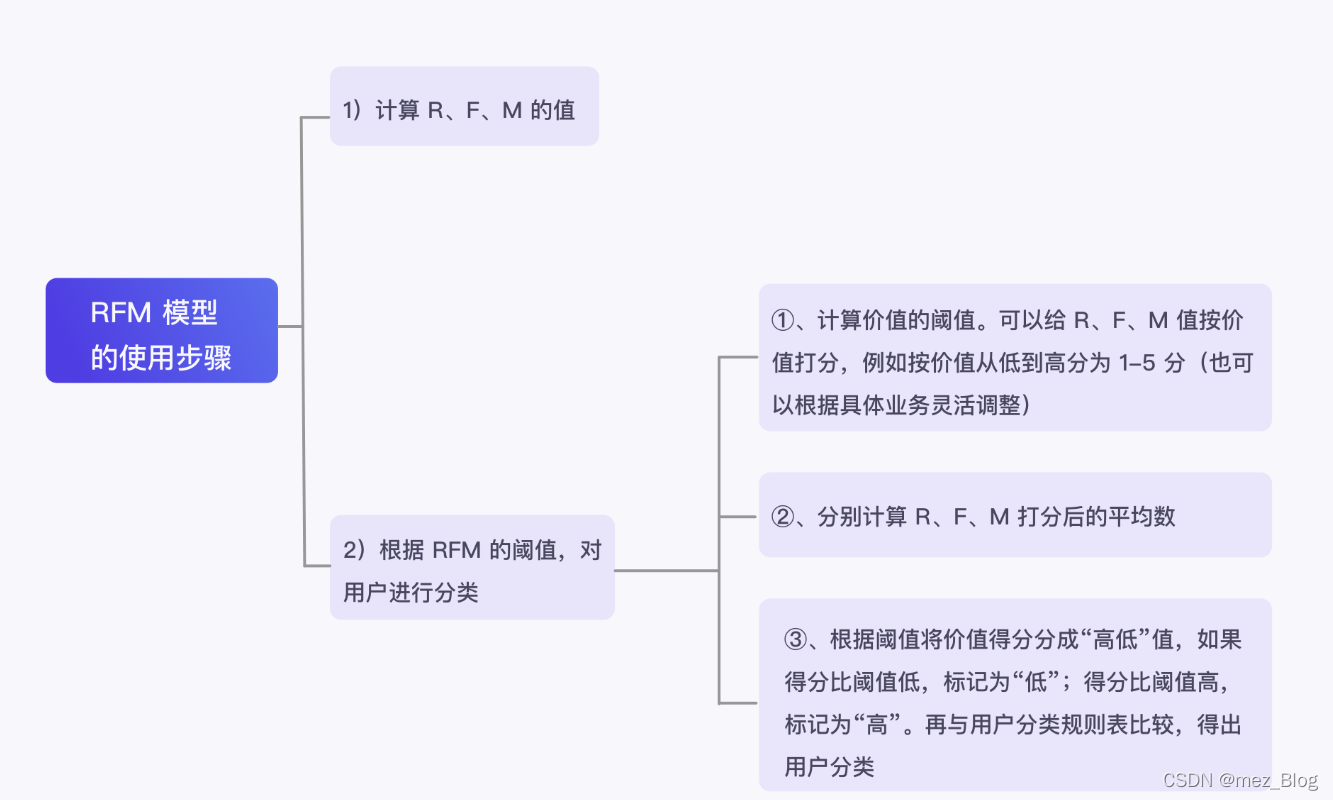
4.3 RFM 模型的构建流程
4.3.1 计算 R、F、M 的值
得到 R、F、M 这 3 个指标,一般需要的信息有:用户名称/用户 ID、消费记录(如消费时间、消费金额)。
假设现在是 2020 年 12 月 30 日,分析最近 30 天有进行消费的用户。其中:
用户小许最近一次消费时间是 2020 年 12 月 12 日,与今天的时间间隔为 18 天。在该月总共消费了 2 次,总共消费金额是 2021 元。
用户小王最近一次消费时间是 2020 年 12 月 28 日,与今天的时间间隔为 2 天。在该月总共消费了 5 次,总共消费金额是 10000 元。
我们可以得到两个用户的 R、F、M 值,如下表所示:

.3.2 根据 RFM 的阈值,对用户进行分类
首先,我们了解一下什么叫阈值。
阈值,又叫临界值,是指一个效应能够产生的最低值或最高值。
比如日常生活中,煮开水会有一个“沸点”。当温度低于“沸点”时水还没煮开,当温度高于这个“沸点”时,水就煮沸腾了。
这里用来区分温度高低的“沸点”,就可以理解为阈值。
而在案例中,对 RFM 各值的高低值进行标记前,需要我们获得 RFM 各值的阈值。
获得阈值,可以对 RFM 各值采取分区域评分,再计算各值平均数的方式,该方式会分为三个步骤:
1)给 R、F、M 各值按价值划分打分区间
这里需要注意的是,我们不是按指标的数值大小打分,而是对指标的价值打分。像最近一次消费时间间隔(R),消费时间间隔最近,即 R 值越小,用户的价值越高。
如何定义打分的范围,需要结合具体的业务来调整。由于这里是举例子来说明,所以我假设 R、F、M 各值按价值从小到大分为 1~5 分,其打分规则如下表:
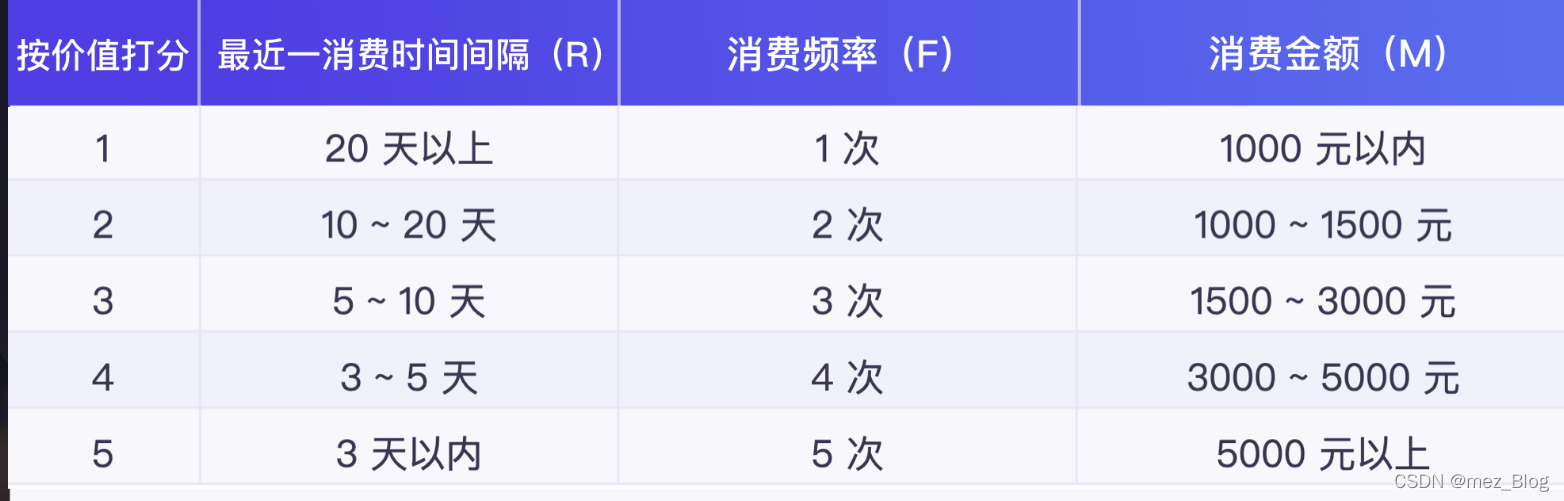
根据打分规则表,给两个用户的 RFM 值进行打分。

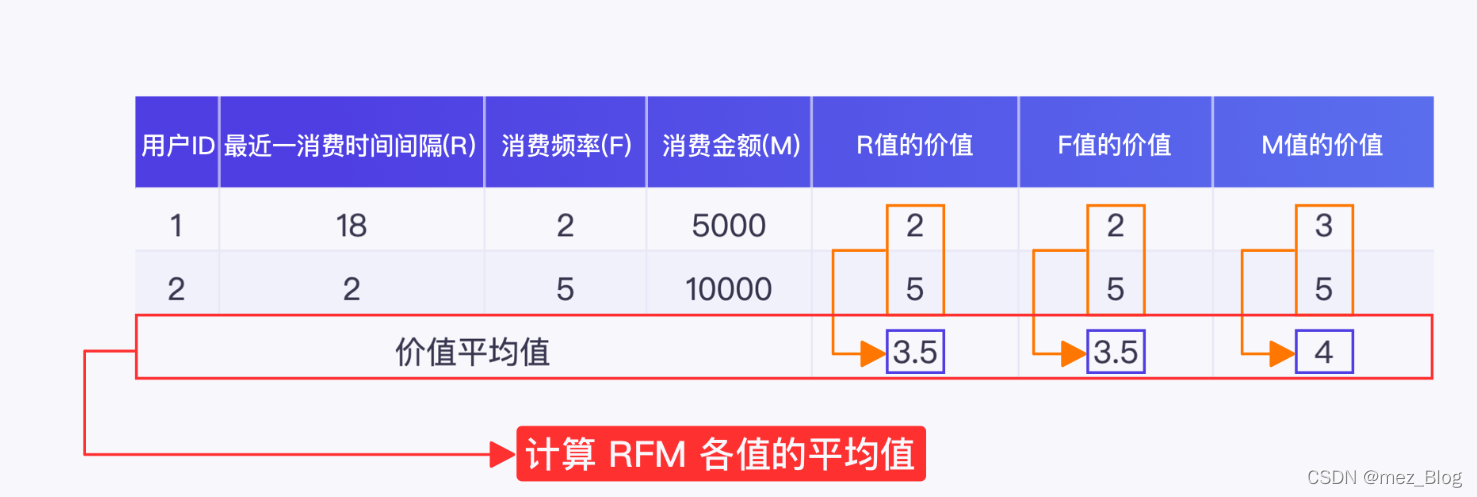
2)计算价值的平均值
打完分数后,分别计算 R、F、M 各打分值的平均值,结果如下:
3)用户分类
最后,我们将两个用户的 RFM 值与各值的平均值进行对比。
如果一行里的 R 值打分大于平均值,就标记该行的 R 值标记为“高”,反之标记为“低”。F、M 值亦是同理。
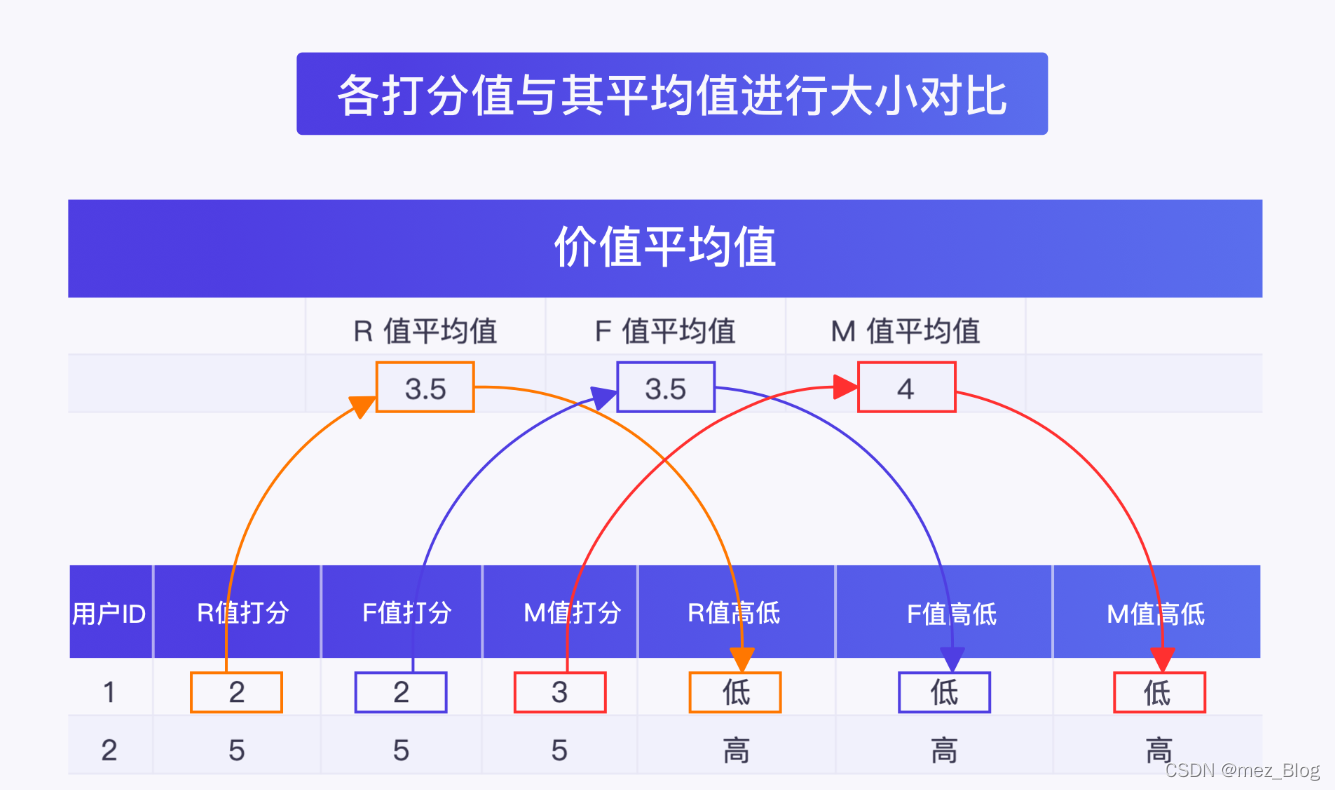
再将标记好的 RFM 高低值与用户分类规则表进行对比,可以得出用户属于哪种类别。
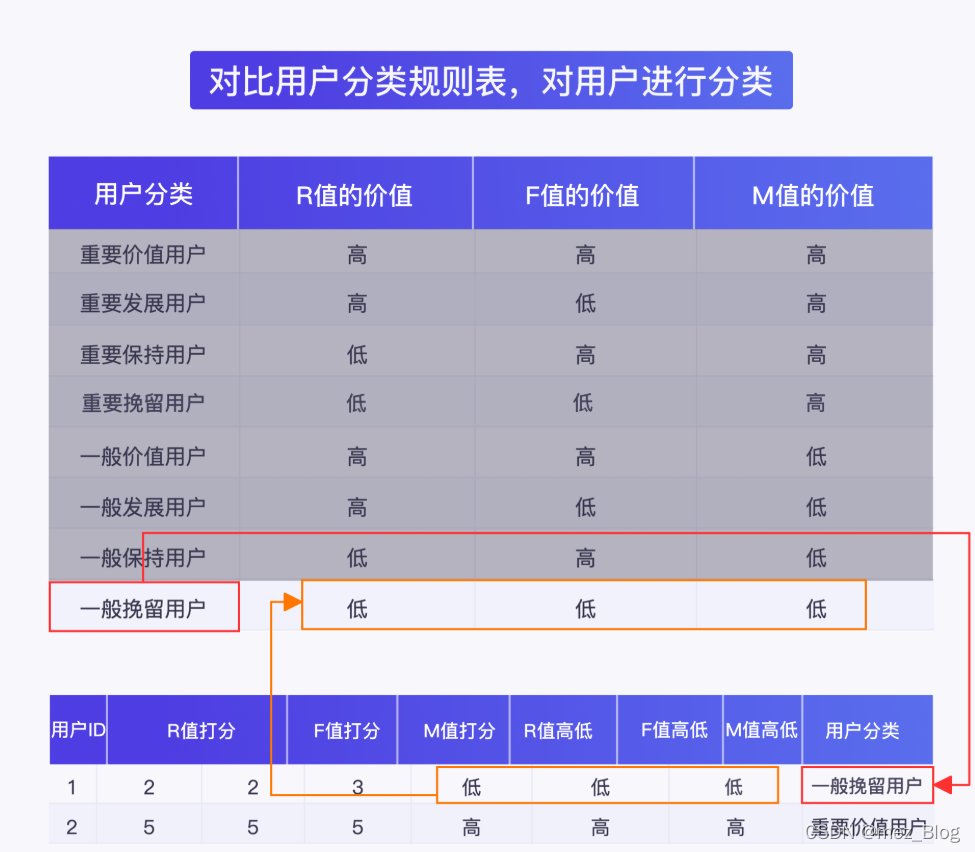
至此,我们学习完 RFM 模型将用户进行分类的操作。你可以查看下图,回顾 RFM 模型的构建流程。
在构建 RFM 模型的过程中,有几个注意事项:
1)现实业务,不一定有完整的 RFM 数据,需要通过计算或变换。比如上方的 R 值,我们需要确定一个时间点,并计算该时间点与用户最近一次消费时间才能得到最小时间间隔。
2)划分 RFM 的“高低”值,关键是找到划分的阈值。分析目标的不同,所选择的分析方法也可能不同。
上面的例子中,我们为 RFM 各值进行分区域评分,再计算各评分值的平均值来得到阈值。
而在数据量大的情况下,其实我们也可以通过 R、F、M 各值的原始数据,直接计算平均数或中位数的方式来获得阈值,计算起来也相对简单。
只是选择计算平均数来获得阈值的方式,它有个缺点就是:容易受到极值的影响,无法根据业务需求人为控制。
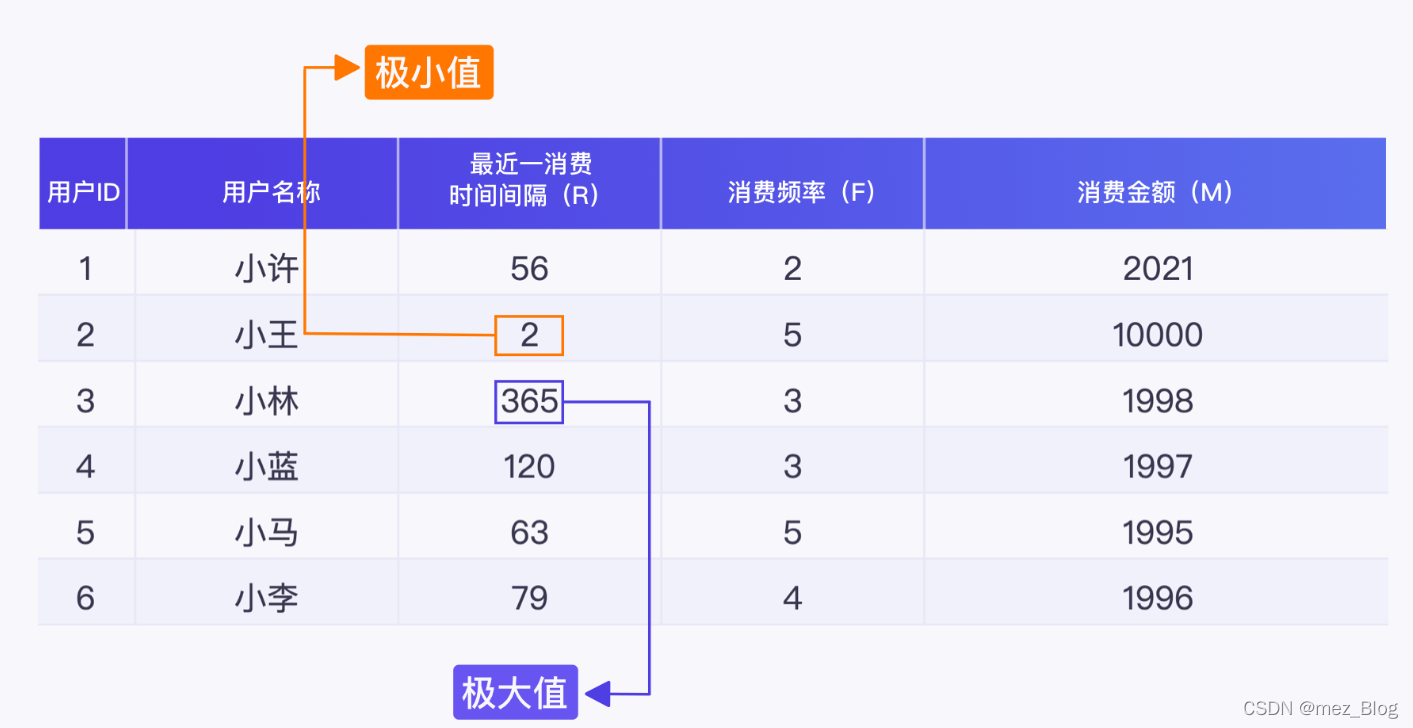
这样得到的阈值对 RFM 值进行高低档的标记,会给后面分析得到的用户分类带来误差。
为了不受到极值的影响,可以选择计算中位数来获得阈值。
但中位数也有一个缺点就是:容易受到数据分布的密集程度所影响,无法对分布密集的数据进行深入分析。
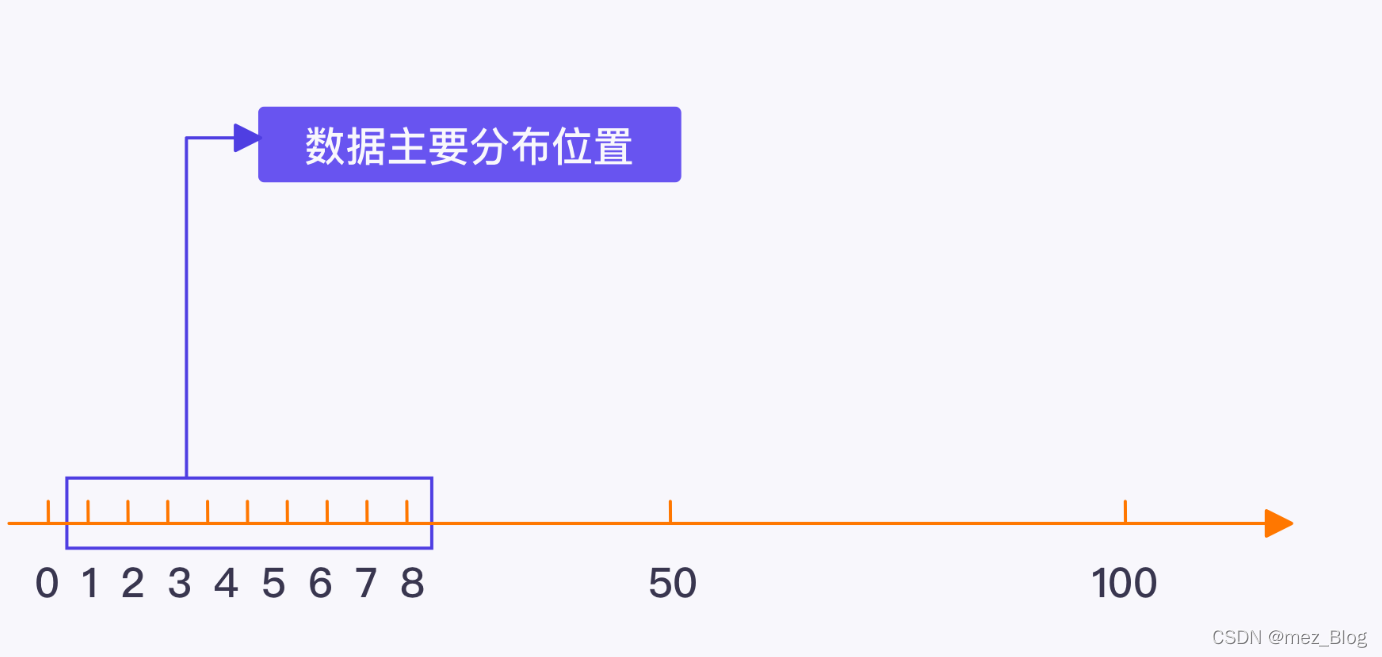
由此得出来的结果,可能也会影响到用户的分类。
因此,如果只是简单计算阈值,可以采取平均数或者中位数等方法。
而如果想不受数据分布密度的影响,并根据业务需求和资源进行调整,可以选择分区域评分,再计算平均值的分析方法;
5. 总结
基础知识
1)read_excel(io, sheet_name=0):读取 Excel 文件类型的数据;
2)to_excel(excel_writer, sheet_name='Sheet1', index=True):将数据写入到 Excel 类型的文件;
3)astype(dtype):转换数据的类型;
4)replace(to_replace):批量替换数据。
RFM 模型
1)RFM 模型的概念
a. R:最近一次消费时间间隔;
b. F:消费频率;
c. M:消费金额。
2)RFM 模型的作用:多用于精细化运营,了解用户分布情况。
3)RFM 模型的构建流程
a. 获取含有 RFM 的用户数据;
b. 根据 RFM 的阈值,对用户进行分类。

智能推荐
EasyDarwin开源流媒体云平台之EasyRMS录播服务器功能设计_开源录播系统-程序员宅基地
文章浏览阅读3.6k次。需求背景EasyDarwin开发团队维护EasyDarwin开源流媒体服务器也已经很多年了,之前也陆陆续续尝试过很多种服务端录像的方案,有:在EasyDarwin中直接解析收到的RTP包,重新组包录像;也有:在EasyDarwin中新增一个RecordModule,再以RTSPClient的方式请求127.0.0.1自己的直播流录像,但这些始终都没有成气候;我们的想法是能够让整套EasyDarwin_开源录播系统
oracle Plsql 执行update或者delete时卡死问题解决办法_oracle delete update 锁表问题-程序员宅基地
文章浏览阅读1.1w次。今天碰到一个执行语句等了半天没有执行:delete table XXX where ......,但是在select 的时候没问题。后来发现是在执行select * from XXX for update 的时候没有commit,oracle将该记录锁住了。可以通过以下办法解决: 先查询锁定记录 Sql代码 SELECT s.sid, s.seri_oracle delete update 锁表问题
Xcode Undefined symbols 错误_xcode undefined symbols:-程序员宅基地
文章浏览阅读3.4k次。报错信息error:Undefined symbol: typeinfo for sdk::IConfigUndefined symbol: vtable for sdk::IConfig具体信息:Undefined symbols for architecture x86_64: "typeinfo for sdk::IConfig", referenced from: typeinfo for sdk::ConfigImpl in sdk.a(config_impl.o) _xcode undefined symbols:
项目05(Mysql升级07Mysql5.7.32升级到Mysql8.0.22)_mysql8.0.26 升级32-程序员宅基地
文章浏览阅读249次。背景《承接上文,项目05(Mysql升级06Mysql5.6.51升级到Mysql5.7.32)》,写在前面需要(考虑)检查和测试的层面很多,不限于以下内容。参考文档https://dev.mysql.com/doc/refman/8.0/en/upgrade-prerequisites.htmllink推荐阅读以上链接,因为对应以下问题,有详细的建议。官方文档:不得存在以下问题:0.不得有使用过时数据类型或功能的表。不支持就地升级到MySQL 8.0,如果表包含在预5.6.4格_mysql8.0.26 升级32
高通编译8155源码环境搭建_高通8155 qnx 源码-程序员宅基地
文章浏览阅读3.7k次。一.安装基本环境工具:1.安装git工具sudo apt install wget g++ git2.检查并安装java等环境工具2.1、执行下面安装命令#!/bin/bashsudoapt-get-yinstall--upgraderarunrarsudoapt-get-yinstall--upgradepython-pippython3-pip#aliyunsudoapt-get-yinstall--upgradeopenjdk..._高通8155 qnx 源码
firebase 与谷歌_Firebase的好与不好-程序员宅基地
文章浏览阅读461次。firebase 与谷歌 大多数开发人员都听说过Google的Firebase产品。 这就是Google所说的“ 移动平台,可帮助您快速开发高质量的应用程序并发展业务。 ”。 它基本上是大多数开发人员在构建应用程序时所需的一组工具。 在本文中,我将介绍这些工具,并指出您选择使用Firebase时需要了解的所有内容。 在开始之前,我需要说的是,我不会详细介绍Firebase提供的所有工具。 我..._firsebase 与 google
随便推点
k8s挂载目录_kubernetes(k8s)的pod使用统一的配置文件configmap挂载-程序员宅基地
文章浏览阅读1.2k次。在容器化应用中,每个环境都要独立的打一个镜像再给镜像一个特有的tag,这很麻烦,这就要用到k8s原生的配置中心configMap就是用解决这个问题的。使用configMap部署应用。这里使用nginx来做示例,简单粗暴。直接用vim常见nginx的配置文件,用命令导入进去kubectl create cm nginx.conf --from-file=/home/nginx.conf然后查看kub..._pod mount目录会自动创建吗
java计算机毕业设计springcloud+vue基于微服务的分布式新生报到系统_关于spring cloud的参考文献有啥-程序员宅基地
文章浏览阅读169次。随着互联网技术的发发展,计算机技术广泛应用在人们的生活中,逐渐成为日常工作、生活不可或缺的工具,高校各种管理系统层出不穷。高校作为学习知识和技术的高等学府,信息技术更加的成熟,为新生报到管理开发必要的系统,能够有效的提升管理效率。一直以来,新生报到一直没有进行系统化的管理,学生无法准确查询学院信息,高校也无法记录新生报名情况,由此提出开发基于微服务的分布式新生报到系统,管理报名信息,学生可以在线查询报名状态,节省时间,提高效率。_关于spring cloud的参考文献有啥
VB.net学习笔记(十五)继承与多接口练习_vb.net 继承多个接口-程序员宅基地
文章浏览阅读3.2k次。Public MustInherit Class Contact '只能作基类且不能实例化 Private mID As Guid = Guid.NewGuid Private mName As String Public Property ID() As Guid Get Return mID End Get_vb.net 继承多个接口
【Nexus3】使用-Nexus3批量上传jar包 artifact upload_nexus3 批量上传jar包 java代码-程序员宅基地
文章浏览阅读1.7k次。1.美图# 2.概述因为要上传我的所有仓库的包,希望nexus中已有的包,我不覆盖,没有的添加。所以想批量上传jar。3.方案1-脚本批量上传PS:nexus3.x版本只能通过脚本上传3.1 批量放入jar在mac目录下,新建一个文件夹repo,批量放入我们需要的本地库文件夹,并对文件夹授权(base) lcc@lcc nexus-3.22.0-02$ mkdir repo2..._nexus3 批量上传jar包 java代码
关于去隔行的一些概念_mipi去隔行-程序员宅基地
文章浏览阅读6.6k次,点赞6次,收藏30次。本文转自http://blog.csdn.net/charleslei/article/details/486519531、什么是场在介绍Deinterlacer去隔行处理的方法之前,我们有必要提一下关于交错场和去隔行处理的基本知识。那么什么是场呢,场存在于隔行扫描记录的视频中,隔行扫描视频的每帧画面均包含两个场,每一个场又分别含有该帧画面的奇数行扫描线或偶数行扫描线信息,_mipi去隔行
ABAP自定义Search help_abap 自定义 search help-程序员宅基地
文章浏览阅读1.7k次。DATA L_ENDDA TYPE SY-DATUM. IF P_DATE IS INITIAL. CONCATENATE SY-DATUM(4) '1231' INTO L_ENDDA. ELSE. CONCATENATE P_DATE(4) '1231' INTO L_ENDDA. ENDIF. DATA: LV_RESET(1) TY_abap 自定义 search help