【Erlang】学习笔记-erlang基础语法-程序员宅基地
一、关于erlang
erlang是函数式编程语言,最初主要用在电信软件开发,他是面向并发编程的,和主流语言相比,主流语言并不能很好的利用多核CPU的资源,采取加锁的方式使得编程易出错,且锁也是耗资源的。学习erlang的过程中,发现erlang和主流语言的语法和思想差别很大,可能并不容易上手,但是作为一个程序员,越不容易才越有意思对不对?先从基本语法学起吧。
二、基本语法部分
2.1 erlang shell
erlang是在虚拟机上运行的,需要安装erlang环境,Windows和Linux下都可以安装,教程网上很多,就不记录了。Windows下安装完成后,在命令行输入erl进入erlang shell,可以开始执行erlang语句。
2.2 从简单语句理解语法
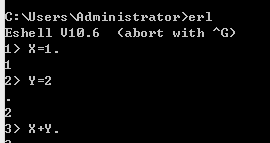
1>每条语句执行需要以点号结尾;
2>变量必须以大写字母或者下划线开头;
3>变量赋值后不能更改,声明未赋值的变量称为自由变量;
4>"="等于符号表示模式匹配,而非赋值。
5>原子是已小写字母开头的字符,或者单引号括起来的字符,原子的值就是原子本身,函数名就是个原子;
6>erlang数据计算不会溢出,没有范围限制;
7>除法结果:
/ 永远返回浮点数
div 返回除的整数
2.3 内置的数据结构
2.3.1元组
元组类似于struct,一般以原子作为标识,P={point,1,2},元组可以嵌套。
1>提取元组中的数据
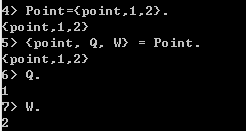
使用模式匹配符=,将Point变量的数据匹配到了Q和W两个变量
2>将元组转化为列表
![]()
将元组Point转化为有三个数据的一个列表。
3>访问元组中的指定数据
![]()
返回了元组Point中第三个数据。
4>在现有元组基础上改变其中某个数据得到一个新的元组
![]()
把Point元组的第三个数据改成了5,返回了新的元组{point,1,5}。
5>得到元组的数据个数
![]()
2.3.2 列表
列表存储数目可变的数据,用[]括起来,列表中元素类型可不同,列表的第一个元素叫列头,其他的部分叫列尾,用 | 分割列头和列尾,行为类似于栈。
1>提取列表元素
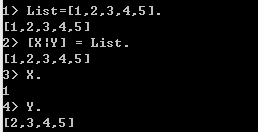
使用模式匹配和 | 进行提取,也可以通过这种方式向list中插入元素。
2> list几个简单操作
5> length(List). %%返回list数据个数
5
6> is_list(List). %%判断是否是列表
true
7> list_to_binary(List). %%返回转化为二进制后的list
<<1,2,3,4,5>>
8> list_to_bitstring(List). %%返回转化为bitstring的list
<<1,2,3,4,5>>
9> hd(List). %%取到列表头
1
10> tl(List). %%取到列表尾
[2,3,4,5]3> lists库常用函数
lists:foreach(Fun, List). ->ok
lists:foreach(fun(X) -> io:format("~p",[X+1]) end, List).
23456ok对于List这个列表中的每一个元素执行Fun函数,上面是把[1,2,3,4,5]列表中的元素加一输出出来。
lists:foldl(Fun,Acc0,List) ->Acc1
lists:foldl(fun(X,Sum) -> X+ Sum end, 0, List).
15遍历List中的元素执行fun函数,每次把结果再传给下一次的Sum,完成累加,最后将累加结果返回。
lists:flatten(DeepList) -> List
lists:flatten([[1],[1,2,3],[4,[5,6],7]] ).
[1,1,2,3,4,5,6,7]将一个复杂的嵌套的llist,扁平化尾简单list。
lists:reverse(List1) -> List2
lists:reverse(List).
[5,4,3,2,1]反转列表。
lists:member(Elem, List) -> boolean()
lists:member(5,List).
true
lists:member(6,List).
false查找Elem是否在List中存在。
lists:merge(List1, List2) -> List3
List1和List2分别是一个列表,这个函数的功能是将这两个列表合并成一个列表。
lists:all(Pred, List) -> boolean()
如果List中的每个元素作为Pred函数的参数执行,结果都返回true,那么all函数返回true,否则返回false。
lists:keystore(Key, N, TupleList1, NewTuple) -> TupleList2
替换list中touple的N位置为Key的tuple,返回新的TupleList。没找不到将NewTuple附加到原有TupleList后面并返回。
lists:keystore(apple,1,[{pear,1,1},{banana,2,2},{apple,3,3},{apple,4,4}],{apple,5,5}).
[{pear,1,1},
{banana,2,2},
{apple,5,5},
{apple,4,4}]lists:split(N, List1) -> {List2, List3}
将List1分成List2和List3
其中List2包括List1的前N个元素,List3包含剩余的。
lists:foldr(Fun, Acc0, List) -> Acc1
foldr这个函数和foldl用法相似,Fun执行时,遍历List的顺序从后往前。
lists:concat(List) -> string()
list转字符串
lists:concat([1,avc,'/',';',ww]).
"1avc/;ww"lists:keysort(N, TupleList1) -> TupleList2
对TupleList1中的Tuple按照Touple的第N个元素进行排序,然后返回一个新的顺序的TupleList。
lists:ukeymerge(N, TupleList1, TupleList2) -> TupleList3
将TupleList1和TupleList2合并,合并的规则是按照元组的第N个元素,如果第N个元素有相同的,那么保留TupleList1中的,删除TupleList2中的。
lists:sublist(List1, Len) -> List2
返回从第一个元素到第Len个元素的列表,这个Len大于List1的长度时,返回全部。
其他lists库包含的函数:lists和其他erlang库
效率比较高的lists函数
lists函数有一些已经被优化成bif函数(erlang内建函数)。有以下几个:
lists:member/2, lists:reverse/2, lists:keymember/3, lists:keysearch/3, lists:keyfind/3
当list元素多时效率低的lists函数
1>lists:foldr/3
非尾递归实现,替换方案:lists:reverse/1后lists:foldl/3。
2>lists:append/2
实现为append(L1, L2) -> L1 ++ L2. 其中,L1 ++ L2会遍历 L1,如果一定要使用就把短的list放左边
3>lists:subtract/2
实现为subtract(L1, L2) -> L1 -- L2. 其中,--的复杂度和它的操作数的长度的乘积成正比
4>lists:flatten/1
这个是list扁平化函数,这个存在性能开销
lists:map/2, lists:flatmap/2, lists:zip/2, lists:delete/2, lists:sublist/2, lists:sublist/3, lists:takewhile/2, lists:concat/1
lists:flatten/1, lists:keydelete/3, lists:keystore/4, lists:zf/2, lists:mapfoldl/3, lists:mapfoldr/3, lists:foldr/3
4>列表推导式
列表推导式类似于数学中的集合,表达形式:[X *2| | X <- [1,2,3],X rem 2 =:= 0].
2.4 模块
模块是有名字的文件,包含一组函数,把处理类似事情的函数放在同一个模块中,模块名和文件名必须一致。
1> 定义模块中可导出(可被其他模块访问)的函数:-export([Functionname/参数数量])
2>函数:FunctionName(Args)->Body. Body由一个或者多个用逗号分隔的erlang表达式组成,自动返回最后一个表达式的执行结果,无需return关键字
3>注释:只能单行,%开头
4>定义宏:和define类似,用来定义简短的函数和常量,eg:-define(HOUR,3600). 使用HOUR这个宏表示3600,编译前HOUR宏被替换成3600,函数宏:-define(sub(X,Y),X-Y). 宏调用:?sub(23,47);
-ifdef(DEBUGMODE).
-define(DEBUG(S),io:format("dbg: "++s)).
-else.
-define(DEBUG(S), ok).
-endif.5>元数据:模块名:module_info(),查看模块的各项元数据
6>环形依赖:避免环形依赖,A依赖了B,B不应该再依赖A。
7>运行一个模块需要先编译,编译结束后的文件结尾.beam
2.5 函数
其他语言里ifelse的表达在erlang里使用模式匹配,多个函数字句来实现,字句间用分号分隔,结束用实心点。
~号用来指示一个标记符,io:format函数格式化输出通过替换字符串中的标记符完成
卫语句:添加在函数头的语句,用于模式匹配,eg:old_enough(X) when X>= 16, X=<104 -> true;
if类似于卫语句,case...of的语法:
heh_fine() ->
if 1=:= 1-> works;
true -> always_does %%这是erlang if的else
end.
case...of
beach(X) ->
case X of
Pattern Guards -> ...
end.2.6 类型
erlang是 动态强类型,提供了一系列类型转换函数,命名typeA_to_typeB,eg:erlang:list_to_integer
提供了类型检测BIF,形如is_type,eg:is_binary/1
2.7 递归
递归终止的条件是一个子函数,返回值而不是继续调用函数,函数式编程没有循环,只有递归。
尾递归:使用一个变量保存递归过程中的中间结果,到最后一个元素的时候直接返回结果,需要提供一个参数只有一个的子函数用于返回
三、高阶函数
一个函数的参数是其他函数,则这个函数是高阶函数,调用时的传参方式:fun module:funname/arity
匿名函数,语法:fun(Args1) ->
Experssion1,Exp2,...,ExpN;
(Args2)->
Experssion1,Exp2,...,ExpN
end
函数作用域:存放所有变量对应值的地方,函数中任何地方都能访问,包括函数内的匿名函数,但是匿名函数中的变量在其所在的外部函数中不能访问。匿名函数一直持有所继承的作用域
过滤器:提取共同部分,调用时传入谓词(筛选条件)
折叠:把某个操作依次作用于列表每个元素,最后把所有元素归约成一个单一值。折叠是普遍适用的。
四、常用数据结构
4.1记录
定义一个机器人记录:-record(robot,{ name, type = sumething, hobbies, details=[]}). 创建记录实例:#robot{name="xxx",type=handmade,details=[]}. 记录是元组之上的语法糖,使用点号来访问记录中的值异常:
共享记录:-indlude("records.hrl"). 将记录定义在records.hrl文件
4.2 小数据量的存储结构
1、属性列表(形如[{key,value}]的元组列表),通过proplists模块处理属性列表,没有插入函数,一般只用来存储配置
2、有序字典:orddict模块,适合存储小于75个数据量的情况。
4.3 大数据量的存储结构
1、字典:dict模块,接口和有序字典一样
2、通用平衡树:gb_trees模块,保留了元素顺序,如果需要按顺序访问,合适,分为智能模式和简单模式。
4.4 集合:
集合是值唯一的一组元素,有四个集合处理模块:ordsets(有序集合,主要实现小集合,最慢最简单的集合),sets(接口和ordsets一样,适用于大一些的数据规模,擅长读密集型处理),gb_sets(非读操作更快,控制手段更多,分智能模式和简单模式),sofs(有序列表实现,可在集合族和有向图之间进行双向转换),
4.5 有向图:
两个模块:digraph(实现了有向图的构造和修改),digraph_utils(实现了图的后序和前序遍历等)
4.6 队列
queue模块,使用了两个列表(栈)实现的。
五、并发编程
并发:有许多独立运行的actor,但并不要求它们同时运行
并行:多个actor同时运行
erlang采取的是基于异步消息的轻进程,在erlang虚拟机上,创建一个erlang进程需要300个字的内存空间,创建时间几微秒,每个核启动一个线程充当调度器。
erlang进程就是一个函数,启动一个新进程使用spawn(函数名),参数是一个函数,spawn返回进程标识符pid,pid可作为地址进行进程间通信。
发送消息,操作符"!"也称bang符号,!左边是一个pid,右边可以是任意erlang数据项,数据被发给左边pid的进程。消息按照接收顺序会被放进接收进程的邮箱中,flush()命令查看。
接收消息:receive表达式,收到消息后进程处理完就退出了,所以需要递归调用自己
5.1 多重处理
1、定义进程状态:借助递归函数,进程的状态保存到递归函数的参数中
2、隐藏消息实现:使用函数来处理消息的接收和发送
3、超时处理(防止死锁)属于receive语句中的一部分,Delay单位是毫秒,超时后没有收到和Match模式匹配的消息,会执行after部分:
receive
Match -> Expression1
after Delay ->
Expersion2
end.4.选择性接收:通过嵌套调用对接收到的消息进行优先级排序,但是如果无用的消息太多会导致性能下降
5、邮箱风险的解决:确保有匹配不到的消息的处理,打日志,方便bug调试
5.2 多进程中高效的处理错误
1、链接:是两个进程之间的特殊关系,一个进程意外死亡时,与之有链接关系的进程也会死亡,阻止错误蔓延,建立链接函数:link/1,参数是pid,建立当前进程和pid的链接,为防止进程在链接建立成功之前就死亡了,提供了spawn_link函数,把创建进程和建立链接封装成了一个原子操作
2、重启进程:系统进程可以检查是否有进程死亡并重启死亡进程,process_flag(trap_exit,true)实现erlang进程转系统进程。
3、监控器:特殊的链接,监控器是单向的,两个进程间可设置多个监控器,监控器可以叠加,每个监控器有自己的标识,可以单独的移除,创建监控器:erlang:monitor/2,第一个参数永远是原子process,第二个参数是进程pid。监控进程死活,创建进程同时监控进程:spawn_monitor
4、给进程命名,方便在进程死亡后重启:erlang:register(Name,Pid)。进程死亡则自动失去名字。
最后做做小练习
1、用erlang实现一个简单的RPN计算器,输入一个list,输出计算结果:
-module(calc).
-export([rpn/1]).
rpn(L) when is_list(L) ->
[Res] = lists:foldl(fun rpn/2, [], string:tokens(L," ")),
Res.
rpn("+", [N1,N2|S]) -> [N2+N1|S];
rpn("-", [N1,N2|S]) -> [N2-N1|S];
rpn("*", [N1,N2|S]) -> [N2*N1|S];
rpn("/", [N1,N2|S]) -> [N2/N1|S];
rpn(X, Stack) -> [read(X)|Stack].
read(N) ->
case string:to_float(N) of
{error,no_float} -> list_to_integer(N);
{F,_} ->F
end.2、erlang实现的事件提醒器
分为两部分完成,事件服务器和事件,当客户端向事件服务器请求新增一个事件,服务器创建事件进程,事件进程在事件时间到了的时候通知事件服务器,事件服务器转发给客户端。
要注意的几个点:
事件服务器要监控订阅的客户端,已经挂掉的客户端不需要再关注
客户端可以取消事件,所以事件服务器需要可以杀掉事件进程
erlang超时值最大只能是50天,为了支持能够设置超过50天的事件,需要自己处理一下时间。
事件代码:
-module(event).
-compile(export_all).
-record(state, {server, name ="", to_go=0}).
start(EventName, Delay) ->
spawn(?MODULE, init, [self(), EventName, Delay]).
start_link(EventName, Delay) ->
spawn_link(?MODULE, init, [self(),EventName,Delay]).
loop(S = #state{server=Server,to_go=[T|Next]}) ->
receive
{Server, Ref, cancel} ->
Server ! {Ref, ok}
after T*1000 ->
if Next =:= [] ->
Server ! {done, S#state.name};
Next =/= [] ->
loop(S#state{to_go=Next})
end
end.
init(Server, EventName, DateTime) ->
loop(#state{server=Server, name=EventName, to_go=normalize(DateTime)}).
cancel(Pid) ->
Ref = erlang:monitor(process, Pid),
Pid ! {self(), Ref, cancel},
receive
{Ref, ok} ->
erlang:demonitor(Ref, [flush]),
ok;
{'DOWN', Ref, process, Pid, _Reason} ->
ok
end.
normalize(N) ->
Limit = 49 * 24 * 60 * 60,
[N rem Limit | lists:duplicate(N div Limit, Limit)].
time_to_go(TimeOut={
{_,_,_},{_,_,_}}) ->
Now = calendar:local_time(),
ToGo = calendar:datatime_to_gregorian_seconds(TimeOut) -
calendar:datatime_to_gregorian_seconds(Now),
Secs = if ToGo > 0 -> ToGo;
ToGo =< 0 -> 0
end,
normalize(Secs).事件服务器代码:
-module(evserv).
-compile(export_all).
-record(state, {events, clients}). %%记录事件和pid
-record(event, {name="", description="", pid, timeout={
{1970,1,1},{0,0,0}}}).
start() ->
register(?MODULE, Pid=spawn(?MODULE, init,[])),
Pid.
start_link() ->
register(?MODULE, Pid = spawn_link(?MODULE,init,[])),
Pid.
terminate() ->
?MODULE ! shutdown.
init() ->
loop(#state{events = orddict:new(), clients = orddict:new()}).
loop(S = #state{}) ->
receive
{Pid, MsgRef, {subscribe, Client}} -> %%订阅事件
Ref = erlang:monitor(process, Client), %%监控订阅的客户端
NewClients = orddict:store(Ref, Client, S#state.clients),%%使用有序字典定义客户端
Pid ! {MsgRef, ok},
loop(S#state{clients=NewClients});
{Pid, MsgRef, {add, Name, Description, TimeOut}} -> %%新增事件
case valid_datetime(TimeOut) of
true ->
EventPid = event:start_link(Name, TimeOut),
NewEvents = orddict:store(Name, #event{name=Name, description=Description,pid=EventPid,timeout=TimeOut},
S#state.events),
Pid ! {MsgRef, ok}, %%MsgRef是标志这是这条消息对应的返回消息
loop(S#state{events=NewEvents});
false ->
Pid ! {MsgRef, {error, bad_timeout}},
loop(S)
end;
{Pid, MsgRef, {cancel, Name}} -> %%取消事件
Events = case orddict:find(Name, S#state.events) of
{ok, E} ->
event:cancel(E#event.pid),
orddict:erase(Name, S#state.events);
error->
S#state.events
end,
Pid ! {MsgRef, ok},
loop(S#state{events=Events});
{done,Name} -> %%事件进程发来的事件时间到了的通知
case orddict:find(Name, S#state.events) of
{ok, E} ->
send_to_clients({done, E#event.name, E#event.description},S#state.clients),
NewEvents = orddict:erase(Name, S#state.events),
loop(S#state{events=NewEvents});
error ->
loop(S)
end;
shutdown -> %%服务器关机
exit(shutdown);
{'DOWN', Ref, process, _Pid, _Reason} -> %%客户进程死亡
loop(S#state{clients=orddict:erase(Ref, S#state.clients)});
code_change -> %%热更新
?MODULE:loop(S);
Unknown ->
io:format("Unknown message:~p~n",[Unknown]),
loop(S)
end.
send_to_clients(Msg, ClientDict) ->
orddict:map(fun(_Ref, Pid) -> Pid ! Msg end, ClientDict).
valid_datetime({Date, Time}) ->
try
caledar:valid_date(Date) andalso valid_time(Time)
catch
error:function_clause ->
false
end;
valid_datetime(_) ->
false.
valid_time({H,M,S}) -> valid_time(H,M,S).
valid_time(H,M,S) when H>= 0, H < 24,
M>=0, M < 60,
S>=0, s<60 ->true;
valid_time(_,_,_) ->false.
%%提供给客户端的订阅消息接口
subscribe(Pid) ->
Ref = erlang:monitor(process, whereis(?MODULE)),
?MODULE ! {self(), Ref, {subscribe,Pid}},
receive
{Ref, ok} ->
{ok, Ref};
{'DOWN', Ref, process, _Pid, Reason} ->
{error, Reason}
after 5000 ->
{error, timeout}
end.
add_event(Name, Description, TimeOut) ->
Ref = make_ref(),
?MODULE ! {self(), Ref, {add, Name, Description, TimeOut}},
receive
{Ref, Msg} -> Msg
after 5000 ->
{error, timeout}
end.
cancel(Name) ->
Ref = make_ref(),
?MODULE ! {self(), Ref, {cancel, Name}},
receive
{Ref, ok} -> ok
after 5000 ->
{error, timeout}
end.
listen(Delay) ->
receive
M = {done, _Name, _Description} ->
[M | listen(0)]
after Delay*1000 ->
[]
end.
智能推荐
SAP FIORI开发入门-徐春波-专题视频课程-程序员宅基地
文章浏览阅读1.4k次,点赞3次,收藏8次。【课程目标】打造一个简单实用的 SAP FIORI 入门开发课程,帮助广大 SAP 技术人员或者希望进入 SAP 技术领域的人打开一扇门。【课程形式】视频教程 + PDF 参考资料【学习门槛】零门槛,无需任何额外知识【作者微信】eksbobo【如何入群】使用购买课程的 ID 作为请求信息,发送到作者的微信添加好友,作者会把您拉入到这门课程的微信群中。..._sap fiori开发视频教程--由浅入深学习fiori开发
启发式合并(dsu),树上启发式合并(dsu on tree)总结-程序员宅基地
文章浏览阅读232次。启发式合并(dsu),树上启发式合并(dsu on tree)总结_启发式合并
工具方法:一次性将对象中所有null字段,转为空字符串_null值转换为空字符串-程序员宅基地
文章浏览阅读9.1k次,点赞12次,收藏30次。当我们的 Java 对象在响应前端,或者在做数据导出的时候,我们并不希望将对象中为 null 的属性值直接返回给前端,不然显示或导出的就是一个 null ,这样对用户不是很友好。如果我们一个个字段的去处理,这样不但增加了人力,而且使得代码中逻辑冗余,显得不够优雅。于是下面我写了一个通用方法:将对象中的 String 类型属性的null 值转换为空字符串的方法,具体代码如下:/** * 把对象中的 String 类型的null字段,转换为空字符串 * * @param <.._null值转换为空字符串
2023最新版kali安装教程_kali下载-程序员宅基地
文章浏览阅读1.7w次,点赞45次,收藏202次。2023最新版kali安装教程打开kali官网(https://www.kali.org/),下载kali镜像_kali下载
nest.js实战之集成sentry_sentry nestjs-程序员宅基地
文章浏览阅读581次。1.简介Sentry API用于将事件提交给Sentry收集器以及导出和管理数据。报告和Web API分别进行了版本控制。2.安装仓库:https://github.com/ntegral/nestjs-sentrynpm install --save @ntegral/nestjs-sentry @sentry/node@ntegral/nestjs-sentry:nestjs的sentry模块,提供了一些可注入服务 @sentry/node:sentry..._sentry nestjs
2024最全前端面试系列(CSS)(盒模型、flex)(1),前端面试题刷题-程序员宅基地
文章浏览阅读814次,点赞24次,收藏27次。定位以外的第一个父元素进行定位。元素的位置通过 “left”, “top”, “right” 以及 “bottom” 属性进行规定。没有定位,元素出现在正常的流中(忽略 top, bottom, left, right 或者 z-index 声明)。元素的位置通过 “left”, “top”, “right” 以及 “bottom” 属性进行规定。大前端和全栈是以后前端的一个趋势,懂后端的前端,懂各端的前端更加具有竞争力,以后可以往这个方向靠拢。生成绝对定位的元素,相对于。生成相对定位的元素,相对于其。
随便推点
携程 Apollo 配置中心 | 学习笔记 序章_apollo分布式配置黑马学习笔记-程序员宅基地
文章浏览阅读7.4k次,点赞11次,收藏45次。Apollo 携程Apollo配置中心目录导航 携程 Apollo 配置中心 | 学习笔记(一) | Apollo配置中心简单介绍 携程 Apollo 配置中心 | 学习笔记(二) | Windows 系统搭建基于携程Apollo配置中心单机模式 携程 Apollo 配置中心 | 学习笔记(三) | 自..._apollo分布式配置黑马学习笔记
什么是人工智能(AI)?—— 你需要知道的三件事-程序员宅基地
文章浏览阅读1.1k次,点赞16次,收藏25次。人工智能 (AI) 是对人类智慧行为的仿真。它通常是设计用来感知环境、了解行为并采取行动的一台计算机或一个系统。想想自动驾驶汽车:此类 AI 驱动系统将机器学习和深度学习等 AI 算法集成到支持自动化技术的复杂环境。据麦肯锡预计,到 2030 年,AI 的全球经济价值将高达 13 万亿美元。这是因为在 AI 浪潮的影响下,几乎各行各业乃至每一个应用领域的工程环节都在转型。除了自动驾驶以外,AI 还广泛应用于以下领域:机器故障预测模型,告知何时需要进行机器保养;健康和传感器分析,如病患监护系统;
VueRouter(vue-router 路由)最全笔记,实战实用,通俗易懂_router及vue-router教程-程序员宅基地
文章浏览阅读1.8k次,点赞3次,收藏8次。VueRouter安装和使用vue-router安装模块化中使用使用vue-router的步骤使用history模式router-link重定向/默认路由点击事件跳转路由动态路由路由懒加载路由嵌套参数传递(一)路由元信息全局导航守卫前置全局后置钩子组件内守卫路由独享的守卫keep-alive注意URL:协议://主机:端口/路径?查询(query)所有的组件都继承自Vue类的原型打包:npm run buildredirect:[ˌriːdəˈrekt ] 重定向replace:没有返回箭头_router及vue-router教程
运维——1.网线接在家用无线路由器LAN口依然可以上网,什么原理_路由器为啥插lan口为什么还能上网-程序员宅基地
文章浏览阅读641次。这种连接方式实际上是将路由器作为一个普通的网络交换机来使用_路由器为啥插lan口为什么还能上网
element-ui的el-upload上传图片自定义请求和vue-quill-editor富文本结合使用_vue中使用el-upload自定义editor-程序员宅基地
文章浏览阅读293次。vue-quill-editor默认的图片插入方式,是直接将图片转成base64编码,这样的结果是整个富文本的html片段十分冗余。我们的服务器端接收的post的数据大小都是有限制的,这样的话导致提交失败,就算不提交失败,大量的数据存入数据库也不是好事。为了解决这个问题,我考虑了两个方案,换一个富文本编辑框框架,另一个是修改vue-quill-editor的框架代码。..._vue中使用el-upload自定义editor
HTML/CSS常见的三种水平居中方式(好文备忘)_htmlcss水平居中-程序员宅基地
文章浏览阅读125次。HTML/CSS常见的三种水平居中方式_htmlcss水平居中