深度学习论文: PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization-程序员宅基地
技术标签: Anomaly Detection python 深度学习 人工智能 Deep Learning Paper Reading
深度学习论文: PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization
PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization
PDF: https://arxiv.org/pdf/2011.08785.pdf
PyTorch代码: https://github.com/shanglianlm0525/CvPytorch
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
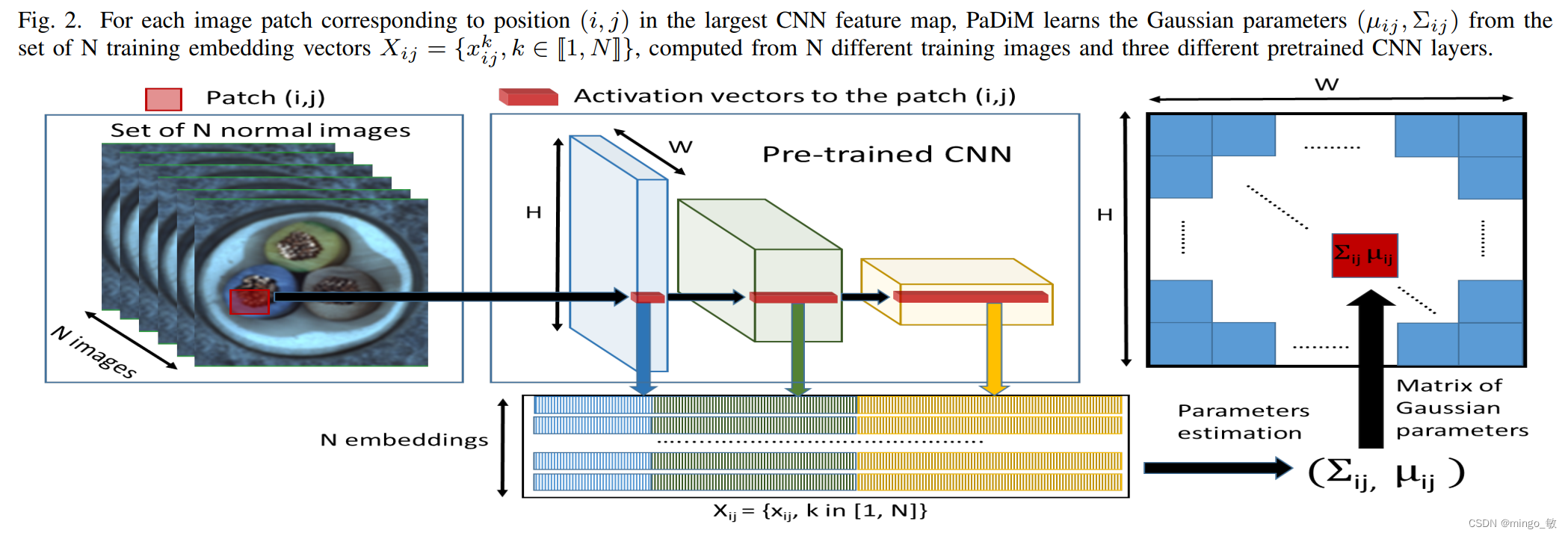
PaDiM 在单类学习中同时检测和定位图像中的异常,PaDiM利用一个预先训练好的卷积神经网络(CNN)进行patch嵌入,利用多元高斯分布得到正态类的概率表示。同时利用了CNN的不同语义级别之间的相关性来更好地定位异常。

2 Patch Distribution Modeling(PaDiM)
PaDiM是一种基于图像Patch的算法。它依赖于预先训练好的CNN功能提取器。 将图像分解为多个面片,并使用不同的特征提取层从每个面片中提取嵌入。 将不同层次的激活向量串联起来,得到包含不同语义层次和分辨率信息的嵌入向量。这有助于对细粒度和全局上下文进行编码。 然而,由于生成的嵌入向量可能携带冗余信息,因此使用随机选择来降低维数。 在整个训练批次中,为每个面片嵌入生成一个多元高斯分布。因此,对于训练图像集的每个面片,我们有不同的多元高斯分布。这些高斯分布表示为高斯参数矩阵。 在推理过程中,使用马氏距离对测试图像的每个面片位置进行评分。它使用训练期间为面片计算的协方差矩阵的逆矩阵。 马氏距离矩阵形成了异常图,分数越高表示异常区域。
3 PyTorch代码
# !/usr/bin/env python
# -- coding: utf-8 --
# @Time : 2023/6/2 15:07
# @Author : liumin
# @File : run_PaDiM.py
import random
from random import sample
import argparse
import numpy as np
import os
import pickle
from tqdm import tqdm
from collections import OrderedDict
from sklearn.metrics import roc_auc_score
from sklearn.metrics import roc_curve
from sklearn.metrics import precision_recall_curve
from sklearn.covariance import LedoitWolf
from scipy.spatial.distance import mahalanobis
from scipy.ndimage import gaussian_filter
from skimage import morphology
from skimage.segmentation import mark_boundaries
import matplotlib.pyplot as plt
import matplotlib
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision.models import wide_resnet50_2, resnet18
import os
# import tarfile
from PIL import Image
from tqdm import tqdm
# import urllib.request
import torch
from torch.utils.data import Dataset
from torchvision import transforms as T
random.seed(1024)
torch.manual_seed(1024)
torch.cuda.manual_seed_all(1024)
# URL = 'ftp://guest:[email protected]/mvtec_anomaly_detection/mvtec_anomaly_detection.tar.xz'
CLASS_NAMES = ['bottle', 'cable', 'capsule', 'carpet', 'grid',
'hazelnut', 'leather', 'metal_nut', 'pill', 'screw',
'tile', 'toothbrush', 'transistor', 'wood', 'zipper']
class MVTecDataset(Dataset):
def __init__(self, dataset_path='/home/liumin/data/mvtec_ad/', class_name='bottle', is_train=True,
resize=256, cropsize=224):
assert class_name in CLASS_NAMES, 'class_name: {}, should be in {}'.format(class_name, CLASS_NAMES)
self.dataset_path = dataset_path
self.class_name = class_name
self.is_train = is_train
self.resize = resize
self.cropsize = cropsize
# self.mvtec_folder_path = os.path.join(root_path, 'mvtec_anomaly_detection')
# download dataset if not exist
# self.download()
# load dataset
self.x, self.y, self.mask = self.load_dataset_folder()
# set transforms
self.transform_x = T.Compose([T.Resize(resize, Image.ANTIALIAS),
T.CenterCrop(cropsize),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])])
self.transform_mask = T.Compose([T.Resize(resize, Image.NEAREST),
T.CenterCrop(cropsize),
T.ToTensor()])
def __getitem__(self, idx):
x, y, mask = self.x[idx], self.y[idx], self.mask[idx]
x = Image.open(x).convert('RGB')
x = self.transform_x(x)
if y == 0:
mask = torch.zeros([1, self.cropsize, self.cropsize])
else:
mask = Image.open(mask)
mask = self.transform_mask(mask)
return x, y, mask
def __len__(self):
return len(self.x)
def load_dataset_folder(self):
phase = 'train' if self.is_train else 'test'
x, y, mask = [], [], []
img_dir = os.path.join(self.dataset_path, self.class_name, phase)
gt_dir = os.path.join(self.dataset_path, self.class_name, 'ground_truth')
img_types = sorted(os.listdir(img_dir))
for img_type in img_types:
# load images
img_type_dir = os.path.join(img_dir, img_type)
if not os.path.isdir(img_type_dir):
continue
img_fpath_list = sorted([os.path.join(img_type_dir, f)
for f in os.listdir(img_type_dir)
if f.endswith('.png')])
x.extend(img_fpath_list)
# load gt labels
if img_type == 'good':
y.extend([0] * len(img_fpath_list))
mask.extend([None] * len(img_fpath_list))
else:
y.extend([1] * len(img_fpath_list))
gt_type_dir = os.path.join(gt_dir, img_type)
img_fname_list = [os.path.splitext(os.path.basename(f))[0] for f in img_fpath_list]
gt_fpath_list = [os.path.join(gt_type_dir, img_fname + '_mask.png')
for img_fname in img_fname_list]
mask.extend(gt_fpath_list)
assert len(x) == len(y), 'number of x and y should be same'
return list(x), list(y), list(mask)
def denormalization(x):
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
x = (((x.transpose(1, 2, 0) * std) + mean) * 255.).astype(np.uint8)
return x
def embedding_concat(x, y):
B, C1, H1, W1 = x.size()
_, C2, H2, W2 = y.size()
s = int(H1 / H2)
x = F.unfold(x, kernel_size=s, dilation=1, stride=s)
x = x.view(B, C1, -1, H2, W2)
z = torch.zeros(B, C1 + C2, x.size(2), H2, W2)
for i in range(x.size(2)):
z[:, :, i, :, :] = torch.cat((x[:, :, i, :, :], y), 1)
z = z.view(B, -1, H2 * W2)
z = F.fold(z, kernel_size=s, output_size=(H1, W1), stride=s)
return z
def plot_fig(test_img, scores, gts, threshold, save_dir, class_name):
num = len(scores)
vmax = scores.max() * 255.
vmin = scores.min() * 255.
for i in range(num):
img = test_img[i]
img = denormalization(img)
gt = gts[i].transpose(1, 2, 0).squeeze()
heat_map = scores[i] * 255
mask = scores[i]
mask[mask > threshold] = 1
mask[mask <= threshold] = 0
kernel = morphology.disk(4)
mask = morphology.opening(mask, kernel)
mask *= 255
vis_img = mark_boundaries(img, mask, color=(1, 0, 0), mode='thick')
fig_img, ax_img = plt.subplots(1, 5, figsize=(12, 3))
fig_img.subplots_adjust(right=0.9)
norm = matplotlib.colors.Normalize(vmin=vmin, vmax=vmax)
for ax_i in ax_img:
ax_i.axes.xaxis.set_visible(False)
ax_i.axes.yaxis.set_visible(False)
ax_img[0].imshow(img)
ax_img[0].title.set_text('Image')
ax_img[1].imshow(gt, cmap='gray')
ax_img[1].title.set_text('GroundTruth')
ax = ax_img[2].imshow(heat_map, cmap='jet', norm=norm)
ax_img[2].imshow(img, cmap='gray', interpolation='none')
ax_img[2].imshow(heat_map, cmap='jet', alpha=0.5, interpolation='none')
ax_img[2].title.set_text('Predicted heat map')
ax_img[3].imshow(mask, cmap='gray')
ax_img[3].title.set_text('Predicted mask')
ax_img[4].imshow(vis_img)
ax_img[4].title.set_text('Segmentation result')
left = 0.92
bottom = 0.15
width = 0.015
height = 1 - 2 * bottom
rect = [left, bottom, width, height]
cbar_ax = fig_img.add_axes(rect)
cb = plt.colorbar(ax, shrink=0.6, cax=cbar_ax, fraction=0.046)
cb.ax.tick_params(labelsize=8)
font = {
'family': 'serif',
'color': 'black',
'weight': 'normal',
'size': 8,
}
cb.set_label('Anomaly Score', fontdict=font)
fig_img.savefig(os.path.join(save_dir, class_name + '_{}'.format(i)), dpi=100)
plt.close()
def load_model(args, device):
# load model
if args.arch == 'resnet18':
model = resnet18(pretrained=True, progress=False)
t_d = 448
d = 100
elif args.arch == 'wide_resnet50_2':
model = wide_resnet50_2(pretrained=True, progress=False)
t_d = 1792
d = 550
model.to(device)
model.eval()
return model, t_d, d
def train(args, model, device, idx):
# set model's intermediate outputs
outputs = []
def hook(module, input, output):
outputs.append(output)
model.layer1[-1].register_forward_hook(hook)
model.layer2[-1].register_forward_hook(hook)
model.layer3[-1].register_forward_hook(hook)
os.makedirs(os.path.join(args.save_path, 'temp_%s' % args.arch), exist_ok=True)
for class_name in CLASS_NAMES:
train_dataset = MVTecDataset(args.data_path, class_name=class_name, is_train=True)
train_dataloader = DataLoader(train_dataset, batch_size=32, pin_memory=True)
train_outputs = OrderedDict([('layer1', []), ('layer2', []), ('layer3', [])])
# extract train set features
train_feature_filepath = os.path.join(args.save_path, 'temp_%s' % args.arch, 'train_%s.pkl' % class_name)
for (x, _, _) in tqdm(train_dataloader, '| feature extraction | train | %s |' % class_name):
# model prediction
with torch.no_grad():
_ = model(x.to(device))
# get intermediate layer outputs
for k, v in zip(train_outputs.keys(), outputs):
train_outputs[k].append(v.cpu().detach())
# initialize hook outputs
outputs = []
for k, v in train_outputs.items():
train_outputs[k] = torch.cat(v, 0)
# Embedding concat
embedding_vectors = train_outputs['layer1']
for layer_name in ['layer2', 'layer3']:
embedding_vectors = embedding_concat(embedding_vectors, train_outputs[layer_name])
# randomly select d dimension
embedding_vectors = torch.index_select(embedding_vectors, 1, idx)
# calculate multivariate Gaussian distribution
B, C, H, W = embedding_vectors.size()
embedding_vectors = embedding_vectors.view(B, C, H * W)
mean = torch.mean(embedding_vectors, dim=0).numpy()
cov = torch.zeros(C, C, H * W).numpy()
I = np.identity(C)
for i in range(H * W):
# cov[:, :, i] = LedoitWolf().fit(embedding_vectors[:, :, i].numpy()).covariance_
cov[:, :, i] = np.cov(embedding_vectors[:, :, i].numpy(), rowvar=False) + 0.01 * I
# save learned distribution
train_outputs = [mean, cov]
with open(train_feature_filepath, 'wb') as f:
pickle.dump(train_outputs, f)
def val(args, model, device, idx):
# set model's intermediate outputs
outputs = []
def hook(module, input, output):
outputs.append(output)
model.layer1[-1].register_forward_hook(hook)
model.layer2[-1].register_forward_hook(hook)
model.layer3[-1].register_forward_hook(hook)
total_roc_auc = []
total_pixel_roc_auc = []
fig, ax = plt.subplots(1, 2, figsize=(20, 10))
fig_img_rocauc = ax[0]
fig_pixel_rocauc = ax[1]
for class_name in CLASS_NAMES:
test_dataset = MVTecDataset(args.data_path, class_name=class_name, is_train=False)
test_dataloader = DataLoader(test_dataset, batch_size=32, pin_memory=True)
test_outputs = OrderedDict([('layer1', []), ('layer2', []), ('layer3', [])])
train_feature_filepath = os.path.join(args.save_path, 'temp_%s' % args.arch, 'train_%s.pkl' % class_name)
print('load train set feature from: %s' % train_feature_filepath)
with open(train_feature_filepath, 'rb') as f:
train_outputs = pickle.load(f)
gt_list = []
gt_mask_list = []
test_imgs = []
# extract test set features
for (x, y, mask) in tqdm(test_dataloader, '| feature extraction | test | %s |' % class_name):
test_imgs.extend(x.cpu().detach().numpy())
gt_list.extend(y.cpu().detach().numpy())
gt_mask_list.extend(mask.cpu().detach().numpy())
# model prediction
with torch.no_grad():
_ = model(x.to(device))
# get intermediate layer outputs
for k, v in zip(test_outputs.keys(), outputs):
test_outputs[k].append(v.cpu().detach())
# initialize hook outputs
outputs = []
for k, v in test_outputs.items():
test_outputs[k] = torch.cat(v, 0)
# Embedding concat
embedding_vectors = test_outputs['layer1']
for layer_name in ['layer2', 'layer3']:
embedding_vectors = embedding_concat(embedding_vectors, test_outputs[layer_name])
# randomly select d dimension
embedding_vectors = torch.index_select(embedding_vectors, 1, idx)
# calculate distance matrix
B, C, H, W = embedding_vectors.size()
embedding_vectors = embedding_vectors.view(B, C, H * W).numpy()
dist_list = []
for i in range(H * W):
mean = train_outputs[0][:, i]
conv_inv = np.linalg.inv(train_outputs[1][:, :, i])
dist = [mahalanobis(sample[:, i], mean, conv_inv) for sample in embedding_vectors]
dist_list.append(dist)
dist_list = np.array(dist_list).transpose(1, 0).reshape(B, H, W)
# upsample
dist_list = torch.tensor(dist_list)
score_map = F.interpolate(dist_list.unsqueeze(1), size=x.size(2), mode='bilinear',
align_corners=False).squeeze().numpy()
# apply gaussian smoothing on the score map
for i in range(score_map.shape[0]):
score_map[i] = gaussian_filter(score_map[i], sigma=4)
# Normalization
max_score = score_map.max()
min_score = score_map.min()
scores = (score_map - min_score) / (max_score - min_score)
# calculate image-level ROC AUC score
img_scores = scores.reshape(scores.shape[0], -1).max(axis=1)
gt_list = np.asarray(gt_list)
fpr, tpr, _ = roc_curve(gt_list, img_scores)
img_roc_auc = roc_auc_score(gt_list, img_scores)
total_roc_auc.append(img_roc_auc)
print('image ROCAUC: %.3f' % (img_roc_auc))
fig_img_rocauc.plot(fpr, tpr, label='%s img_ROCAUC: %.3f' % (class_name, img_roc_auc))
# get optimal threshold
gt_mask = np.asarray(gt_mask_list)
precision, recall, thresholds = precision_recall_curve(gt_mask.flatten(), scores.flatten())
a = 2 * precision * recall
b = precision + recall
f1 = np.divide(a, b, out=np.zeros_like(a), where=b != 0)
threshold = thresholds[np.argmax(f1)]
# calculate per-pixel level ROCAUC
fpr, tpr, _ = roc_curve(gt_mask.flatten(), scores.flatten())
per_pixel_rocauc = roc_auc_score(gt_mask.flatten(), scores.flatten())
total_pixel_roc_auc.append(per_pixel_rocauc)
print('pixel ROCAUC: %.3f' % (per_pixel_rocauc))
fig_pixel_rocauc.plot(fpr, tpr, label='%s ROCAUC: %.3f' % (class_name, per_pixel_rocauc))
save_dir = args.save_path + '/' + f'pictures_{
args.arch}'
os.makedirs(save_dir, exist_ok=True)
plot_fig(test_imgs, scores, gt_mask_list, threshold, save_dir, class_name)
print('Average ROCAUC: %.3f' % np.mean(total_roc_auc))
fig_img_rocauc.title.set_text('Average image ROCAUC: %.3f' % np.mean(total_roc_auc))
fig_img_rocauc.legend(loc="lower right")
print('Average pixel ROCUAC: %.3f' % np.mean(total_pixel_roc_auc))
fig_pixel_rocauc.title.set_text('Average pixel ROCAUC: %.3f' % np.mean(total_pixel_roc_auc))
fig_pixel_rocauc.legend(loc="lower right")
fig.tight_layout()
fig.savefig(os.path.join(args.save_path, 'roc_curve.png'), dpi=100)
def parse_args():
parser = argparse.ArgumentParser('PaDiM')
parser.add_argument('--data_path', type=str, default='/home/liumin/data/mvtec_ad')
parser.add_argument('--save_path', type=str, default='./result')
parser.add_argument('--arch', type=str, choices=['resnet18', 'wide_resnet50_2'], default='wide_resnet50_2')
return parser.parse_args()
if __name__ == '__main__':
args = parse_args()
# device setup
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model, t_d, d = load_model(args, device)
idx = torch.tensor(sample(range(0, t_d), d))
train(args, model, device, idx)
val(args, model, device, idx)
智能推荐
Spring Boot 获取 bean 的 3 种方式!还有谁不会?,Java面试官_springboot2.7获取bean-程序员宅基地
文章浏览阅读1.2k次,点赞35次,收藏18次。AutowiredPostConstruct 注释用于在依赖关系注入完成之后需要执行的方法上,以执行任何初始化。此方法必须在将类放入服务之前调用。支持依赖关系注入的所有类都必须支持此注释。即使类没有请求注入任何资源,用 PostConstruct 注释的方法也必须被调用。只有一个方法可以用此注释进行注释。_springboot2.7获取bean
Logistic Regression Java程序_logisticregression java-程序员宅基地
文章浏览阅读2.1k次。理论介绍 节点定义package logistic;public class Instance { public int label; public double[] x; public Instance(){} public Instance(int label,double[] x){ this.label = label; th_logisticregression java
linux文件误删除该如何恢复?,2024年最新Linux运维开发知识点-程序员宅基地
文章浏览阅读981次,点赞21次,收藏18次。本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。下面我们来进行文件的恢复,执行下文中的lsof命令,在其返回结果中我们可以看到test-recovery.txt (deleted)被删除了,但是其存在一个进程tail使用它,tail进程的进程编号是1535。我们看到文件名为3的文件,就是我们刚刚“误删除”的文件,所以我们使用下面的cp命令把它恢复回去。命令进入该进程的文件目录下,1535是tail进程的进程id,这个文件目录里包含了若干该进程正在打开使用的文件。
流媒体协议之RTMP详解-程序员宅基地
文章浏览阅读10w+次,点赞12次,收藏72次。RTMP(Real Time Messaging Protocol)实时消息传输协议是Adobe公司提出得一种媒体流传输协议,其提供了一个双向得通道消息服务,意图在通信端之间传递带有时间信息得视频、音频和数据消息流,其通过对不同类型得消息分配不同得优先级,进而在网传能力限制下确定各种消息得传输次序。_rtmp
微型计算机2017年12月下,2017年12月计算机一级MSOffice考试习题(二)-程序员宅基地
文章浏览阅读64次。2017年12月的计算机等级考试将要来临!出国留学网为考生们整理了2017年12月计算机一级MSOffice考试习题,希望能帮到大家,想了解更多计算机等级考试消息,请关注我们,我们会第一时间更新。2017年12月计算机一级MSOffice考试习题(二)一、单选题1). 计算机最主要的工作特点是( )。A.存储程序与自动控制B.高速度与高精度C.可靠性与可用性D.有记忆能力正确答案:A答案解析:计算...
20210415web渗透学习之Mysqludf提权(二)(胃肠炎住院期间转)_the provided input file '/usr/share/metasploit-fra-程序员宅基地
文章浏览阅读356次。在学MYSQL的时候刚刚好看到了这个提权,很久之前用过别人现成的,但是一直时间没去细想, 这次就自己复现学习下。 0x00 UDF 什么是UDF? UDF (user defined function),即用户自定义函数。是通过添加新函数,对MySQL的功能进行扩充,就像使..._the provided input file '/usr/share/metasploit-framework/data/exploits/mysql
随便推点
webService详细-程序员宅基地
文章浏览阅读3.1w次,点赞71次,收藏485次。webService一 WebService概述1.1 WebService是什么WebService是一种跨编程语言和跨操作系统平台的远程调用技术。Web service是一个平台独立的,低耦合的,自包含的、基于可编程的web的应用程序,可使用开放的XML(标准通用标记语言下的一个子集)标准...
Retrofit(2.0)入门小错误 -- Could not locate ResponseBody xxx Tried: * retrofit.BuiltInConverters_已添加addconverterfactory 但是 could not locate respons-程序员宅基地
文章浏览阅读1w次。前言照例给出官网:Retrofit官网其实大家学习的时候,完全可以按照官网Introduction,自己写一个例子来运行。但是百密一疏,官网可能忘记添加了一句非常重要的话,导致你可能出现如下错误:Could not locate ResponseBody converter错误信息:Caused by: java.lang.IllegalArgumentException: Could not l_已添加addconverterfactory 但是 could not locate responsebody converter
一套键鼠控制Windows+Linux——Synergy在Windows10和Ubuntu18.04共控的实践_linux 18.04 synergy-程序员宅基地
文章浏览阅读1k次。一套键鼠控制Windows+Linux——Synergy在Windows10和Ubuntu18.04共控的实践Synergy简介准备工作(重要)Windows服务端配置Ubuntu客户端配置配置开机启动Synergy简介Synergy能够通过IP地址实现一套键鼠对多系统、多终端进行控制,免去了对不同终端操作时频繁切换键鼠的麻烦,可跨平台使用,拥有Linux、MacOS、Windows多个版本。Synergy应用分服务端和客户端,服务端即主控端,Synergy会共享连接服务端的键鼠给客户端终端使用。本文_linux 18.04 synergy
nacos集成seata1.4.0注意事项_seata1.4.0 +nacos 集成-程序员宅基地
文章浏览阅读374次。写demo的时候遇到了很多问题,记录一下。安装nacos1.4.0配置mysql数据库,新建nacos_config数据库,并根据初始化脚本新建表,使配置从数据库读取,可单机模式启动也可以集群模式启动,启动时 ./start.sh -m standaloneapplication.properties 主要是db部分配置## Copyright 1999-2018 Alibaba Group Holding Ltd.## Licensed under the Apache License,_seata1.4.0 +nacos 集成
iperf3常用_iperf客户端指定ip地址-程序员宅基地
文章浏览阅读833次。iperf使用方法详解 iperf3是一款带宽测试工具,它支持调节各种参数,比如通信协议,数据包个数,发送持续时间,测试完会报告网络带宽,丢包率和其他参数。 安装 sudo apt-get install iperf3 iPerf3常用的参数: -c :指定客户端模式。例如:iperf3 -c 192.168.1.100。这将使用客户端模式连接到IP地址为192.16..._iperf客户端指定ip地址
浮点性(float)转化为字符串类型 自定义实现和深入探讨C++内部实现方法_c++浮点数 转 字符串 精度损失最小-程序员宅基地
文章浏览阅读7.4k次。 写这个函数目的不是为了和C/C++库中的函数在性能和安全性上一比高低,只是为了给那些喜欢探讨函数内部实现的网友,提供一种从浮点性到字符串转换的一种途径。 浮点数是有精度限制的,所以即使我们在使用C/C++中的sprintf或者cout 限制,当然这个精度限制是可以修改的。比方在C++中,我们可以cout.precision(10),不过这样设置的整个输出字符长度为10,而不是特定的小数点后1_c++浮点数 转 字符串 精度损失最小