Elasticsearch和Hive整合,将hive数据同步到ES中_hive映射es 一对多-程序员宅基地
技术标签: # Elasticseach/Logstash/Kibana # HIVE(数据库仓库工具)
1 Elasticsearch整合Hive
1.1 软件环境
Hadoop软件环境
Hive软件环境
ES软件环境
1.2 ES-Hadoop介绍
1.2.1 官网
https://www.elastic.co/cn/products/hadoop
1.2.2 对 Hadoop 数据进行交互分析
Hadoop 是出色的批量处理系统,但是要想提供实时结果则颇具挑战。为了实现真正的交互式数据探索,您可以使用 ES-Hadoop 将 Hadoop 数据索引到 Elastic Stack,以充分利用快速的 Elasticsearch 引擎和Kibana精美的可视化效果。
有了 ES-Hadoop,您可以轻松构建动态的嵌入式搜索应用来处理您的 Hadoop 数据,或者使用全文本、空间地理查询和聚合,执行深度的低延时分析。从产品推荐到基因组测序,ES-Hadoop 开启了广泛而全新的应用领域。

1.2.3 让数据在 Elasticsearch 和 Hadoop 之间无缝移动
只有实现了数据的快速移动,才能让实时决策成为可能。凭借现有Hadoop API的动态扩展,ES-Hadoop让您能够在Elasticsearch和Hadoop之间轻松地双向移动数据,同时借助HDFS作为存储库,进行长期存档。分区感知、故障处理、类型转换和数据共享均可透明地完成。
1.2.4 本地对接Spark及其衍生技术
ES-Hadoop 完全支持 Spark、Spark Streaming 和 SparkSQL。此外,无论您使用 Hive、Pig、Storm、Cascading,还是标准 MapReduce,ES-Hadoop 都将提供本地对接,供您向 Elasticsearch 索引数据并从 Elasticsearch 查询数据。无论您用哪种技术,Elasticsearch 的所有功能任您支配。
1.2.5 随时随地确保数据安全
ES-Hadoop 拥有您需要的所有安全功能,包括 HTTP 身份验证和对 SSL/TLS 的支持。此外,它还能与支持 Kerberos 的 Hadoop 部署一起使用。
1.3 安装
1.3.1 常规安装
获取Elasticsearch-hadoop二进制文件可以通过从http://elastic.co/下载一个zip包(这个zip包中包含jars,sources,和documention),或者通过添加依赖文件:
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-hadoop</artifactId>
<version>7.1.1</version>
</dependency>
上面的这个jar包包含所有的Elasticsearch-Hadoop的特性,在运行时期间不需要任何其它的依赖。换句话说,它可以原样使用。
Elasticsearch-hadoop二进制适用于Hadoop 2.x(又叫做yarn)环境,在5.5版本之后支持hadoop 1.x版本环境的将会过时,在6.0之后将不会再进行测试。
1.3.2 最小版二进制包
Elasticsearch-hadoop提供最小版本的用于每个集成的jar包,
1.3.2.1 Map/Reduce集成
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-hadoop-mr</artifactId>
<version>7.1.1</version>
</dependency>
1.3.2.2 Hive集成
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-hadoop-hive</artifactId>
<version>7.1.1</version>
</dependency>
1.3.2.3 Pig集成
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-hadoop-pig</artifactId>
<version>7.1.1</version>
</dependency>
1.3.2.4 Spark集成
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-spark-20_2.10</artifactId>
<version>7.1.1</version>
</dependency>
注意:spark artifact。注意后缀中的这个-20表示spark的兼容版本。Spark 2.0+使用20,Spark 1.3 ~1.6使用13.
要注意的是,_2.10后缀表示scala的兼容版本。
以下是Spark version和ES-Hadoop Artifact ID的对应版本。

1.3.2.5 Strom集成
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-storm</artifactId>
<version>7.1.1</version>
</dependency>
1.3.3 配置
Elasticsearch-Hadoop的行为可以通过下面的属性来定制。
1.3.3.1 Required settings
es.resource
Elasticsearch资源的位置,数据读取和写入的位置。需要的格式是: /。
es.resource = twitter/tweet #index是’twitter’,type是’tweet’
es.resource.read(默认为es.resource)
Elasticsearch读取的数据资源(不是写)。在使用相同的job将数据读或写到不同的Elasticsearch的indices的时候将会很有用。通常设置成自动(除了Map/Reduce模块需要手动配置)。格式也是/,如artists/_doc。
支持多个index,如artists,bank/_doc,表示从artists和bank索引的_doc/读取数据。artists,bank/,表示从artists和bank索引中读取数据,type任意。_all/_doc表示从所有的_doc读取数据。
add jar elasticsearch-hadoop-6.1.2.jar;
add jar json-udf-1.3.8-jar-with-dependencies.jar;
add jar json-serde-1.3.8-jar-with-dependencies.jar;
CREATE TABLE x (
`es_metadata` string,
`nested1` struct<item1:string, item2:int>,
`nested2` struct<iterm3:double, iterm4:string>)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler'
TBLPROPERTIES(
'es.output.json' = 'true',
'es.resource.read' = 'netsed/test',
'es.nodes'='${nodes}',
'es.read.metadata' = 'true',
'es.read.metadata.field' = 'es_metadata',
'es.field.read.empty.as.null'='false',
'es.mapping.names' = 'nested2:Nested2,nested1:nested1'
);
es.resource.write(默认为es.resource)
Elasticsearch用于写入的资源(而不是读),通常用于动态资源写入,或在同一作业中将数据写入和读取到不同的Elasticsearch索引时使用.通常设置成自动(除了Map/Reduce模块需要手动配置)。
要注意的是在上面的resource设置里面指定的多个indices、type.只允许在reading的时候使用。只有在使用dynamic resource的时候支持指定多个indices。
1.3.3.2 Dynamic/multi resource writes
对于编写,Elasticsearch -hadoop允许在运行时使用模式(通过使用{}格式)解析目标资源,并根据流到Elasticsearch的数据在运行时解析。也就是说,可以基于从要保存的文档解析的一个或多个字段将文档保存到某个索引或类型。
例如,假设有下面的文档集合
{
"media_type":"game",
"title":"Final Fantasy VI",
"year":"1994"
},
{
"media_type":"book",
"title":"Harry Potter",
"year":"2010"
},
{
"media_type":"music",
"title":"Surfing With The Alien",
"year":"1987"
}
要根据它们的media_type为每个类建立索引,可以使用一下模式:
# 根据文档的类型来索引它们
es.resource.write = my-collection/{media_type}
通过上面的配置,将导致”Final Fantasy VI”在my-collection/game中,Harry Potter在my-collection/book,”Surfing With The Alien”在my-collection/music。想了解更多的信息,可以参考专门的dedicated集成章节。
1.3.3.3 Formatting dynamic/multi resource writes
当使用dynamic/multi写时,还可以指定字段返回值的格式。hadoop提供了日期/时间戳字段的开箱即用格式,这对于在相同索引下的特定时间范围内自动分组基于时间的数据(例如日志)非常有用。通过使用Java SimpleDataFormat语法,可以以一种对语言环境敏感的方式格式化和解析日期。
例如,假设数据包含@timestamp字段,可以使用以下配置将文档分组到每日索引中:

@timestamp field formatting - in this case yyyy.MM.dd
@timestamp字段格式,在本例中是yyyy.MM.dd格式。
同样是使用这个相同的配置(es.resource.write),然而,通过特殊的|字符指定格式化模式。请参考SimpleDateFormat的javadocs获取更多的关于这个的语法支持。在这种情况下,yyyy.MM.dd将日期转换为年份(由四位数字指定)、月份(由两位数字指定)和天(如2015.01.28)。
1.3.3.4 Essential Settings
网络相关
es.nodes(默认localhost)
列出要连接的Elasticsearch节点。当远程使用Elasticsearch的时候,请设置这个参数。要注意的是这个列表中不一定非要包含Elasticsearch集群中的每个节点;默认情况下,这些是由elasticsearch-hadoop自动发现的(参见下面)。每个节点还可以单独指定其HTTP/REST端口(例如:mynode:9600)。
es.port(默认9200)
用于连接到Elasticsearch的默认的HTTP/REST端口。这个设置用于在es.nodes中没有指定端口的情况下使用。
es.nodes.path.prefix(默认空)
前缀,以添加到向Elasticsearch发出的所有请求中。适用于集群在特定路径下代理/路由的环境。例如,如果es集群位于someaddress:someport/custom/path/prefix 下,可以设置es.nodes.path.prefix 为 /custom/path/prefix。
1.3.3.5 Querying
es.query(默认为none)
保存从指定的es.resource中读取的数据,默认情况下他不为设置,也不为空。意味着在指定的index/type下的整个数据都被返回。es.query可以有三个来源:
uri query
使用?uri_query的这种格式,可以设置一个query string。要注意的是这个前导’?’。
query dsl
使用query_dsl格式,注意这个query dsl前缀需要以{开始,以}结束。
external resource
如果上面两个都不匹配,elasticsearch-hadoop将尝试将该参数解释为HDFS文件系统中的路径。如果不是这样,它将尝试从类路径加载资源,如果失败,则尝试从Hadoop DistributedCache加载资源。资源应该包含uri查询或查询dsl。
下面是示例:
# uri (or parameter) query
es.query = ?q=costinl
# query dsl
es.query = { "query" : { "term" : { "user" : "costinl" } } }
# external resource
es.query = org/mypackage/myquery.json
其它参数:https://www.elastic.co/guide/en/elasticsearch/hadoop/current/configuration.html
1.3.4 Apache Hive integration
1.3.4.1 Installation
要确保elasticsearch-hadoop的jar能够在Hive classpath能够访问到。取决于你的选择,有很多中方式可以实现这一点。使用add命令添加jar文件,或者归档类路径。
ADD JAR /path/elasticsearch-hadoop.jar;
作为一个替代方案,也可以使用过下面的命令行:
CLI配置
$ bin/hive --auxpath=/path/elasticsearch-hadoop.jar
或者在命令行中使用hive.aux.jars.path属性、或者在hive-site.xml文件中,注册额外的jar(它也接收URI):
$ bin/hive -hiveconf hive.aux.jars.path=/path/elasticsearch-hadoop.jar
在hive-site.xml中也可以配置:
<property>
<name>hive.aux.jars.path</name>
<value>/path/elasticsearch-hadoop.jar</value>
<description>A comma separated list (with no spaces) of the jar files</description>
</property>
1.3.4.2 Configuration
当使用Hive,当声明支持Elasticsearch的外部表的时候,可以使用TBLPROPERTIES指定这个配置属性(作为Hadoop配置对象的可选配置),例如:
CREATE EXTERNAL TABLE artists (...)
STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler'
TBLPROPERTIES('es.resource' = 'radio/artists',
'es.index.auto.create' = 'false');
1.3.4.3 Mapping
默认情况下,elasticsearch-hadoop使用Hive的schema去映射在Elasticsearch中的数据。在这个过程中使用字段名称和类型。但是,在某些情况下,Hive中的名称不能与Elasticsearch一起使用(字段名可以包含Elasticsearch接受但Hive不接受的字符)。对于这种情况,可以使用es.mapping.names设置,接收以下的按照冒号分割的格式: Hive field name : Elasticsearch field name.
即:
CREATE EXTERNAL TABLE artists (...)
STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler'
TBLPROPERTIES('es.resource' = 'radio/artists',
'es.mapping.names' = 'date:@timestamp, url:url_123');
Hive 列 date映射到 Elasticsearch 中的 @timestamp; Hive的列url映射到Elasticsearch为url_123
注意:
1、Hive是大小写不敏感的然而Elasticsearch不是。数据丢失了可能产生无效的查询(因为在Hive中的列可能不能匹配Elasticsearch中的列)。为了避免这种问题,elasticsearch-hadoop将总是将Hive的列名称都转成小写。这就是说,建议使用默认的Hive样式,只对Hive命令使用大写名称,并避免混合大小写名称。
2、Hive通过一个特殊的NULL来对待丢失的值。这就意味着当运行一个不正确的查询(不正确或者名称不存在)时,Hive表将使用NULL填充,而不是抛出一个异常。确保验证你的数据,密切关注你的schema, 否则由于这种宽松的行为,更新将不会被注意到。
1.3.4.4 Writing data to Elasticsearch
有了elasticsearch-hadoop,Elasticsearch可以仅仅通过一个外部表load和读取数据:
CREATE EXTERNAL TABLE artists (
id BIGINT,
name STRING,
links STRUCT<url:STRING, picture:STRING>)
STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler' (1)
TBLPROPERTIES('es.resource' = 'radio/artists'); (2)
-- insert data to Elasticsearch from another table called 'source'
INSERT OVERWRITE TABLE artists
SELECT NULL, s.name, named_struct('url', s.url, 'picture', s.picture)
FROM source s;
(1)Elasticsearch Hive StorageHandler
(2)Elasticsearch resource (index and type) associated with the given storage
当文档中需要指定id(或者其他的metadata字段如ttl和timestamp)的时候,可以设置适当的mapping,也就是 es.mapping.id.紧跟上面的例子,指示Elasticsearch使用id作为文档的id,更新表的属性:
CREATE EXTERNAL TABLE artists (
id BIGINT,
...)
STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler'
TBLPROPERTIES('es.mapping.id' = 'id'...);
1.3.4.5 Writing existing JSON to Elasticsearch
对于job作业中输入数据已经在JSON中的场景,elasticsearch-hadoop允许直接索引,而不需要应用任何转换。数据直接按照原样直接发送到Elasticsearch.在这种情况下,需要创建为这个json创建索引通过设置es.input.json参数。同样地,elasticsearch-hadoop期望输出表只包含一个字段,这个内容用于作为json文档。就是说,这个library将识别指定的textual类型(例如:string 或 binary),或简单地调用(toString)。
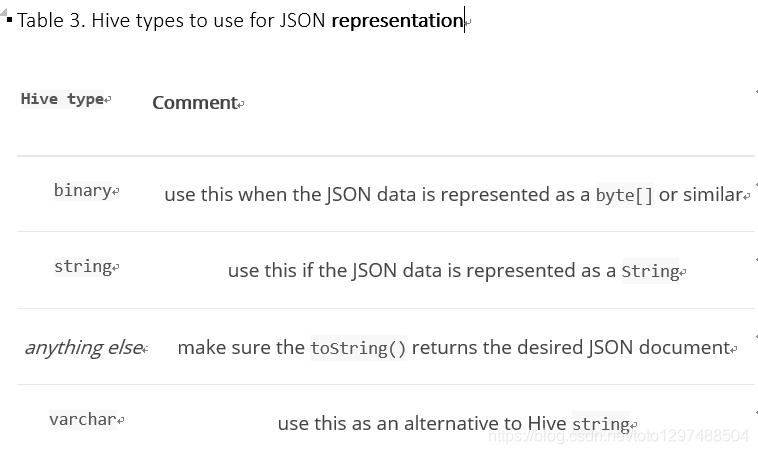
注意:
确保数据以UTF-8正确的编码。字段内容被认为是发送到Elasticsearch的文档的最终形式。
CREATE EXTERNAL TABLE json (data STRING) (1)
STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler'
TBLPROPERTIES('es.resource' = '...',
'es.input.json` = 'yes');
(1)这个表的声明中只有一个STRING类型的字段。
(2)表明elasticsearch-hadoop 表的内容是JSON格式。
1.3.4.6 Writing to dynamic/multi-resources
可以使用模式将数据索引到不同的资源,具体取决于读取的行, 回到前面提到的media例子,我们可以这样配置它:
CREATE EXTERNAL TABLE media (
name STRING,
type STRING, (1)
year STRING,
STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler'
TBLPROPERTIES('es.resource' = 'my-collection-{type}/doc');
(1)表的字段被用于resource pattern. 可以使用任何声明的字段。
(2)资源的pattern 使用字段type
对于将要编写的每一行,elasticsearch-hadoop将提取type字段并使用其值确定目标资源。
在处理json数据的时候,同样适用,既然这样,这个值将从JSON文档中提取。假设有以下的JSON资源包含的文档结构如下:
{
"media_type":"music", (1)
"title":"Surfing With The Alien",
"year":"1987"
}
(1)将被用于pattern的json中的字段。
表的声明可以按照下面的方式声明:
CREATE EXTERNAL TABLE json (data STRING) (1)
STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler'
TBLPROPERTIES('es.resource' = 'my-collection-{media_type}/doc',
'es.input.json` = 'yes'); (2)
1.3.4.7 Reading data from Elasticsearch
从ElasticSearch中读取数据,类似如下:
CREATE EXTERNAL TABLE artists (
id BIGINT,
name STRING,
links STRUCT<url:STRING, picture:STRING>)
STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler' (1)
TBLPROPERTIES('es.resource' = 'radio/artists', (2)
'es.query' = '?q=me*'); (3)
-- stream data from Elasticsearch
SELECT * FROM artists;
Type conversion
Hive为定义数据提供了各种类型,并根据目标环境(从JDK本机类型到二进制优化的类型)在内部使用不同的实现。Elasticsearch集成了所有这些,包括和Serde2 lazy和lazy binary:
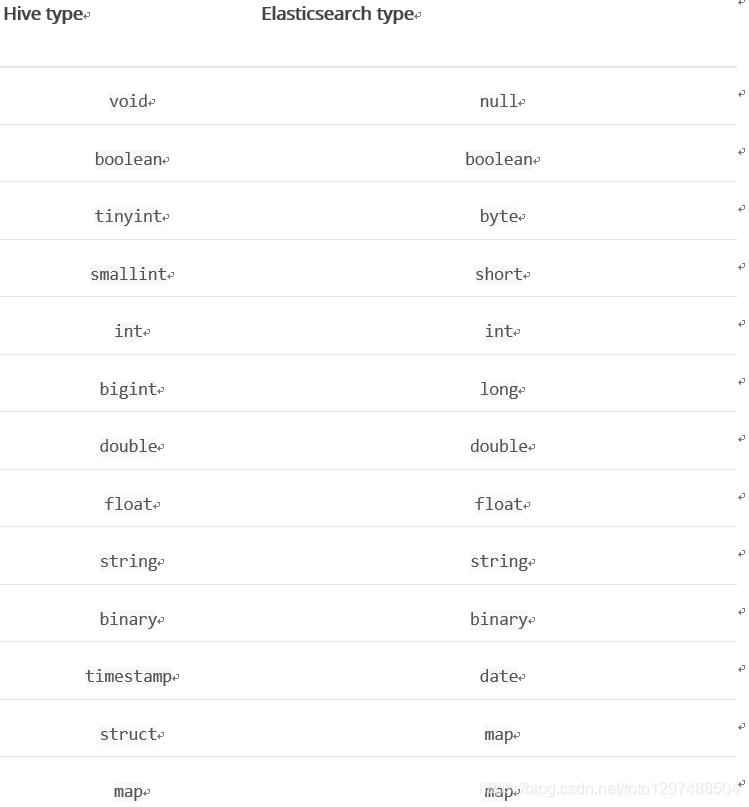
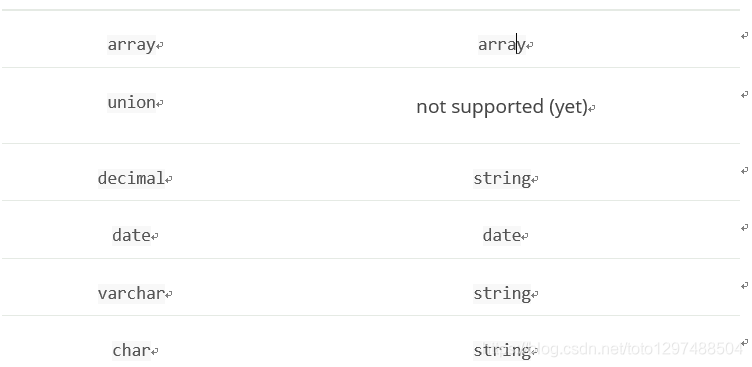
注意:
尽管Elasticsearch在2.0版之前可以理解Hive类型,但它向后兼容Hive 1.0
1.4 案例
将hive中的数据同步到ES中。
drop table if exists testhadoop;
CREATE EXTERNAL TABLE testhadoop (
ID bigint,
SUBJECT STRING,
xxxxx)
STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler'
TBLPROPERTIES('es.nodes'='ip:10200',
'es.resource'='xxx/xxxx',
'es.index.auto.create'='false',
'es.mapping.id'='ID',
'es.mapping.names'= 'ID:ID,SUBJECT:SUBJECT,xxxxx',
'es.nodes.wan.only'='true',
'es.batch.write.retry.count'='10',
'es.batch.write.refresh'='true',
'es.batch.write.retry.wait'='60s',
'es.http.timeout'='100m',
'es.batch.size.entries'='100');
INSERT INTO TABLE testhadoop
select 子句;
智能推荐
桌面计算机网络图标不见了怎么办,网络连接图标不见了,教您网络连接图标不见了怎么办...-程序员宅基地
文章浏览阅读1.8k次。随着计算机的出现,网络连接图标被赋予了新的含义,又有了新的用武之地。电脑能联网,但是电脑桌面任务栏右下角的“网络”或是“本地链接”图标却不见了,你是不是也曾遇到过这类电脑问题呢?下面,小编给大家讲解网络连接图标不见了的处理技巧。我们都知道电脑的右下角有很多的快捷键,在我们使用的时候可以很方便的使用到。打开电脑,桌面的网络图标不见了,进入网上邻居查看同事电脑的共享文件,非常不方便,怎么来把网络图标再..._电脑联网的图标不见了
centos 安装git并配置ssh_centos设置git ssh-程序员宅基地
文章浏览阅读405次,点赞9次,收藏7次。centos 安装git并配置ssh_centos设置git ssh
如何利用 onlyoffice 实现文档格式转换_onlyoffice转换pdf-程序员宅基地
文章浏览阅读744次。日常生活和工作中,文档格式转换应该是很常见的需求。面对这样的需求,我们技术男有没有属于自己的好方法呢?答案是有的,它就是 onlyoffice,今天就来介绍如何利用 onlyoffice 实现文档格式转换。官方的 onlyoffice 版本在 4.2 之前使用的请求是 Get 类型,之后的版本使用的请求类型是 Post,这一点需要我们特别注意。下面的表格是关于格式转换 API 参数的详细介绍。属性参数描述数据类型存在类型Async定义转换请求类型:异步与否。支持的值:truefalse。_onlyoffice转换pdf
JavaScript Math.PI 属性-程序员宅基地
文章浏览阅读1.4w次,点赞3次,收藏16次。什么是PI?PI就是圆周率π,PI是弧度制的π,也就是180°所以,Math.PI = 3.14 = 180°ps,PI是一个浮小数Math.PI/5*4分别是什么意思?let dig = Math.PI/5*4Math.PI/5,表示角度平分为36° 每个顶点到与中心连线之间的夹角α=(2π)/n = Math.PI / n * 2 那么相间的两个顶点到与中心连线之间的夹..._math.pi
Windows下,使用免安装ZIP归档,安装MySQL(5.5)服务器-程序员宅基地
文章浏览阅读1.1k次。1. 解压 MySQL ZIP压缩包 到 安装路径 D:\xapp\apps\,并将解压出来的文件夹重命名为 mysql。2.将MySQL的可执行文件目录 D:\xapp\apps\mysql\bin 加入系统环境变量,然后重启计算机。6.启动Windows命令行 键入 mysql -u root -p ,然后两次回车,进入MySQL控制台。如果通过配置文件 将 数据库目录设置到了别处,则需要将 mysql程序根目录的 data目录中。的内容拷贝到新的目录中,否则MySQL无法启动。
Bootstrap4总结(1)_bootstrap4的好处-程序员宅基地
文章浏览阅读1k次。一.Bootstrap简介1.什么是BootstrapBootstrap 是全球最受欢迎的前端组件库,用于开发响应式布局、移动设备优先的 WEB 项目。Bootstrap4 目前是 Bootstrap 的最新版本,是一套用于 HTML、CSS 和 JS 开发的开源工具集。2.Bootstrap的来源Bootstrap是美国Twitter公司的设计师Mark Otto和Jacob Thornton合作基于HTML、CSS、JavaScript开发的简洁、直观、强悍的前端开发框架,使得 W._bootstrap4的好处
随便推点
java file数组 初始化_Java数组的定义,声明,初始化和遍历-程序员宅基地
文章浏览阅读633次。数组的定义数组是相同类型数据的有序集合。数组描述的是相同类型的若干个数据,按照一定的先后次序排列组合而成。其中,每一个数据称作一个元素,每个元素可以通过一个索引(下标)来访问它们。数组的三个基本特点:1. 长度是确定的。数组一旦被创建,它的大小就是不可以改变的。2. 其元素必须是相同类型,不允许出现混合类型。3. 数组类型可以是任何数据类型,包括基本类型和引用类型。数组变量属引用类型,数组也可以看..._java file 数组
十四章上机1_北大青鸟java第十四章上机练习4-程序员宅基地
文章浏览阅读449次。实现客户姓名录入 package kj;public class kehu { String []names=new String[10]; public void addName(String name){ for(int i=0;i
React路由 报错 ‘Switch‘ is not exported from ‘react-router‘.-程序员宅基地
文章浏览阅读722次。配置 路由 报错 'Switch' is not exported from 'react-router'.npm uninstall react-router-domnpm install [email protected]
利用tushare实现选股_tushare 选股-程序员宅基地
文章浏览阅读1.1k次,点赞2次,收藏7次。ID:399899量化交易中,首先要弄好的就是选股。然后在才是买卖策略的制定。不同类型的策略,选股思路也不相同。俗话说得好,不管黑猫白猫,抓到老鼠的就是好猫。一个好的选股策略,往往在量化中是起较为关键的作用的。要实现程序化选股的话,数据又是一个前提。要有数据才能去实现编写程序。数据来源有很多,可以去爬取,也可以去股票交易网站下载。当然也有一些接口可以提供数据。常见的接口有tushare、baostock、akshare在这里我以一个简单的选股案例,为大家介绍一下使用tushare接口使用tush_tushare 选股
Gin框架使用Casbin进行用户权限校验_gin 的权限校验-程序员宅基地
文章浏览阅读3.7k次,点赞2次,收藏10次。以下是测试项目目录一、配置modelconf/casbin_rbac_model.conf# 请求[request_definition]r = sub,obj,act# sub ——> 想要访问资源的用户角色(Subject)——请求实体# obj ——> 访问的资源(Object)# act ——> 访问的方法(Action: get、post...)# 策略(.csv文件p的格式,定义的每一行为policy rule;p,p2为policy rule的名字。)_gin 的权限校验
OKR制定与实施:团队OKR众筹策略_运营okr的制定与实施-程序员宅基地
文章浏览阅读319次。例如,一个团队有20个人,其中有2个员工在共同做A业务,3个员工在共同做B业务,5个员工在共同做C业务,剩下10个员工在共同做D业务,那么可以基于业务相关性将这20个员工分成A业务研讨组、B业务研讨组、C业务研讨组和D业务研讨组,这样,在步骤2目标众筹时,就以A、B、C、D 4个研讨小组为单位,邀请其输出3~5个团队OKR,然后团队主管再基于所有小组贡献的团队OKR进行投票表决,形成团队的OKR。通过这种方式,大大增强了团队成员对团队目标的共识程度,团队目标真正变成了大家共同的目标,而不再只是主管的目标。_运营okr的制定与实施