迁移学习——数据不够的情况下训练深度学习模型_迁移学习数量-程序员宅基地
深度学习大牛吴恩达曾经说过:做 AI 研究就像造宇宙飞船,除了充足的燃料之外,强劲的引擎也是必不可少的。假如燃料不足,则飞船就无法进入预定轨道。而引擎不够强劲,飞船甚至不能升空。类比于 AI,深度学习模型就好像引擎,海量的训练数据就好像燃料,这两者对于 AI 而言同样缺一不可。
随着深度学习技术在机器翻译、策略游戏和自动驾驶等领域的广泛应用和流行,阻碍该技术进一步推广的一个普遍性难题也日渐凸显:训练模型所必须的海量数据难以获取。
以下是一些当前比较流行的机器学习模型和其所需的数据量,可以看到,随着模型复杂度的提高,其参数个数和所需的数据量也是惊人的。

基于这一现状,本文将从深度学习的层状结构入手,介绍模型训练所需的数据量和模型规模的关系,然后通过一个具体实例介绍迁移学习在减少数据量方面起到的重要作用,最后推荐一个可以简化迁移学习实现步骤的云工具:NanoNets。
层状结构的深度学习模型
深度学习是一个大型的神经网络,同时也可以被视为一个流程图,数据从其中的一端输入,训练结果从另一端输出。正因为是层状的结构,所以你也可以打破神经网络,将其按层次分开,并以任意一个层次的输出作为其他系统的输入重新展开训练。
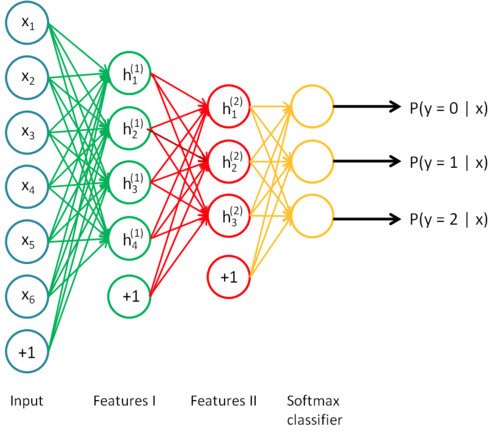
数据量、模型规模和问题复杂度
模型需要的训练数据量和模型规模之间存在一个有趣的线性正相关关系。其中的一个基本原理是,模型的规模应该足够大,这样才能充分捕捉数据间不同部分的联系(例如图像中的纹理和形状,文本中的语法和语音中的音素)和待解决问题的细节信息(例如分类的数量)。模型前端的层次通常用来捕获输入数据的高级联系(例如图像边缘和主体等)。模型后端的层次通常用来捕获有助于做出最终决定的信息(通常是用来区分目标输出的细节信息)。因此,待解决的问题的复杂度越高(如图像分类等),则参数的个数和所需的训练数据量也越大。
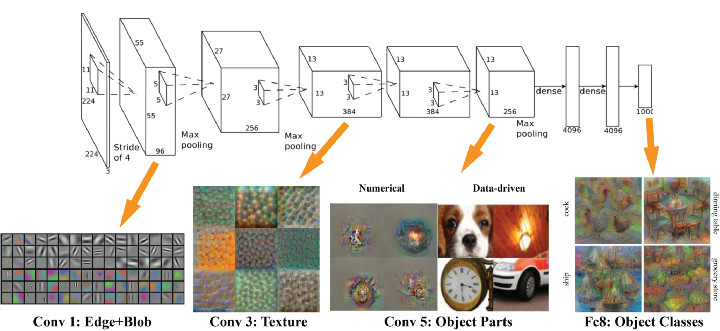
引入迁移学习
在大多数情况下,面对某一领域的某一特定问题,你都不可能找到足够充分的训练数据,这是业内一个普遍存在的事实。但是,得益于一种技术的帮助,从其他数据源训练得到的模型,经过一定的修改和完善,就可以在类似的领域得到复用,这一点大大缓解了数据源不足引起的问题,而这一关键技术就是迁移学习。
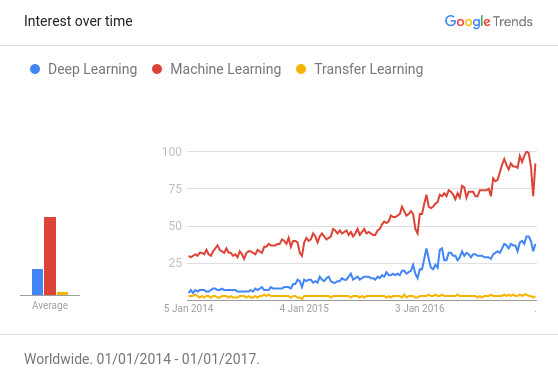
根据 Github 上公布的“引用次数最多的深度学习论文”榜单,深度学习领域中有超过 50% 的高质量论文都以某种方式使用了迁移学习技术或者预训练(Pretraining)。迁移学习已经逐渐成为了资源不足(数据或者运算力的不足)的 AI 项目的首选技术。但现实情况是,仍然存在大量的适用于迁移学习技术的 AI 项目,并不知道迁移学习的存在。如下图所示,迁移学习的热度远不及机器学习和深度学习。
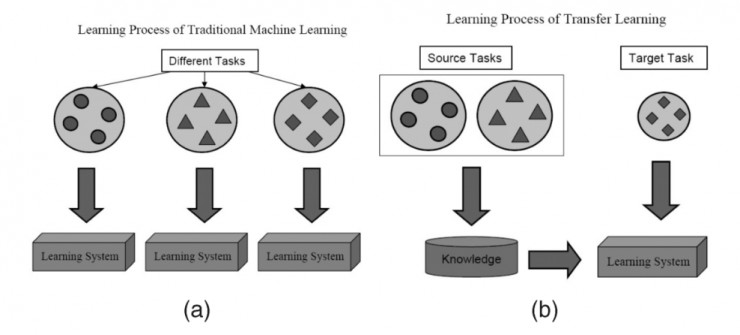
迁移学习的基本思路是利用预训练模型,即已经通过现成的数据集训练好的模型(这里预训练的数据集可以对应完全不同的待解问题,例如具有相同的输入,不同的输出)。开发者需要在预训练模型中找到能够输出可复用特征(feature)的层次(layer),然后利用该层次的输出作为输入特征来训练那些需要参数较少的规模更小的神经网络。由于预训练模型此前已经习得了数据的组织模式(patterns),因此这个较小规模的网络只需要学习数据中针对特定问题的特定联系就可以了。此前流行的一款名为 Prisma 的修图 App 就是一个很好的例子,它已经预先习得了梵高的作画风格,并可以将之成功应用于任意一张用户上传的图片中。
值得一提的是,迁移学习带来的优点并不局限于减少训练数据的规模,还可以有效避免过度拟合(overfit),即建模数据超出了待解问题的基本范畴,一旦用训练数据之外的样例对系统进行测试,就很可能出现无法预料的错误。但由于迁移学习允许模型针对不同类型的数据展开学习,因此其在捕捉待解问题的内在联系方面的表现也就更优秀。如下图所示,使用了迁移学习技术的模型总体上性能更优秀。
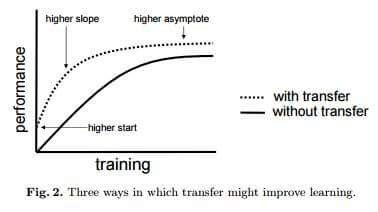
迁移学习到底能消减多少训练数据?

这里以此前网上流行的一个连衣裙图片为例。如图所示,如果你想通过深度学习判断这条裙子到底是蓝黑条纹还是白金条纹,那就必须收集大量的包含蓝黑条纹或者白金条纹的裙子的图像数据。参考上文提到的问题规模和参数规模之间的对应关系,建立这样一个精准的图像识别模型至少需要 140M 个参数,1.2M 张相关的图像训练数据,这几乎是一个不可能完成的任务。
现在引入迁移学习,用如下公式可以得到在迁移学习中这个模型所需的参数个数:
No. of parameters = [Size (inputs) + 1] * [Size (outputs) + 1] = [2048+1]*[1+1]~ 4098 parameters
可以看到,通过迁移学习的引入,针对同一个问题的参数个数从 140M 减少到了 4098,减少了 10 的 5 次方个数量级!这样的对参数和训练数据的消减程度是惊人的。
一个迁移学习的具体实现样例
在本例中,我们需要用深度学习技术对电影短评进行文本倾向性分析,例如“It was great,loved it.”表示积极正面的评论,“It was really stupid.”表示消极负面的评论。
假设现在可以得到的数据规模只有 72 条,其中 62 条没有经过预先的倾向性标记,用来预训练。8 条经过了预先的倾向性标记,用来训练模型。2 条也经过了预先的倾向性标记,用来测试模型。
由于我们只有 8 条经过预先标记的训练数据,如果直接以这样的数据量对模型展开训练,无疑最终的测试准确率将非常低。(因为判断结果只有正面和负面两种,因此可以预见最终的测试准确率可能只有 50%)
为了解决这个难题,我们引入迁移学习。即首先用 62 条未经标记的数据对模型展开通用的情感判断,然后在这一预训练的基础上对本例的特定问题展开分析,复用预训练模型中的部分层次,就可以将最终的测试准确率提升到 100%。下面将从 3 个步骤展开分析。
步骤1
创建预训练模型来分析词与词之间的关系。这里我们通过分析未标记语句中的某一词汇,尝试预测出现在同一句子中的其他词汇。
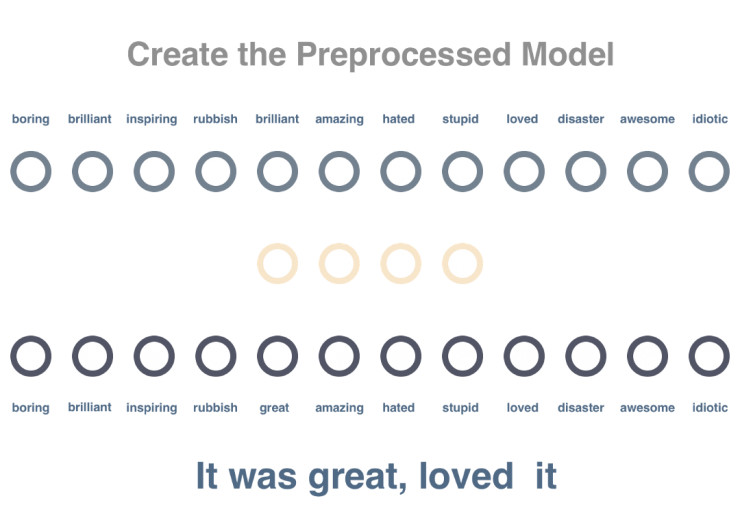
步骤2
对模型展开训练,使得出现在类似上下文中的词汇获得类似的向量表示。在这一步骤中,62 条待处理语句首先会被删除停用词,并被标记解释。之后,针对每个词汇,系统会尝试减小其向量表示与相关词汇的差别,并增加其与不相关词汇的差别。
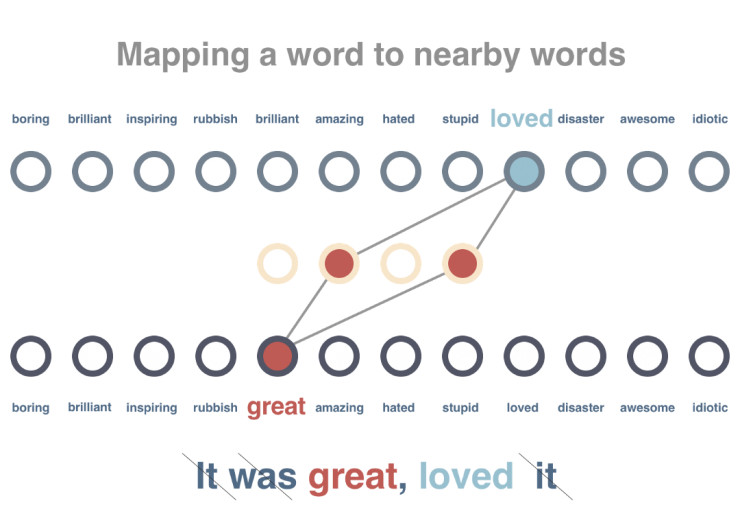
步骤3
预测一个句子的文本倾向性。由于在此前的预训练模型中我们已经得到了针对所有词汇的向量表示,并且这些向量具有用数字表征的每个词汇的上下文属性,这将使得文本的倾向性分析变得更易于实现。
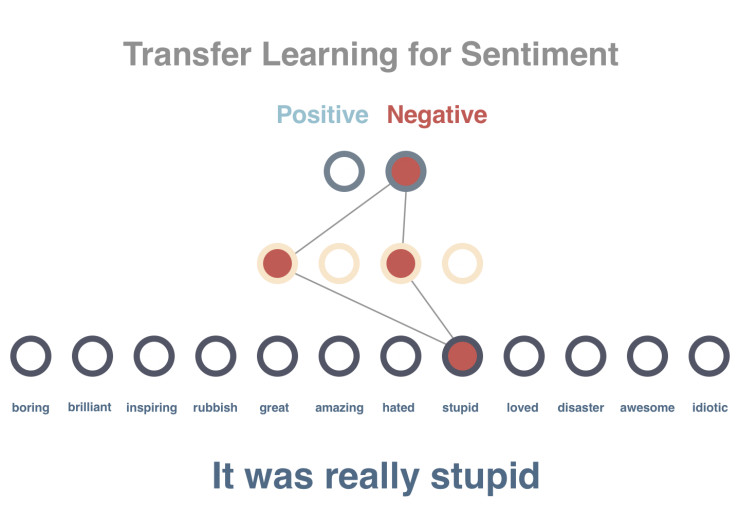
需要注意的是,这里并非直接使用 10 个已经被预先标记的句子,而是先将句子的向量设置为其所有词汇的平均值(在实际任务中,我们将使用类似时间递归神经网络 LSTM 的相关原理)。这样,经过平均化处理的句子向量将作为输入数据导入模型,而句子的正面或负面判定将作为结果输出。需要特别强调的是,这里我们在预训练模型和 10 个被预先标记的句子之间加入了一个隐藏层(hidden layer),用来适配文本倾向性分析这一特定场景。正如你所看到的,这里只用 10 个标记量就实现了 100% 的预测准确率。
当然,必须指出的是,这里展示的只是一个非常简单的模型示意,而且测试用例只有 2 条。但不可否认的一点是,由于迁移学习的引入,确实使得本例中的文本倾向性预测准确率从 50% 提升到了 100%。
本例的完整代码详见如下链接:https://gist.github.com/prats226/9fffe8ba08e378e3d027610921c51a78
迁移学习的实现难点
虽然迁移学习的引入可以显著减少模型对训练数据量的要求,但同时也意味着更多的专业调教。从上面的例子就能看出,只是考虑这些海量的必须硬编码实现的参数数量,以及围绕这些参数进行的繁杂的调试过程,就足够让人望而生畏了。而这也是迁移学习在实际应用中难以进一步推广的重要阻碍之一。这里我们总结了 8 条常见的迁移学习的实现难点。
1. 获取一个相对大规模的预训练数据
2. 选择一个合适的预训练模型
3. 难以排查哪个模型没有发挥作用
4. 不知道需要多少额外数据来训练模型
5. 难以判断应该在什么情况下停止预训练
6. 决定预训练模型的层次和参数个数
7. 代理和服务于组合模型
8. 当获得更多数据或者更好的算法时,预训练模型难以更新
NanoNets 工具
NanoNets 是一个简单方便的基于云端实现的迁移学习工具,其内部包含了一组已经实现好的预训练模型,每个模型有数百万个训练好的参数。用户可以自己上传或通过网络搜索得到数据,NanoNets 将自动根据待解问题选择最佳的预训练模型,并根据该模型建立一个 NanoNets(纳米网络),并将之适配到用户的数据。NanoNets 和预训练模型之间的关系结构如下所示。
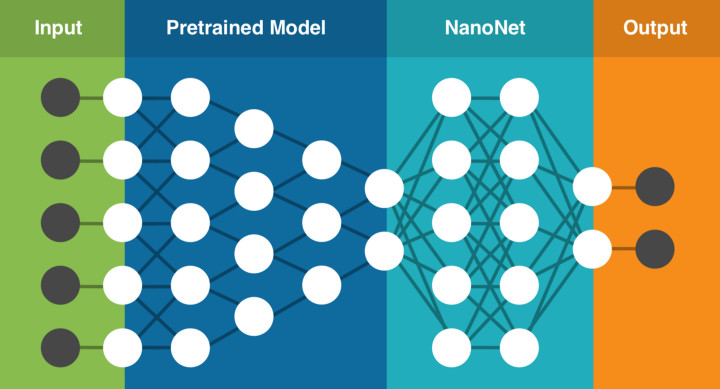
以上文提到的蓝黑条纹还是白金条纹的连衣裙为例,用户只需要选择待分类的名称,然后自己上传或者网络搜索训练数据,之后 NanoNets 就会自动适配预训练模型,并生成用于测试的 web 页面和用于进一步开发的 API 接口。如下所示,图中为系统根据一张连衣裙图片给出的分析结果。

具体使用方法详见 NanoNets 官网:http://nanonets.ai/ 。值得一提的是,由于处于推广期,NanoNets 的 API 接口在 3 月 1 日之前都会免费开放,感兴趣的小伙伴不妨试一试吧。
来源:medium
智能推荐
FMEA七步法-新版FMEA手册六大变化_新版fmea和旧版fmea区别点-程序员宅基地
文章浏览阅读3.4k次。由旧版的“五步法”变为“七步法”,新版FMEA强调“七步法”中的分析结构,力图用结构化的表格固化分析过程,表格包含三级结构关系(上一层级、本层级、下一层级),避免出现以前只关注FMEA表格本身,以及结构不明、层次不清等问题,并支持整个FMEA的分析和应用过程。新版FMEA强调了顾客和组织、组织内部、设计团队与管理层、产品与制造过程,以及系统、子系统、组件、零件等各层级之间的有效沟通和协作,并在七步法中明确提出了针对FMEA活动的结果进行总结和交流的要求,形成FMEA报告,方便内外部沟通使用。_新版fmea和旧版fmea区别点
python竖线运算符-Python中的运算符-程序员宅基地
文章浏览阅读2.4k次,点赞2次,收藏3次。说完常用的数据类型,再来说下运算符。运算符用于将各种类型的数据进行运算,让静态的数据跑起来。编程语言中的运算大致分为以下几个大类:算术运算, 用于加减乘除等数学运算赋值运算,用于接收运算符或方法调用返回的结果比较运算, 用于做大小或等值比较运算逻辑运算,用于做 与、或、非运算位运算, 用于二进制运算每种运算中所包含的符号称为相应的运算符,如 算术运算符、比较运算符等。一、算术运算运算(符)说明实例..._在python中,竖直的符号怎么输入
centos7编译grpc源码_centos grpc 怎么编译-程序员宅基地
文章浏览阅读92次。centos升级gcc v7:_centos grpc 怎么编译
TIM输出比较 P2 PWM控制呼吸灯-程序员宅基地
文章浏览阅读679次,点赞29次,收藏5次。我的理解是xO1 = xIN1 & PWMx;引入PWMx可以更方便的控制特定的电路。四、函数学习/*****单独设置输出比较极性*****///带N的就是高级定时器里互补通道的配置//OC4没有互补通道//结构体初始化也可以设置极性,这里就是单独更改输出极性的,两者效果一样/*****单独修改输出使能参数*****//*****单独更改输出比较模式*****/
少儿编程 2023年12月电子学会图形化编程等级考试Scratch二级真题解析(选择题)_推箱子地图第一行111111,第二行-程序员宅基地
文章浏览阅读151次。2023年12月scratch编程等级考试二级真题选择题(共25题,每题2分,共50分)1、在制作推箱子游戏时,地图是用数字形式储存在电脑里的,下图是一个推箱子地图,地图表示如下:第一行( 111111)第二行( 132231) 第三行( 126621) 第四行( ) 第五行( 152321) 第六行( 111111 ) 根据规律,第四行应该用哪些数字表示A、( 152121 )B、( 162121 )C、( 122121 )D、( 132121 )答案:B考点分析:考查_推箱子地图第一行111111,第二行
Halcon的Hobject和Opencv的Mat数据类型之间的超快速转换方法_halcon和cvmat数据转换-程序员宅基地
文章浏览阅读3.6k次,点赞12次,收藏41次。由于项目需求,需要把部分Opencv代码和Halcon代码联接起来使用,而两种库所使用的基本数据类型是完全不一样的。因此需要一个互转函数来对他们进行转换。我在这篇博客中看到了一种互转方法Halcon 与 OpenCV 图像数据类型转换。这里面所介绍的方法转换速度非常的慢,Halcon转Opencv需要600ms,而opencv转halcon要10ms,这对于工业应用的项目来说实在是太慢了。仔细研读后,发现这份代码使用Halcon的 GetGrayval() 函数来对HImage进行像素值遍历读取,这_halcon和cvmat数据转换
随便推点
电能量远程数据采集系统的设计与实现_电能量前置及数据处理服务器-程序员宅基地
文章浏览阅读2.6k次。 肖 鲲 李晓明 董丽娟 (武汉大学电气工程学院 武汉 430072) 摘要 本文介绍了电能量远程数据采集系统的设计方案,说明了如何利用通信控件和线程类实现远程数据采集的方法,并给出了程序实例。 关键词 远程数据采集 多线程 ActiveX1 引言 随着电力系统自动化程度的提高,以及计算机技术在电力系统中日益广泛的应用。传统的电量计费方式由于其效率低、投_电能量前置及数据处理服务器
封神台-杂项11:这是我最喜欢的女明星-程序员宅基地
文章浏览阅读322次,点赞7次,收藏11次。打开发现就是一张图片,根据提示这是一个女明星,直接搜狗识图。找到外文名,这就是flag。发现是邱淑贞,直接百科,
IEEE--DSConv: Efficient Convolution Operator 论文翻译_dsconv: effcient convolution operator-程序员宅基地
DSConv是一种高效的卷积操作符,可以替代传统的卷积操作符,具有高准确性、低内存使用和灵活性。通过对CIFAR10图像的分类实验,证明了DSConv的有效性。
Vue进阶(幺陆伍)PhantomJS 实战讲解_vue phantomjs-程序员宅基地
文章浏览阅读440次。在前期博文《Vue进阶(五十六):vue-cli 脚手架 karma.conf.js 配置文件详解》中讲解了文件用于配置前端项目自动化测试信息。// 这里使用的是PhantomJS作为浏览器测试环境,这个插件支持 DOM, CSS, JSON, Canvas, and SVG 的解析其中,使用了PhantomJS作为无头浏览器测试环境。PhantomJS具体作用是什么呢?本篇博文带你一探究竟。_vue phantomjs
CSS3做出条纹大背景-程序员宅基地
文章浏览阅读168次。㈠实现不等宽背景条纹实现如上图所示的效果,代码如下: 1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="UTF-8"> 5 <style type="text/css"> 6 .con..._css3 条纹背景
IT项目实施流程及每个阶段输出的文档_项目管理各个阶段输出文档-程序员宅基地
文章浏览阅读3.3k次,点赞2次,收藏12次。IT项目实施流程及每个阶段输出的文档_项目管理各个阶段输出文档