2. Web后端开发-学习笔记-程序员宅基地
该笔记包含了Maven,Spring Boot,MySQL和MyBatis的相关内容,为笔者学习黑马程序员Web开发时做的笔记,便于知识遗漏时能及时查看查漏补缺。如果能帮助到您,那便更好了。
2.1 Maven
管理和构建Java项目的开源工具
2.1.1 Maven的作用
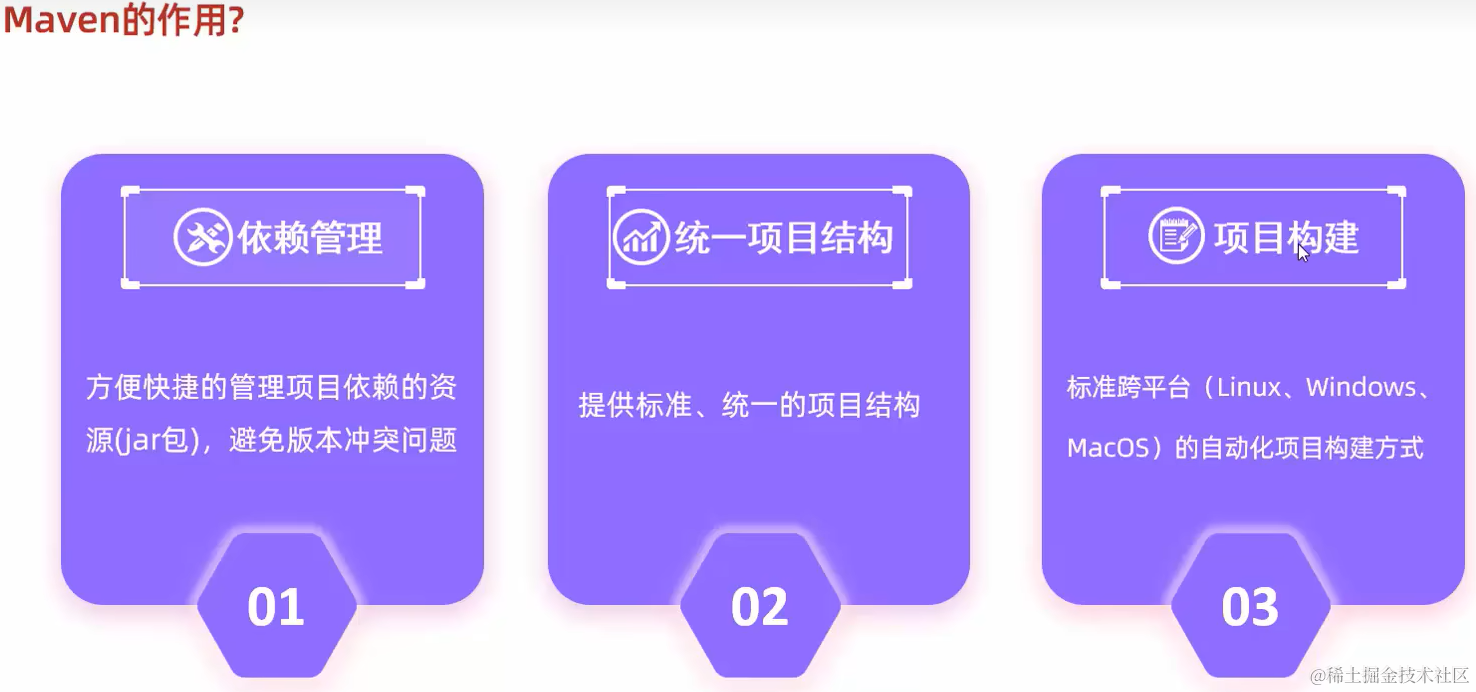
2.1.2 Maven的基本思想
- 通过Maven自带的各种插件完成项目的标准化构建与各种文件的生成和管理
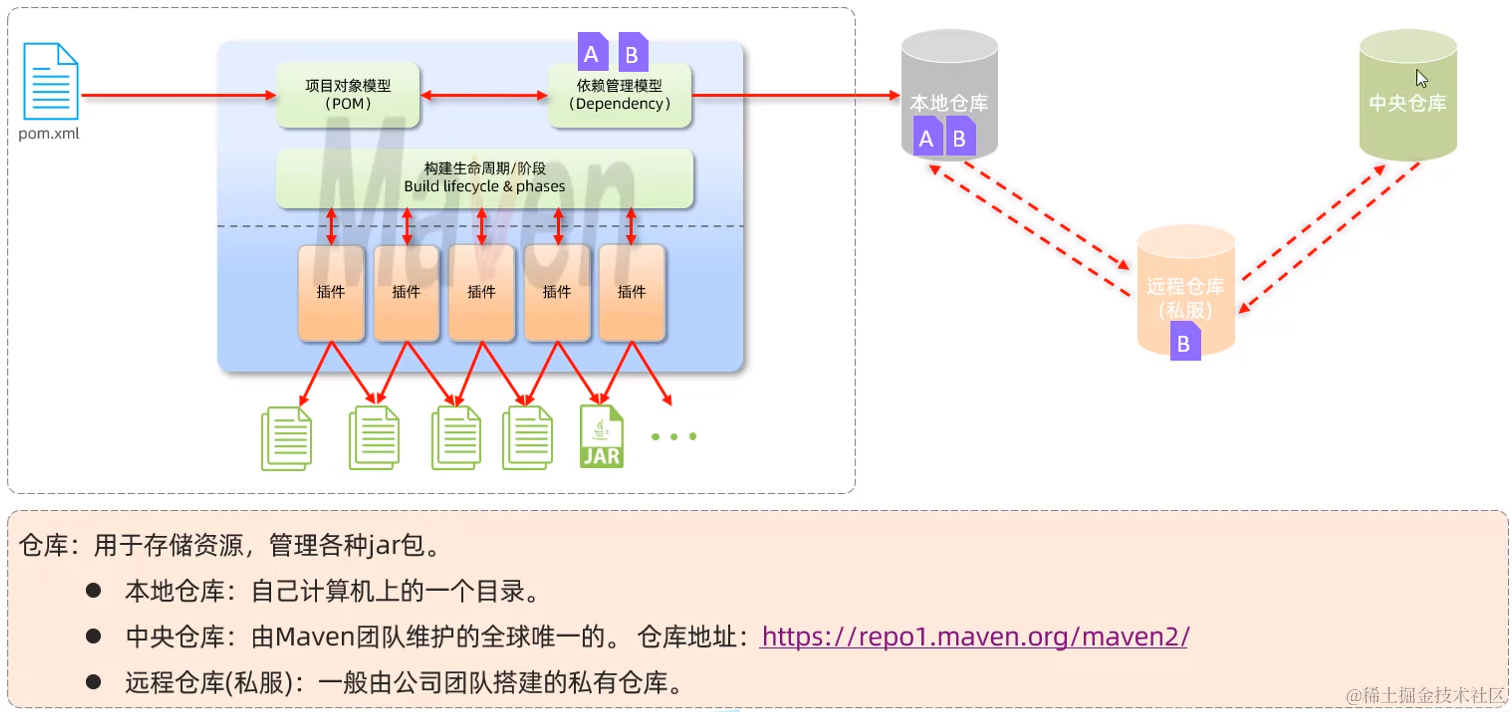
- 项目对象模型POM(Porject Object Model),Maven的核心思想。通过pom.xml中配置的信息来描述Java工程
- pom.xml中可添加依赖信息来进行依赖管理(pom.xml中配置的依赖会先在本地仓库中寻找,本地仓库中无就从中央仓库或者远程/私有仓库拉取)
2.1.3 maven依赖管理
1. 依赖配置
<!-- 所有的依赖都在pom.xml中配置 -->
<dependencies>
<dependency>
<groupId>ch.qos.logback</groupId> 项目依赖的组织的唯一标识符
<artifactId>logback-classic</artifactId> 项目依赖的模块或库的名称
<version>1.4.5</version> 依赖的具体版本
</dependency>
</dependencies>
不知道groupId和version可在https://mvnrepository.com/中查看(version可选择Usage最高的版本)
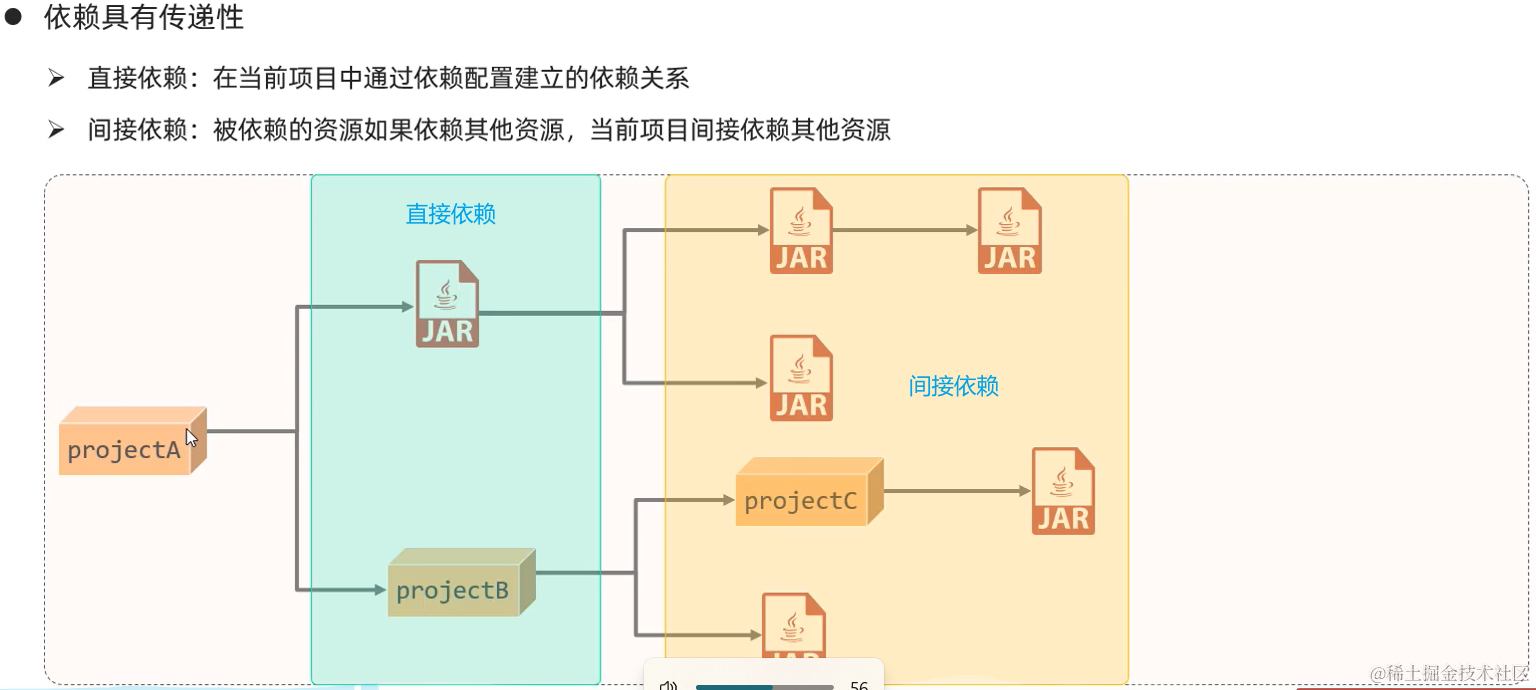
2. 依赖传递
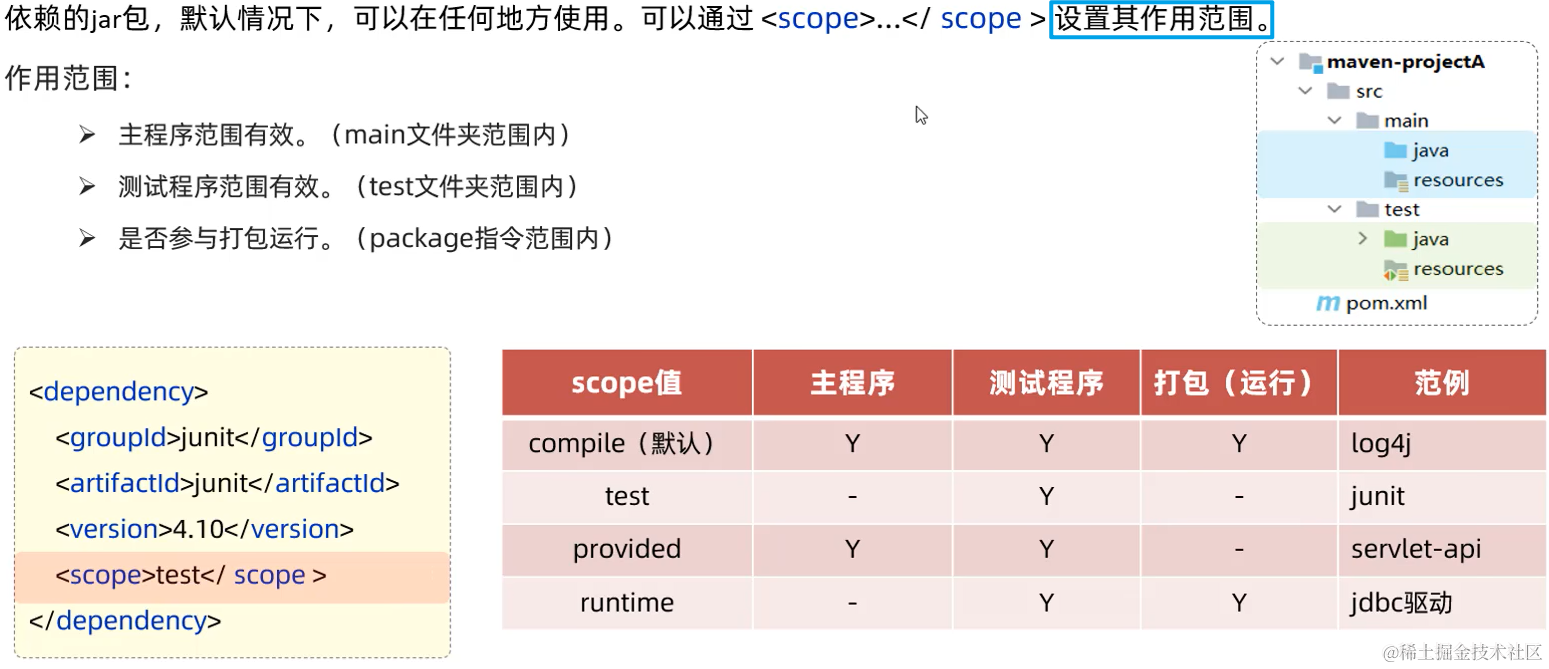
3. 依赖范围
4. 生命周期

2.2 Web入门
从Spring Boot开始,并贯穿始终
2.2.1 Spring生态

2.2.2 SpringBoot Web快速入门
创建好一个SpringBoot项目后,会自动生成一个启动类。要想启动SpringBoot项目就直接运行该启动类
package com.zzy.springtest01;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
// 启动类——用于启动SpringBoot工程
@SpringBootApplication
public class SpringTest01Application {
public static void main(String[] args) {
SpringApplication.run(SpringTest01Application.class, args);
}
}
接下来我们在/com.zzy.springtest01目录下连包带类创建controller.HelloController,用于处理浏览器请求。
当浏览器url输入localhost:8080/response(SpringBoot项目默认占用8080端口)后,HelloController能返回给浏览器一段信息。
controller层的核心功能就是接收浏览器请求,并响应
package com.zzy.springtest01.controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* 请求处理类
*/
@RestController
public class HelloController {
@RequestMapping("/response")
public String response() {
String res = "进行请求处理...";
System.out.println(res);
return res;
}
}
@RestController:指定该类为Spring的请求处理类/控制器类,用于处理HTTP请求,并返回数据而非视图
@RequestMapping(/response):表示当浏览器访问/response时,就会调用该函数
2.2.3 HTTP协议
1. 概述

2. 请求协议(浏览器 -> 服务器)
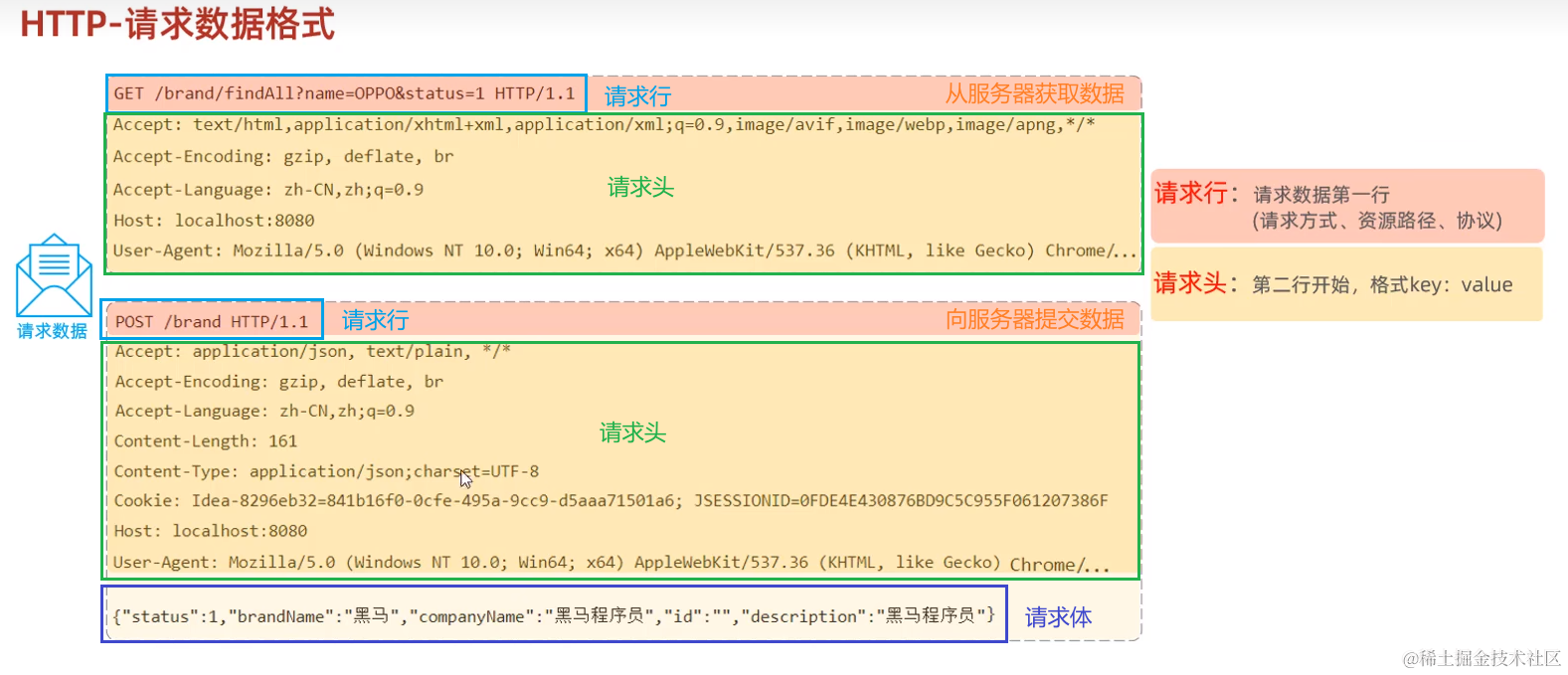

3. 响应协议(服务器 -> 浏览器)


4. 协议解析
程序员直接解析请求的内容,从字符串中提取出请求行、请求头、请求体,以及在输出流中输出响应行、响应头和响应体是非常麻烦的。
很多公司开发了专门的Web服务器来进行HTTP请求/响应解析,如Apache Tomcat
2.2.4 Apache Tomcat
Tomcat是一个Web服务器,也叫Servlet容器
Web服务器是一个软件,对HTTP协议的操作进行封装,使得程序员不必直接对协议进行操作
我们只需在自己的服务器中安装一个Web服务器(如Tomcat),将开发好的应用直接部署在Tomcat上
1. 将自己的程序部署到Tomcat中
将自己的程序资源(比如myApp文件夹)拷贝到Tomcat下的webapps文件夹下就可以了。浏览器访问localhost:8080/myApp(Tomcat默认占用8080端口,Java有时也占用8080端口,易冲突)
2. Spring内嵌Tomcat
SpringBoot中开发web项目都要引入spring-boot-starter-web依赖,这一依赖内嵌了Tomcat服务器,并占用8080端口(就不用自己本地下载安装Tomcat了)(注:spring-boot-starter称为起步依赖,是每个特定项目都要引入的依赖。pom.xml中不会注明版本,因为这些依赖都是交由父工程由Spring团队统一管理)
<!-- 该项目的父工程 -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.1.5</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<!-- 每个版本的父工程都指定了各起步依赖的版本信息,无需自己操心 -->
2.2.5 请求响应
浏览器GET和POST请求,以及对请求的响应
1. 概述
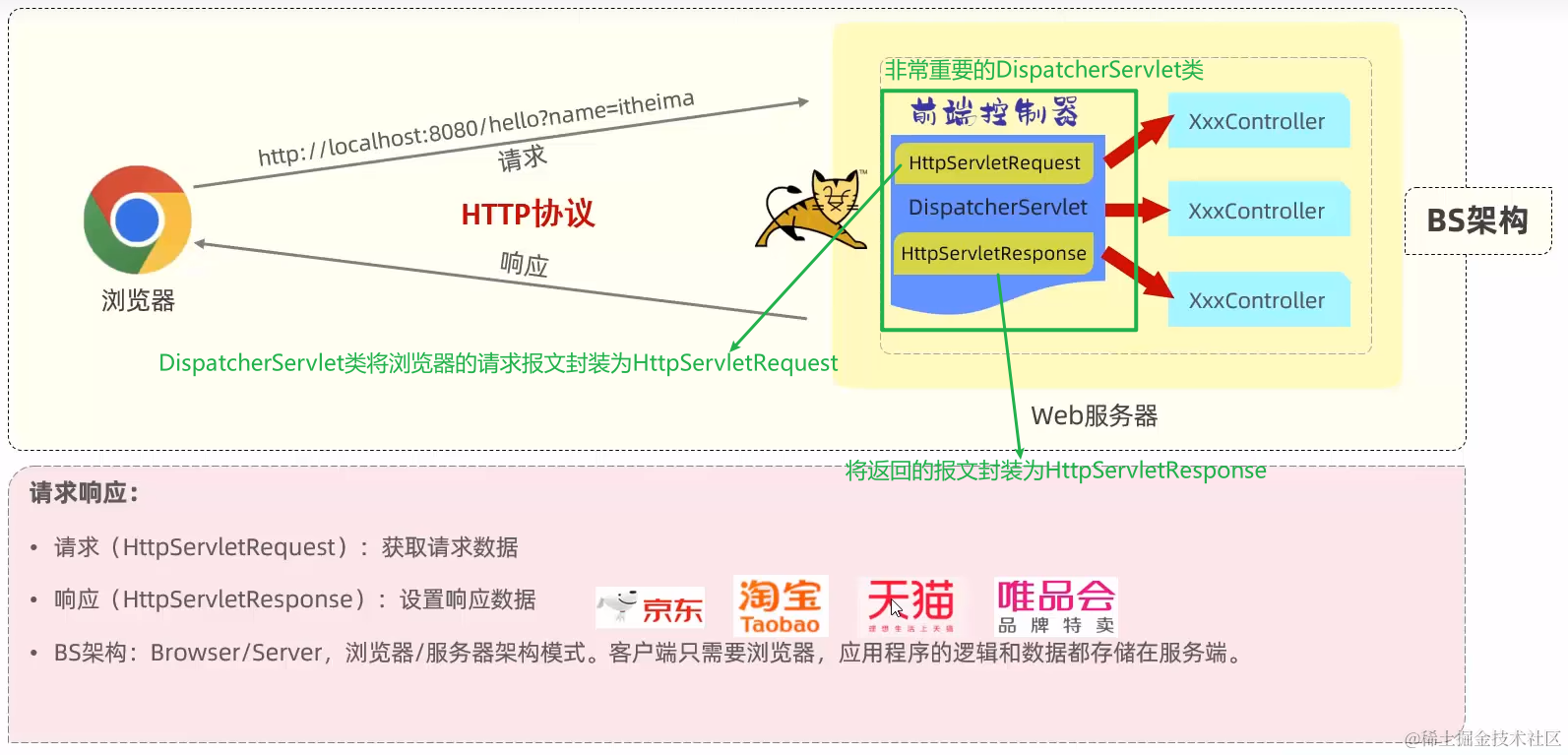
Tomcat也被称为Servlet容器
SpringBoot提供了一项非常核心的程序:DispatcherServlet类,也被称为核心控制器或者前端控制器
它将浏览器的HTTP请求封装到HttpServletRequest类中,将返回给浏览器的数据封装到HttpServletResponse类中,简化了HTTP协议的使用
2. 请求-Postman接口测试工具
接口测试工具。缺少前端时,后端开发人员每开发完一个接口,就可以用Postman进行测试
Postman实质上模拟Chrome,提出GET或者POST请求,并接受返回数据
!!!注意:浏览器地址栏的请求都是GET请求
3. 请求-简单参数
原始方式:通过
HttpServletRequest对象获取请求参数
package com.zzy.springtest01.controller;
import jakarta.servlet.http.HttpServletRequest;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class GetRequestParams {
@RequestMapping("/params")
public String getRequestParams(HttpServletRequest httpServletRequest){ // 声明一个HttpServletRequest对象来接受浏览器请求报文
String name = httpServletRequest.getParameter("name"); // 调用HttpServletRequest对象的getParameter()返回请求的参数(String型)
String age = httpServletRequest.getParameter("age");
String str = "获取到数据 name="+name+" age="+age;
System.out.println(str);
return str;
}
}
// Postman GET请求:http://localhost:8080/params?name=Tom&age=21
基于
SpringBoot的接收方式:要求形参中的参数名称(name, age)要和请求的参数名称(name, age)一致,SpringBoot才会一一对应
// 基于SpringBoot来获取请求参数
@RequestMapping("/params")
public String getRequestParams(String name, Integer age){ // 直接在方法形参中指定各参数,SpringBoot会自动进行类型转换
String str = "name = "+name+" age = "+age;
System.out.println(str);
return str;
}
// Postman GET请求:http://localhost:8080/params?name=Tom&age=21
4. 请求-实体参数
当使用基于SpringBoot的接收方式接收简单参数时,参数数量较多不方便,则可用实体类来接收参数
实体类: Java中不包含业务逻辑的单纯用来存储数据的 java类,定义了一系列存储数据的属性以及简单的
set(), get(),toString()方法
com.zzy.springtest01
|
|
controller
| |
| RequestHandler.java
|
pojo
|
User.java
// User.java
// pojo包下存放实体类
public class User {
private String name; // !!!注意,实体类的属性取名要和请求的参数的名称一样,Spring才能一一对应
private Integer age;
public void setName(String name) {
this.name = name;
}
public void setAge(Integer age) {
this.age = age;
}
public String getName() {
return name;
}
public Integer getAge() {
return age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + ''' +
", age=" + age +
'}';
}
}
// RequestHandler.java
package com.zzy.springtest01.controller;
import com.zzy.springtest01.pojo.User;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* 请求处理类
*/
@RestController
public class RequestHandle {
@RequestMapping("/getParamsPOJO")
public String getParamsPOJO(User user){ // 直接用实体类来接收请求参数
System.out.println(user);
return user.toString();
}
}
// Postman GET http://localhost:8080/getParamsPOJO?name=Tom&age=21

5. 请求-数组集合参数
在表单中,我们常会遇到多选框,如hobby栏可以多选game, drama, running等等。在GET请求时,请求参数会是:
hobby=game&hobby=drama&hobby=running。这时,就可以使用数组来接收参数,或者使用集合来接收参数
// 使用数组来接收参数
// Postman GET http://localhost:8080/arrayParams?hobby=java&hobby=python&hobby=coding&hobby=exercising
// 通过数组来接收相同的参数
@RequestMapping("/arrayParams")
public String arrayParams(String[] hobby){ // 注意方法中形参的名称必须和请求参数名称一致,Spring才能识别
String str = Arrays.toString(hobby); // 数组转字符串的方法
System.out.println(str);
return str;
}
// 使用集合来接收参数
// 将方法的形参改为:
@RequestParam List<String> hobby
// !!!注意
// @RequestParam用于绑定请求参数到形参hobby
// 形参的集合名称(hobby)要和请求参数的名称(hobby)一致
6. 请求-日期参数
有时我们前端会提交时间信息给服务器,时间的格式多种多样
// 接收时间参数
// Postman GET http://localhost:8080/dateParams?paramDate=2023-11-01 20:05:00
@RequestMapping("/dateParams")
public String dateParams(@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")LocalDateTime paramDate){
String str = paramDate.toString();
System.out.println(str);
return str;
}
// @DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")指定了时间的格式
// LocalDateTime是一个官方的java类
7. 请求-JSON参数
当浏览器发出json类型的请求参数时,使用的是
POST请求,请求参数放在请求体(RequestBody)中
// Postman POST
/*
{
"name":"Tom",
"age":21,
"address":{
"province":"Sichuan",
"city":"Chengdu"
}
}
*/
// pojo包下
// Address.java
public class Address{
private String province;
private String city;
setter();
getter();
toString();
}
// Person.java
public class Person{
private String name;
private Integer age;
private Address address;
setter();
getter();
toString();
}
// controller包下
...
// 接收JSON格式数据
@RequestMapping("/jsonParam")
public String jsonParam(@RequestBody Person person){
String str = person.toString();
System.out.println(person);
return str;
}
...
8. 请求-路径参数
有时客户端url地址http://localhost:8080/pathParam/
1~...,这里参数变成了url地址的一部分,如何获取到这样的参数呢?
// 接受路径参数 http://localhost:8080/pathParam/1
@RequestMapping("/pathParam/{id}") // {id}表示id不是固定值
public String pathParam(@PathVariable Integer id){ // 指定id是一个PathVariable
System.out.println(id);
return id.toString();
}
// 接受多个路径参数 http://localhost:8080/pathParam/1/Tom
@RequestMapping("/pathParam/{id}/{name}")
public String pathParam(@PathVariable Integer id, @PathVariable String name){ // 指定id是一个PathVariable
System.out.println(id+name);
return "OK";
}
!!!注意:我们上面写的每一个方法都是一个功能接口
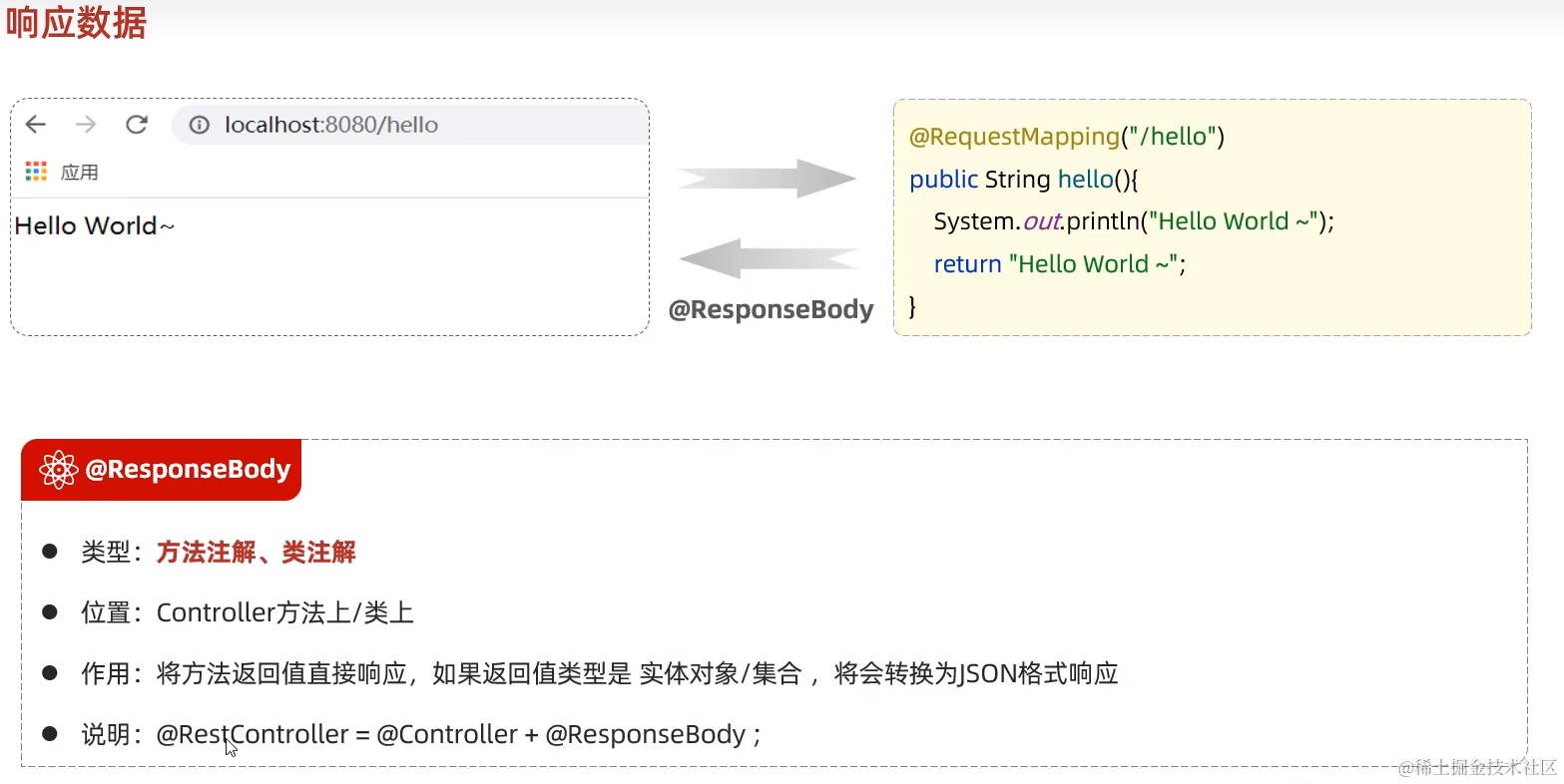
9. 响应-@ResponseBody & 统一响应结果
接收完各式各样的请求数据后,我们来设置响应结果
响应依赖于@ResponseBody注解。前8小节我们接收到浏览器请求数据后都给了浏览器响应,但好像没有用到@ResponseBody?
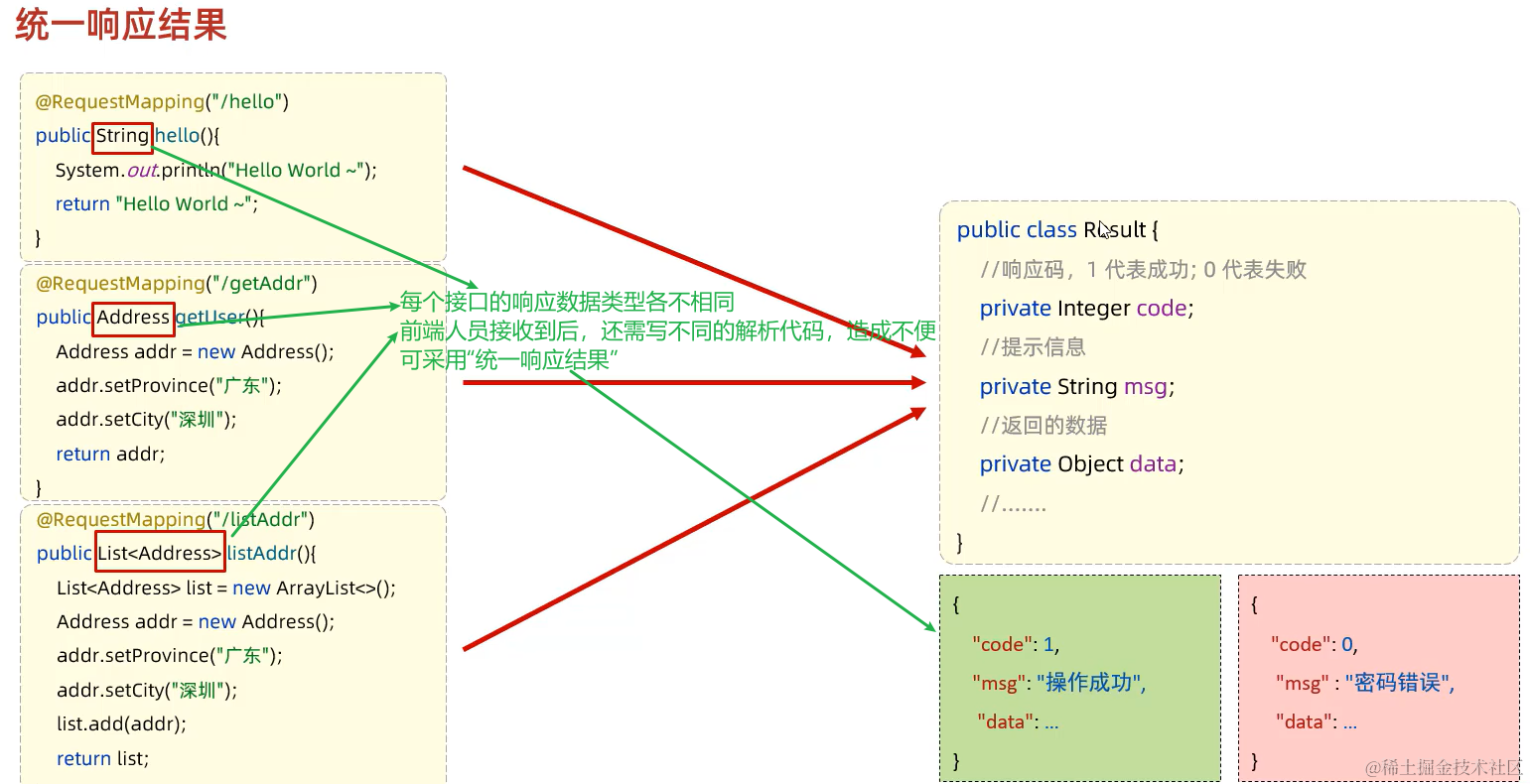
/**
* 创建一个统一响应结果封装类Result.java(可放在pojo包下)
*/
public class Result {
private Integer code ;//1 成功 , 0 失败
private String msg; //提示信息
private Object data; //响应的数据 data
public Result() { // 无参构造方法
}
public Result(Integer code, String msg, Object data) { // 有参构造方法
this.code = code;
this.msg = msg;
this.data = data;
}
public Integer getCode() {
return code;
}
public void setCode(Integer code) {
this.code = code;
}
public String getMsg() {
return msg;
}
public void setMsg(String msg) {
this.msg = msg;
}
public Object getData() {
return data;
}
public void setData(Object data) {
this.data = data;
}
public static Result success(Object data){ // success的静态方法(带返回值)
return new Result(1, "success", data);
}
public static Result success(){ // success的静态方法(无返回值)
return new Result(1, "success", null);
}
public static Result error(String msg){ // error的静态方法
return new Result(0, msg, null);
}
@Override
public String toString() {
return "Result{" +
"code=" + code +
", msg='" + msg + ''' +
", data=" + data +
'}';
}
}
// 这样就可以将响应结果统一
// 接收时间参数
@RequestMapping("/dateParams")
public Result dateParams(@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")LocalDateTime paramDate){
return Result.success(paramDate);
}
// 接收JSON格式数据
@RequestMapping("/jsonParam")
public Result jsonParam(@RequestBody Person person){
return Result.success(person);
}
// 接受路径参数
@RequestMapping("/pathParam/{id}")
public Result pathParam(@PathVariable Integer id){
return Result.success(id);
}
10. 响应-案例
前端发起GET请求,请求获取员工信息。后端读取员工信息emp.xml中的数据,修改gender为“男”/“女”,job为“讲师”,“班主任”,“就业指导”,将最终结果返回给前端。
<!-- emp.xml -->
<?xml version="1.0" encoding="UTF-8" ?>
<emps>
<emp>
<name>金毛狮王</name>
<age>55</age>
<image>https://web-framework.oss-cn-hangzhou.aliyuncs.com/web/1.jpg</image>
<!-- 1: 男, 2: 女 -->
<gender>1</gender>
<!-- 1: 讲师, 2: 班主任 , 3: 就业指导 -->
<job>1</job>
</emp>
<emp>
<name>白眉鹰王</name>
<age>65</age>
<image>https://web-framework.oss-cn-hangzhou.aliyuncs.com/web/2.jpg</image>
<gender>1</gender>
<job>1</job>
</emp>
<emp>
<name>青翼蝠王</name>
<age>45</age>
<image>https://web-framework.oss-cn-hangzhou.aliyuncs.com/web/3.jpg</image>
<gender>1</gender>
<job>2</job>
</emp>
<emp>
<name>紫衫龙王</name>
<age>38</age>
<image>https://web-framework.oss-cn-hangzhou.aliyuncs.com/web/4.jpg</image>
<gender>2</gender>
<job>3</job>
</emp>
</emps>
// 查看前端请求的路径
axios.get('/listEmp').then(res=>{
if(res.data.code){
this.tableData = res.data.data;
}
});
//前端请求路径为 /listEmp
// empController.java
package com.zzy.springtest01.controller;
import com.zzy.springtest01.pojo.Emp;
import com.zzy.springtest01.pojo.Result;
import com.zzy.springtest01.utils.XmlParserUtils;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController
public class EmpController {
@RequestMapping("/listEmp")
public Result list() {
// 1. 加载并解析emp.xml
String file = this.getClass().getClassLoader().getResource("emp.xml").getFile(); // 动态加载文件
System.out.println(file);
List<Emp> empList = XmlParserUtils.parse(file, Emp.class); // 黑马提供的xml解析工具类
// 2. 对数据进行处修改(gender, job)
empList.stream().forEach(emp -> {
// 2.1 处理gender
if (emp.getGender().equals("1")) {
emp.setGender("男");
} else {
emp.setGender("女");
}
// 2.2 处理job
if (emp.getJob().equals("1")) {
emp.setJob("讲师");
} else if (emp.getJob().equals("2")) {
emp.setJob("班主任");
} else if (emp.getJob().equals("3")) {
emp.setJob("就业指导");
}
});
// 3. 响应请求
return Result.success(empList);
}
}
empList.stream().forEach( emp -> {......} );这里用到了List类中自带的遍历forEach()方法。
forEach()方法中使用了lambda表达式来编写匿名函数
forEach( emp -> { 对遍历的每个对象emp进行的操作 } )
!!!注意:前端项目可以放在
resource/static目录下。后端启动后,前端可以访问浏览器localhost:8080/emp.html(无需加/static/)
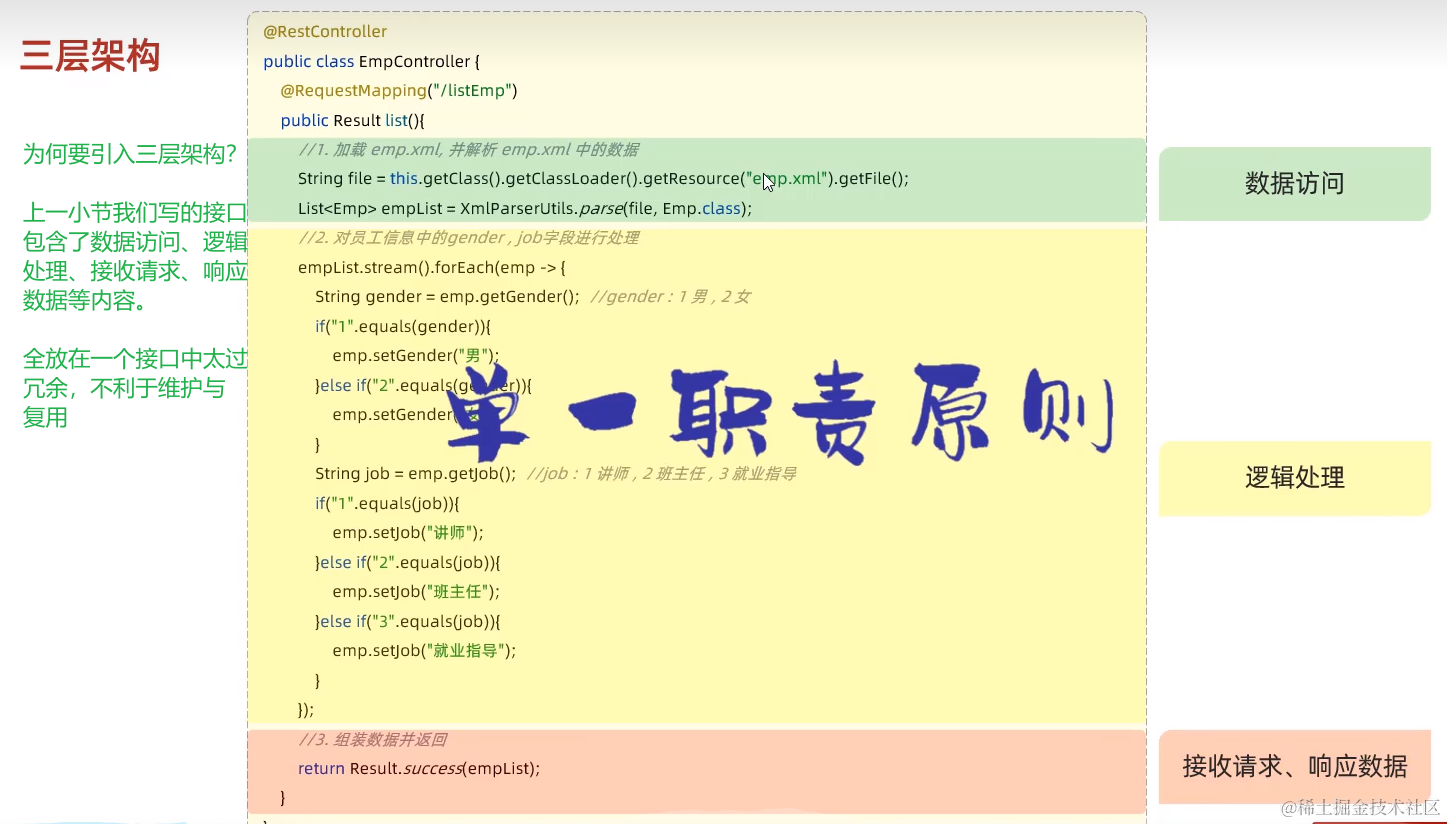
2.2.6 分层解耦
1. 三层架构
为何引入三层架构?
简化接口的设计
便于接口维护与复用(比如说,目前我能够访问xml文件数据,但现在我想扩展功能:既能访问xml数据,又能访问云端数据,还能访问数据库中的数据,不分层的话,逻辑处理就会很复杂)
尽量使得各接口的职责单一
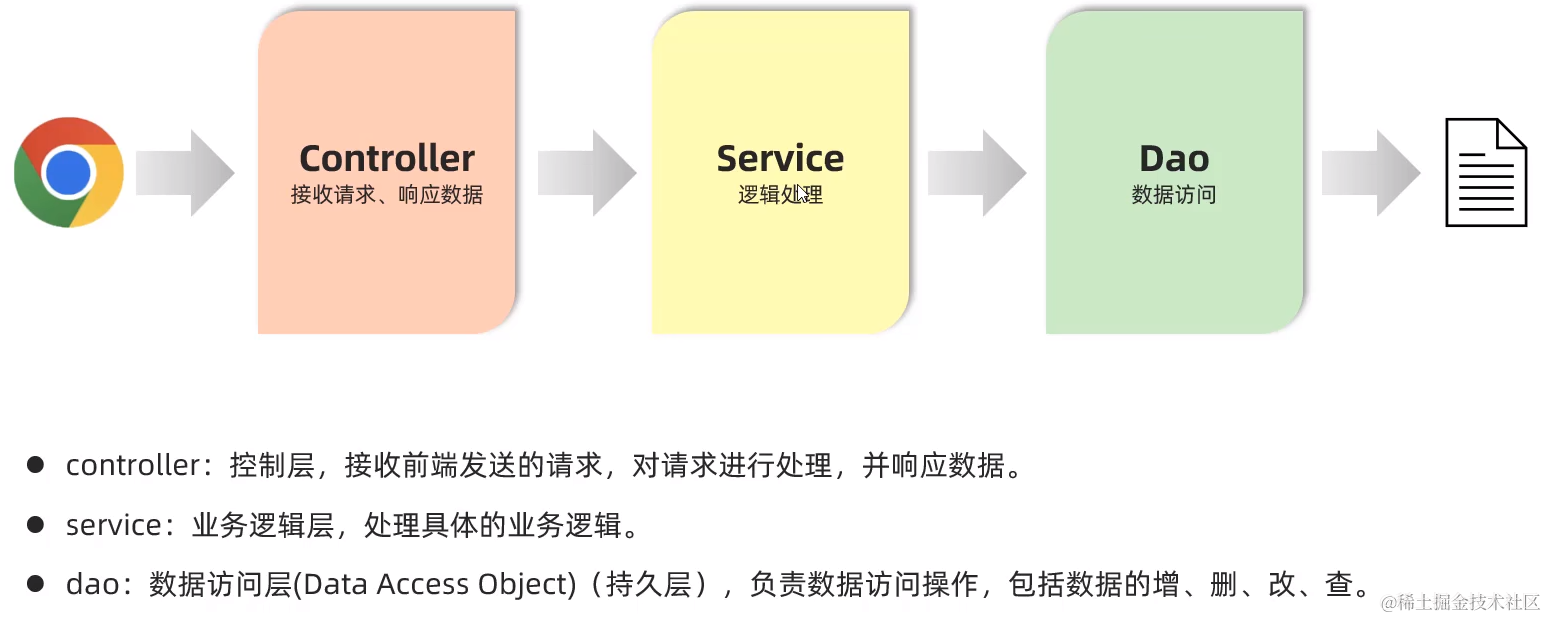
- controller层:接收请求,调用对应的数据访问与逻辑处理程序,最后响应请求
- service层:已得到要处理的数据,进行处理并返回处理后的数据
- dao层:只专注于如何获取数据
三层架构具体内容:
对响应案例进行修改:
将原接口的三大部分:数据访问、逻辑处理、响应请求分为三层
数据访问:
// dao层
// 先创建数据访问的接口,定义数据访问的接口方法。再对接口进行不同实现
/**
* dao层的接口
* 只关注如何加载数据
*/
public interface LoadData {
/**
* 加载数据
* @return 加载后的数据(原始数据)
*/
public List<Emp> empList();
}
// 再用不同方式实现这个接口的方法
// LoadDataV1.java:第一种实现数据访问接口的具体实现
public class LoadDataV1 implements LoadData {
@Override
public List<Emp> empList() {
String file = this.getClass().getClassLoader().getResource("emp.xml").getFile(); // 动态加载文件
System.out.println("file laods successfully: " + file);
List<Emp> empList = XmlParserUtils.parse(file, Emp.class);
return empList;
}
}
逻辑处理:
// service层
// 先创建逻辑处理的接口,定义逻辑处理的接口方法。再对逻辑处理接口进行不同实现
/**
* 修改数据的接口
*/
public interface ModifyData {
/**
* 修改数据
* @return 返回修改好的数据
*/
public List<Emp> modifyData();
}
public class ModifyDataV1 implements ModifyData {
private LoadData loadData = new LoadDataV1(); // 获取加载数据的类
@Override
public List<Emp> modifyData() {
List<Emp> empList = loadData.empList(); // 获取加载好的数据
empList.stream().forEach(emp -> {
// 2.1 处理gender
if (emp.getGender().equals("1")) {
emp.setGender("男");
} else {
emp.setGender("女");
}
// 2.2 处理job
if (emp.getJob().equals("1")) {
emp.setJob("讲师");
} else if (emp.getJob().equals("2")) {
emp.setJob("班主任");
} else if (emp.getJob().equals("3")) {
emp.setJob("就业指导");
}
});
return empList;
}
}
响应请求:
@RestController
public class EmpController {
@RequestMapping("/listEmp")
public Result list() {
// 调用对应请求处理方法,响应请求
return Result.success(new ModifyDataV1().modifyData());
}
}
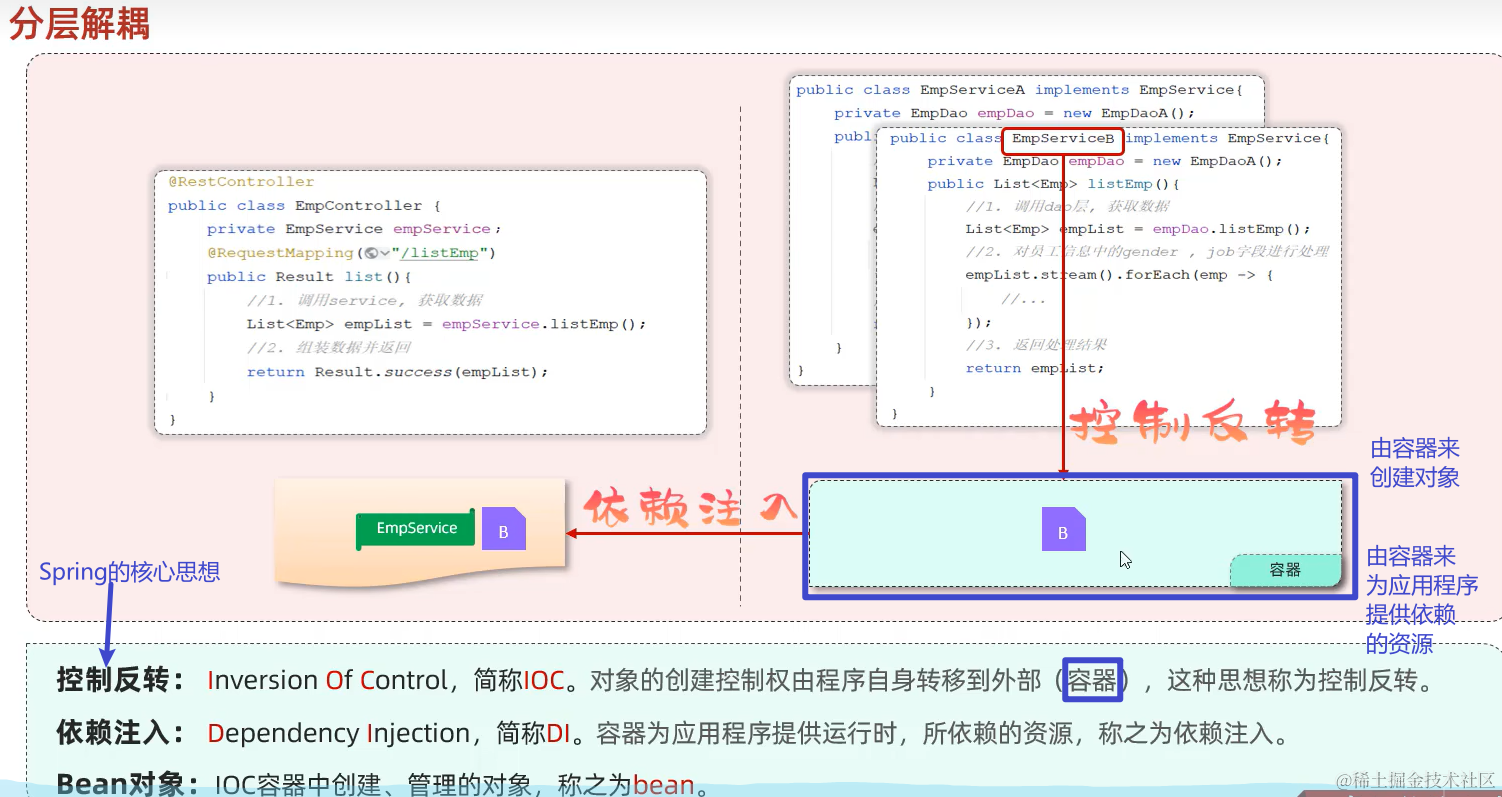
2. 分层解耦
内聚: 软件中各个功能模块内部的功能联系
耦合: 衡量软件中各个层/模块之间的依赖、关联的程度
我们追求高内聚,低耦合
在上一节三层架构中,我们将代码分为dao层、service层、controller层。每一层都只专注于自己的功能。
在controller层中,我们new ModifyDataV1().modifyData(),即创建了service层的一个对象,这称之为耦合。
如果我们想使用另一个业务逻辑,则需对service层进行修改,并且controller层创建的对象也要进行修改,不想这样,要对模块之间解耦。
Solution:
控制反转 inversion of control
依赖注入 dependency injection
Bean对象:容器中创建管理的对象
3. IOC & DI入门
如何实现控制反转IOC和依赖注入DI:
控制反转:
service层的ModifyDataV1.java依赖dao层的LoadDataV1.java
在LoadDataV1类上加上@Component注解,表示该类交由IOC容器管理
controller层的EmpController.java依赖service层的ModifyDataV1.java
在ModifyDataV1类上加上@Component注解,表示该类交由IOC容器管理
依赖注入:
ModifyDataV1中声明LoadDataV1对象时,无需new,直接:
@Autowired
private LoadData obj; // IOC容器知道给obj赋为一个LoadDataV1对象
EmpController中声明ModifyData对象时,无需new,直接:
@Autowired
private ModifyData obj; // IOC容器知道给obj赋为一个ModifyDataV1对象
IOC & DI实现解耦了吗?
当前我的service层有一个实现:ModifyDataV1类,我想创建一个新的实现ModifyDataV2。只需取消ModifyDataV1类上的@Component注解,在ModifyDataV2类上加上@Component注解就行,这样controller层使用@Autowired声明ModifyData对象时就知道,我们需要的是ModifyDataV2
注:Bean的声明

2.3 MySQL
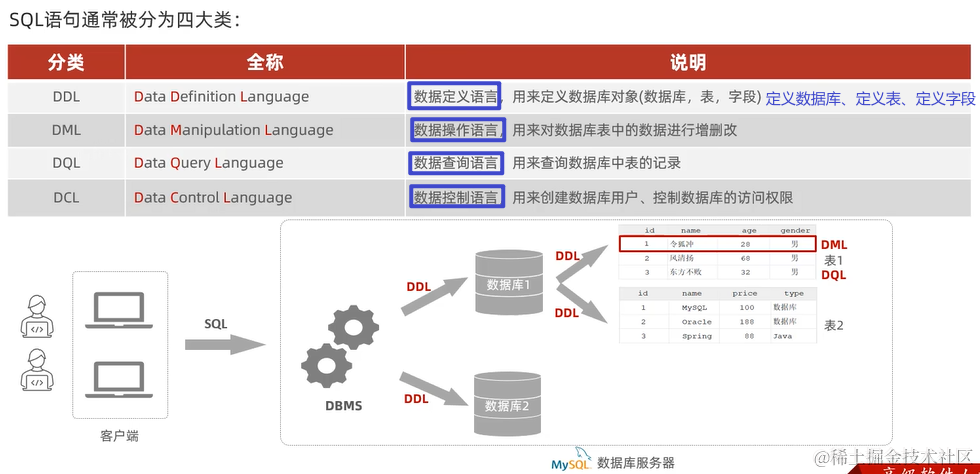
2.3.1 SQL简介

!!!注意:SQL语句记得加上
;
2.3.2 DDL(数据定义语言)
DataBase Definition Language
!!!注意:DataBase和Schema是一样的意思
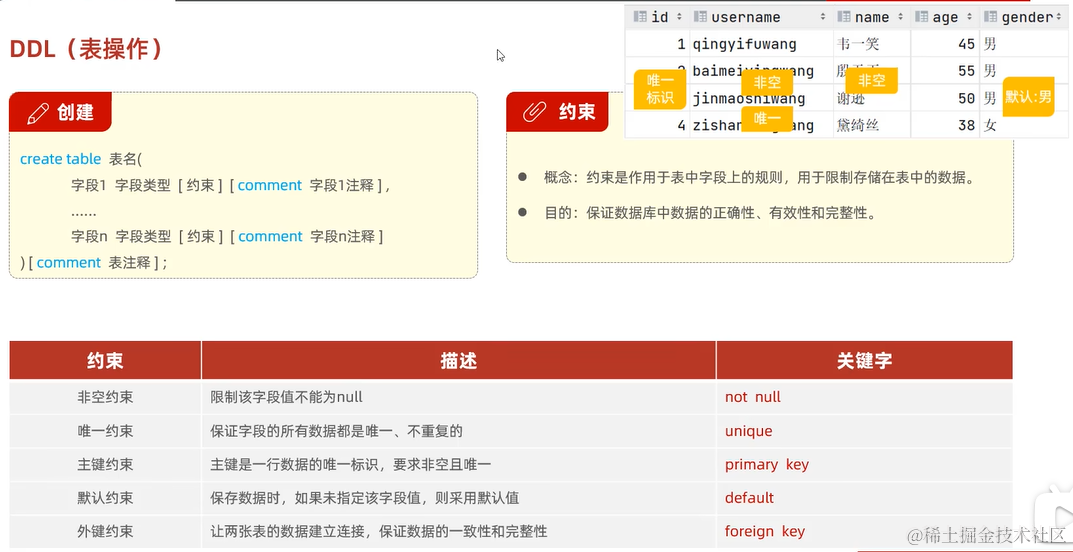
1. 数据库操作

2. 表操作
3. 数据类型
MySQL支持3大类数据类型
-
数值类型

-
字符串类型
-

-
日期时间类型
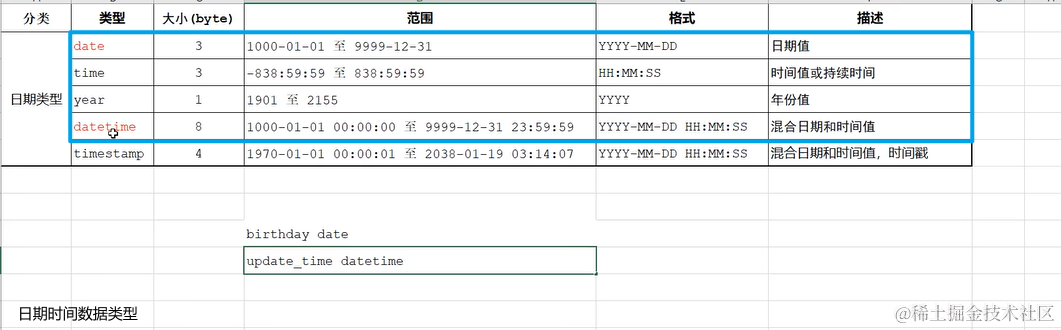
4. 创建表的一般步骤
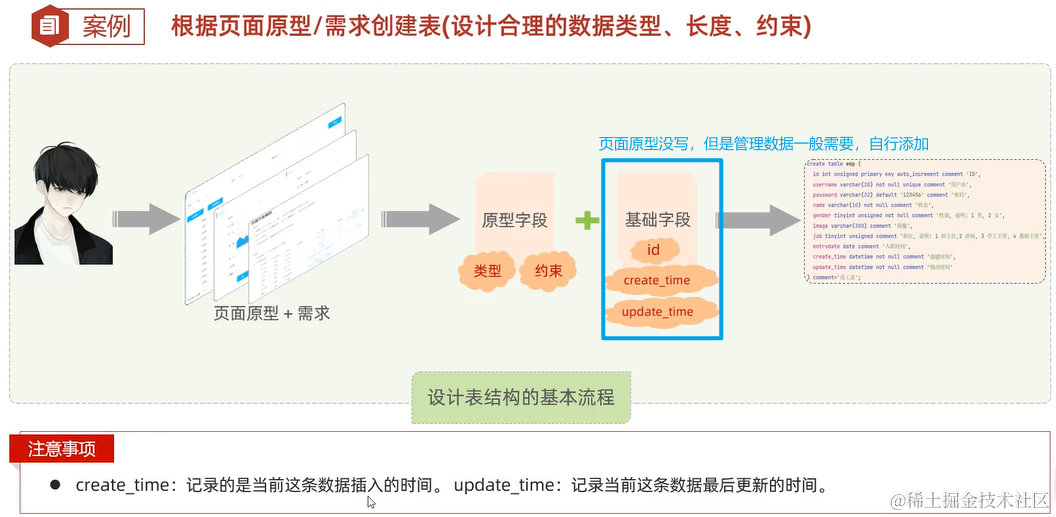
2.3.3 DML(数据操作语言)
DataBase Manipulate Language
对数据库进行增删改功能
1. 增加数据 insert
2. 删除数据 delete
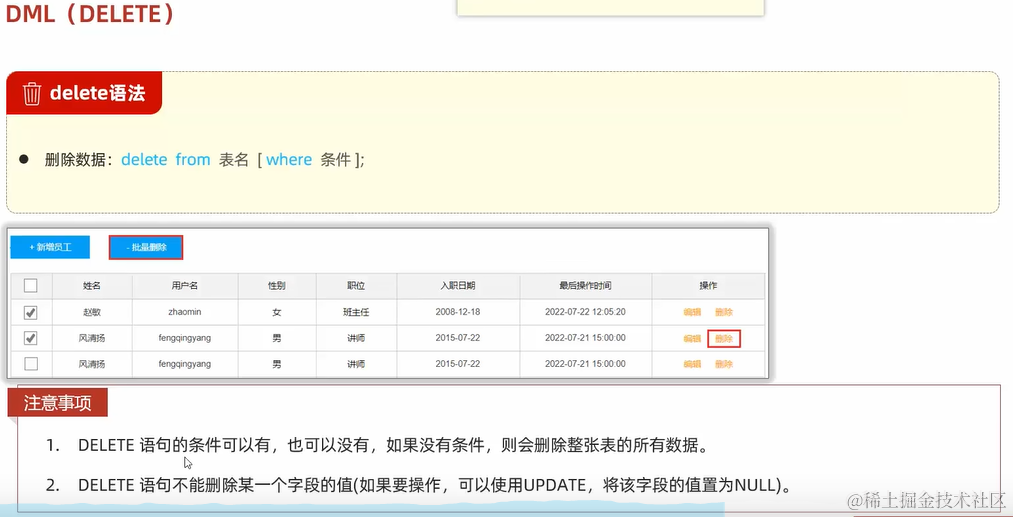
3. 修改数据 update
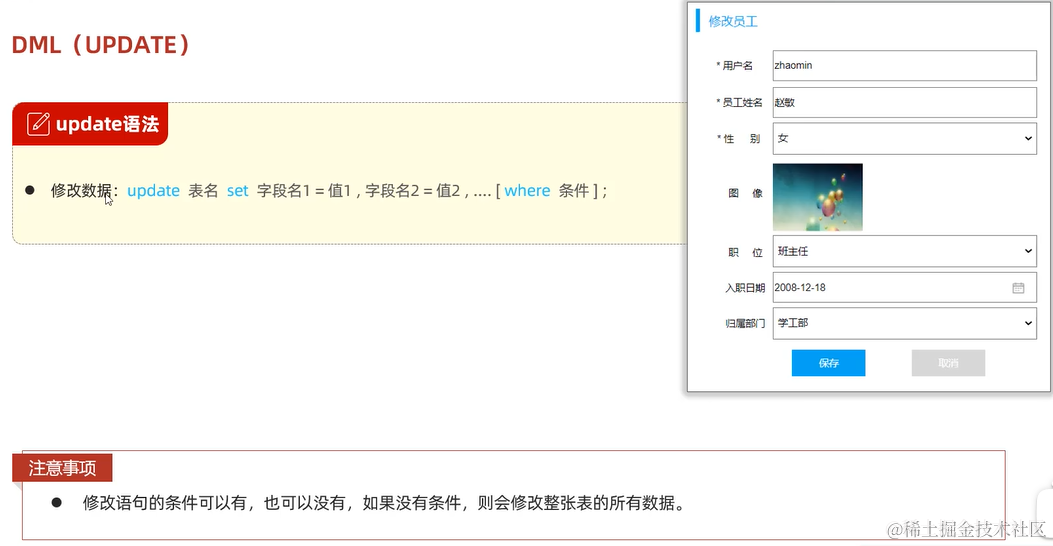
2.3.4 DQL(数据库查询语言)
DataBase Query Language 多表操作 使用频率最高

1. 基本查询 select from

2. 条件查询 where
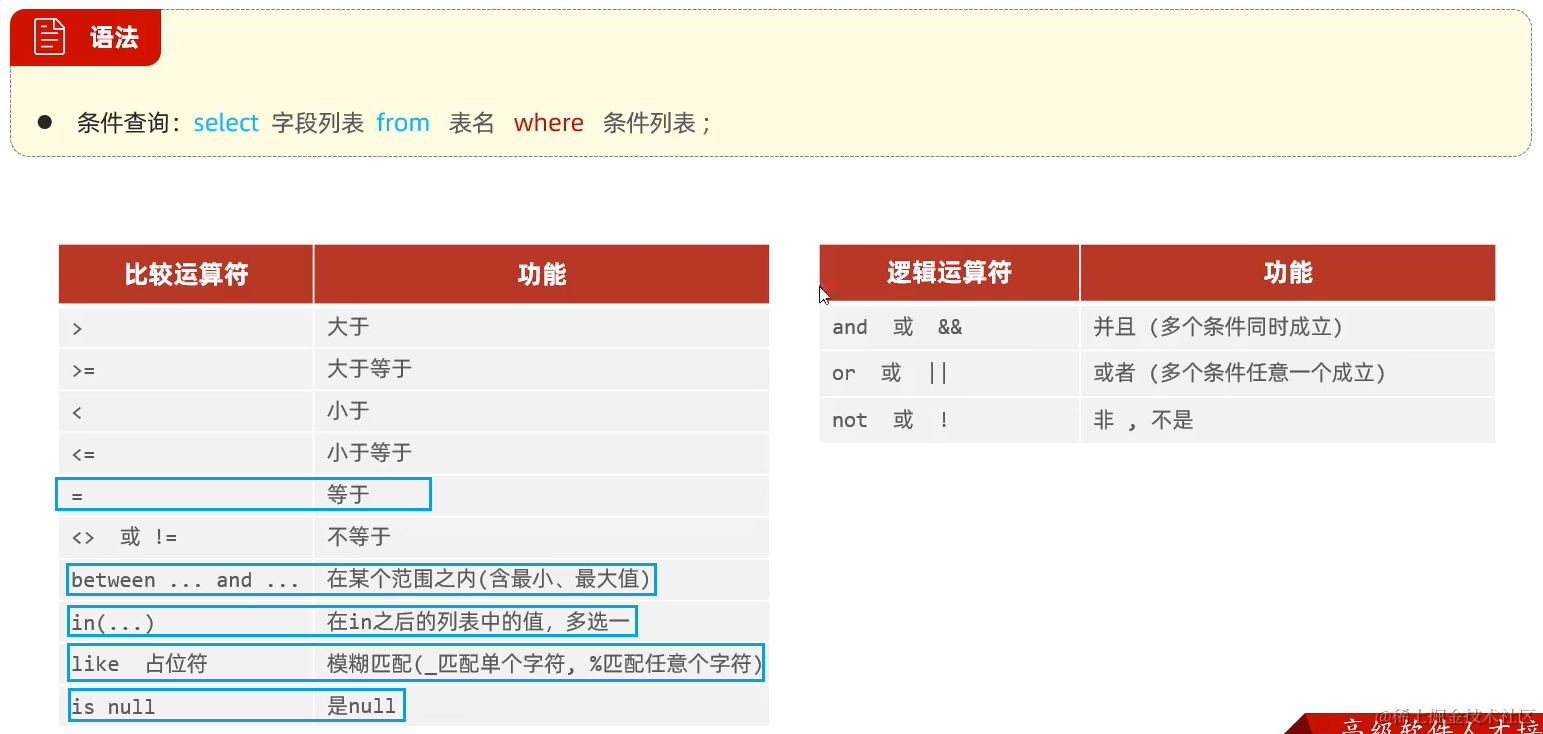
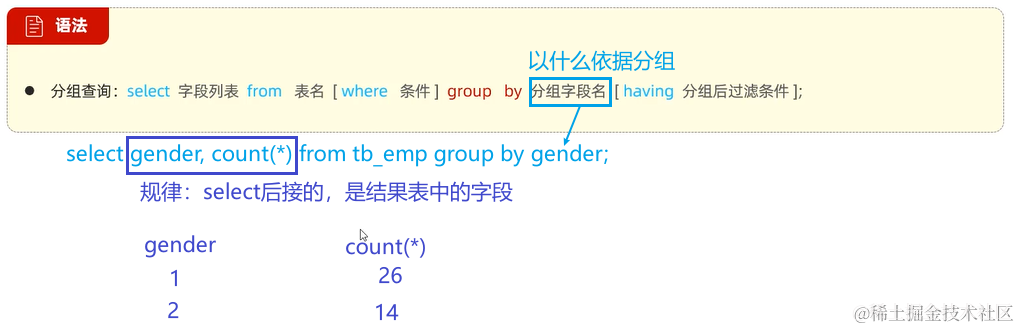
3. 分组查询 group by
聚合函数:不对
null值进行统计

# 统计个数
# count(*)写法——推荐(MySQL底层有针对性优化)
select count(*) from tb_emp;
# count(字段)——会自动忽略null
select count(id) from tb_emp;
分组查询
分组查询返回的表的字段主要有两类:
- 分组字段(分组的依据)
- 聚合函数(如统计总数)
# 先查询入职时间在‘2015-01-01’之前的员工,并对结果根据职位分组,获取员工数量大于等于2的职位
select job, count(*) from tb_emp where entryDate <= '2015-01-01' group by job having count(*) >= 2;
面试题where和having后面都跟的是条件,这两个条件有什么区别?
where是分组之前进行过滤,不符合where条件的不参加过滤having是分组之后再进行的一次过滤where不能对聚合函数进行判断,而having可以
数据 -> where条件 --(符合where条件的数据)–>分组 --> having条件 --> 最终结果
4. 排序查询 order by
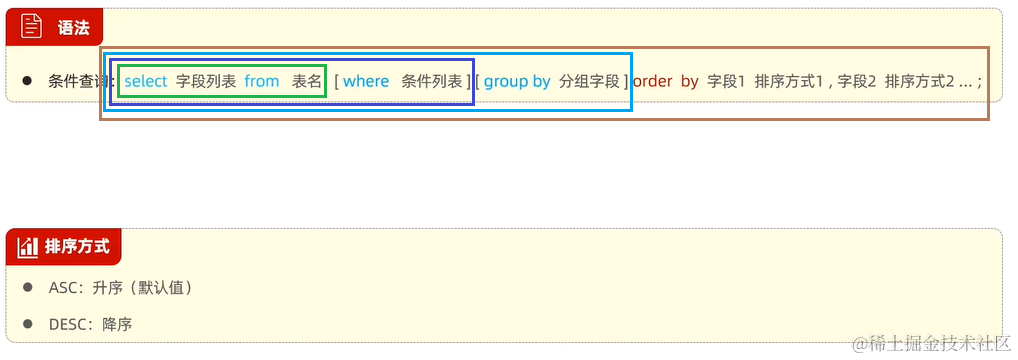
5. 分页查询 limit
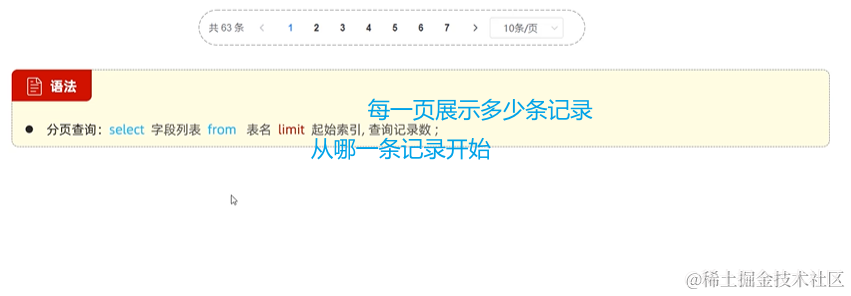
起始索引的公式:(页码 - 1)* 每页展示的记录数
6. 几个流程控制函数
-
if(查询条件, true时取值, false时取值)-
select if(gender = 1,'男','女') as '员工性别', count(*) from tb_emp group by gender;
-
-
case 表达式when 值1 then 结果1when 值2 then 结果2...else 结果nend-
select case job when 1 then '班主任' when 2 then '讲师' when 3 then '学工主管' when 4 then '教研主管' end as '职位' , count(*) as '人数' from tb_emp group by job;
-
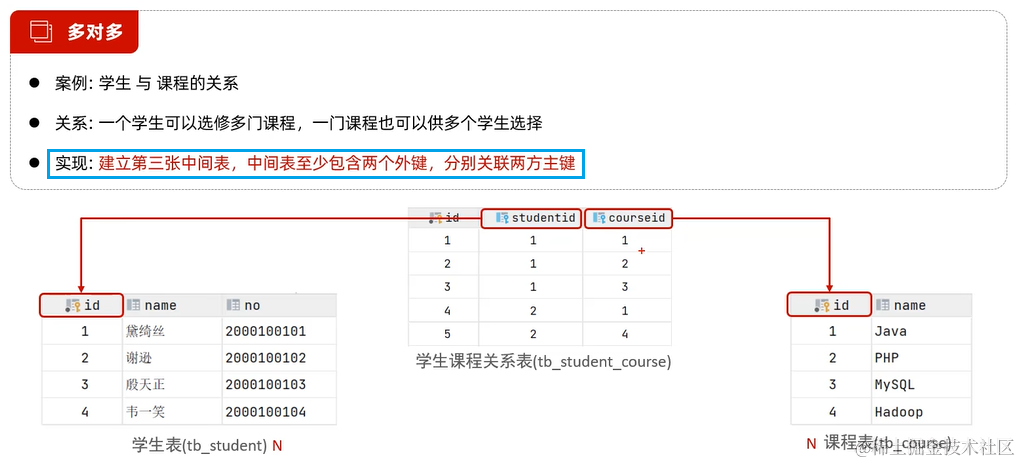
2.3.5 多表设计
1. 一对多(外键)
如有一张部门表和一张员工表
部门表记录了部门id和对应的部门名称
员工表记录了员工的各种信息和所属部门
分析知,部门表为主表
如何在数据库层面将这两张表关联起来?

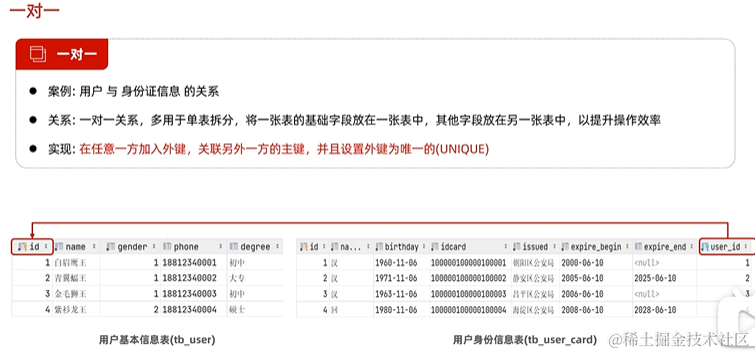
2. 一对一
3. 多对多
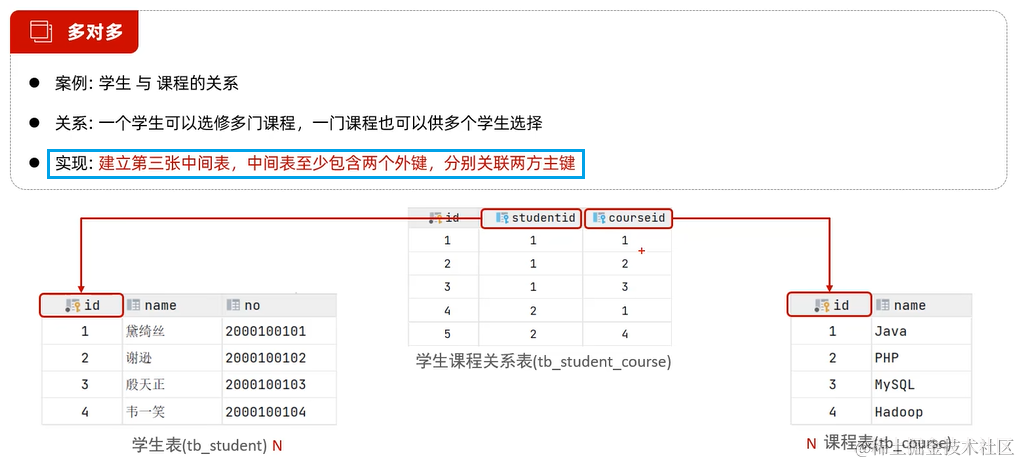
2.3.6 多表查询
直接select * from tb1,tb2会将两张表做笛卡尔积:
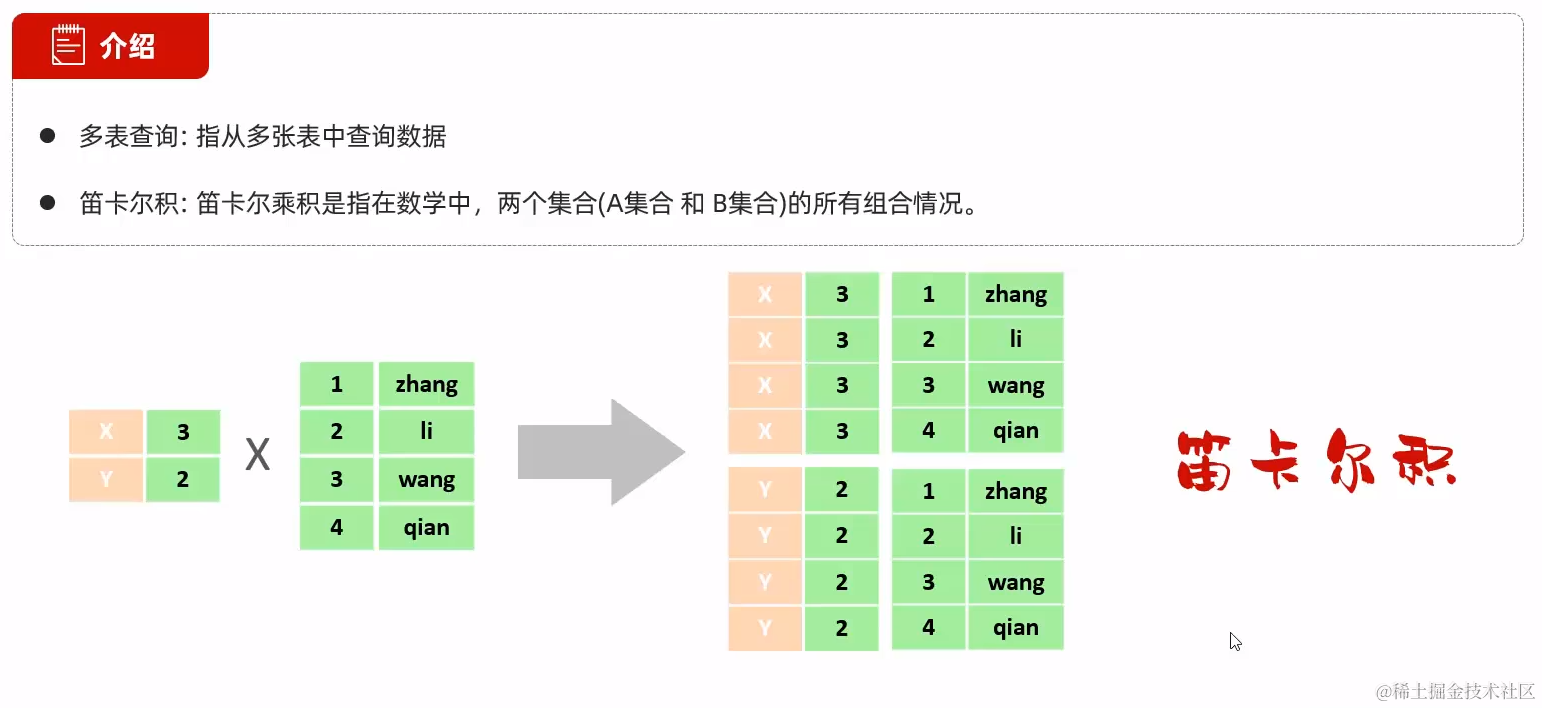
添加where限制条件能消除笛卡尔积
多表查询主要内容:

1. 内连接

隐式内连接: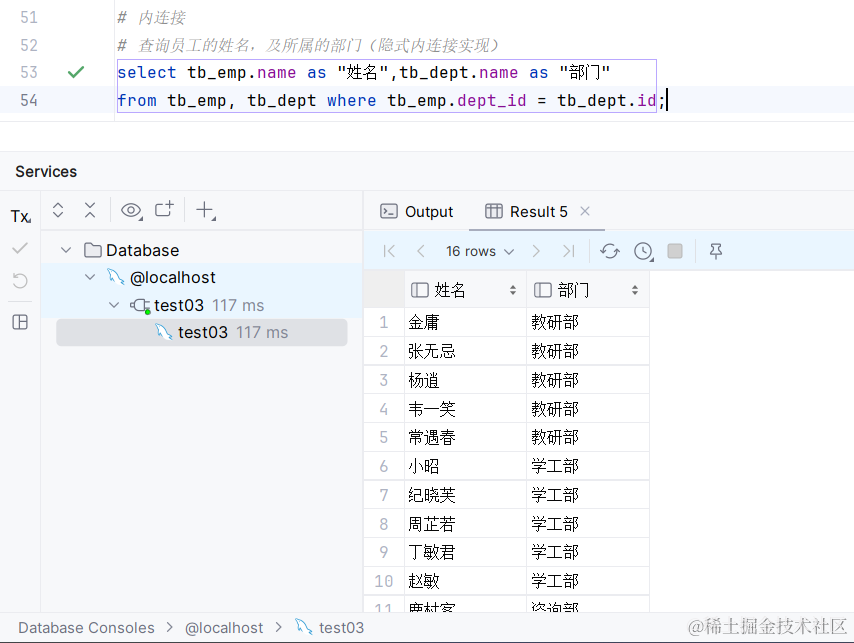
显式内连接:
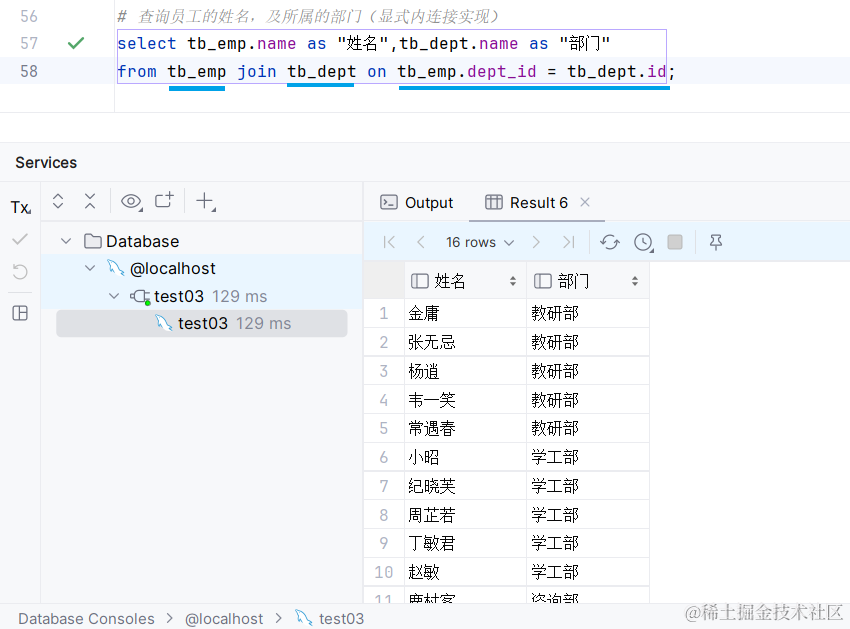
2. 外连接

左外连接:
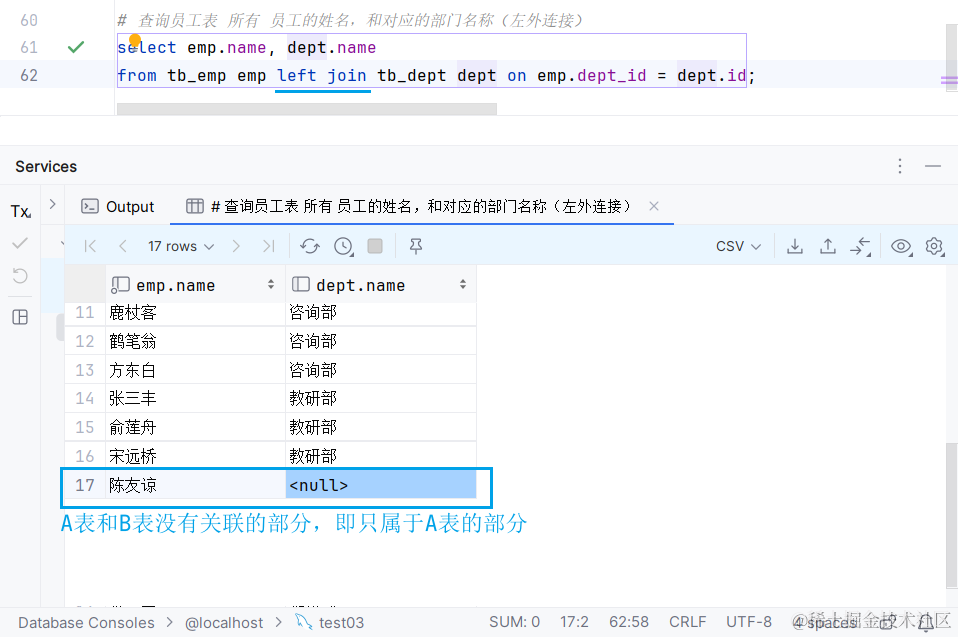
右外连接:
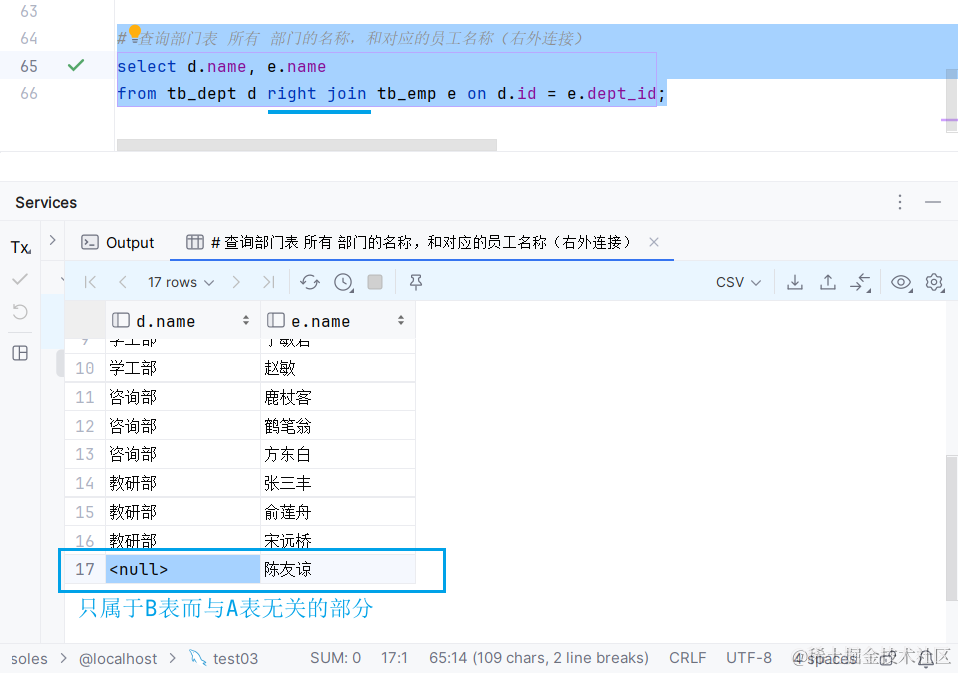
左右外连接可以相互转换,项目中一般使用左外连接
3. 子查询
将查询合理地分解为多步
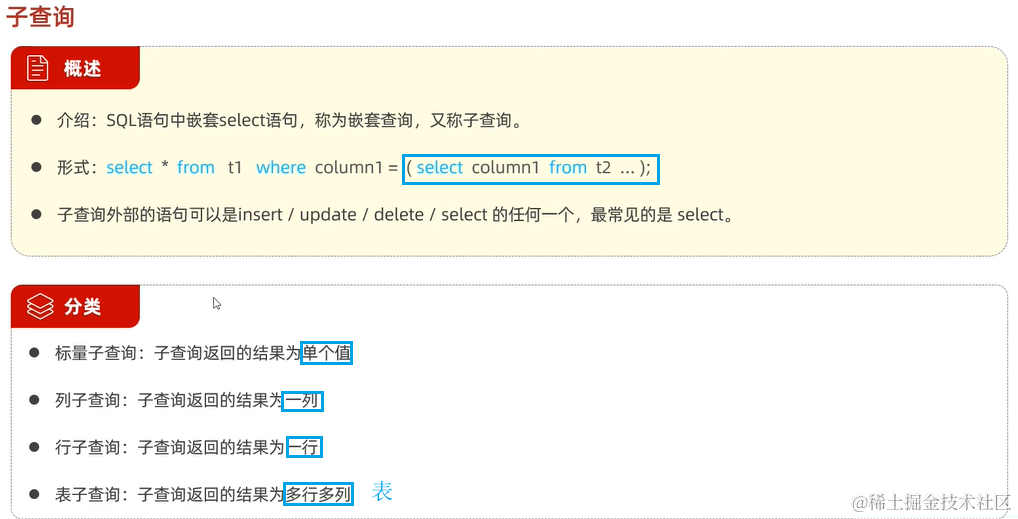
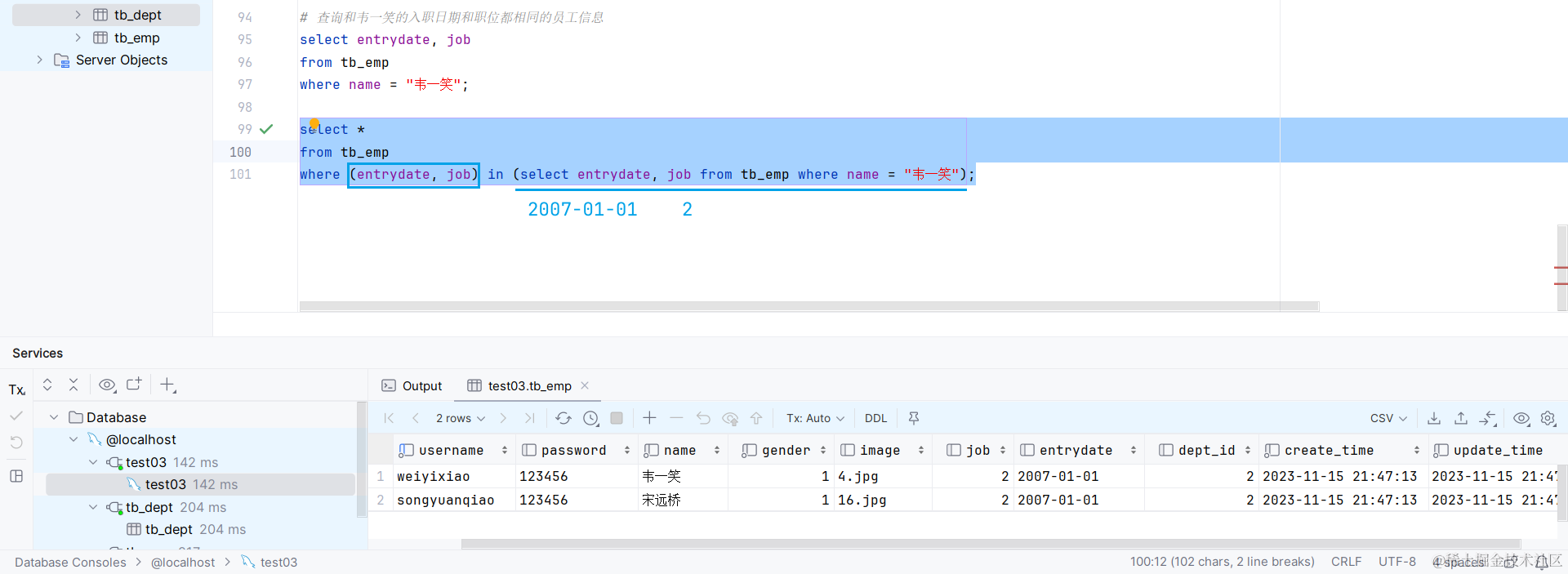
标量子查询: 返回的是单个数据

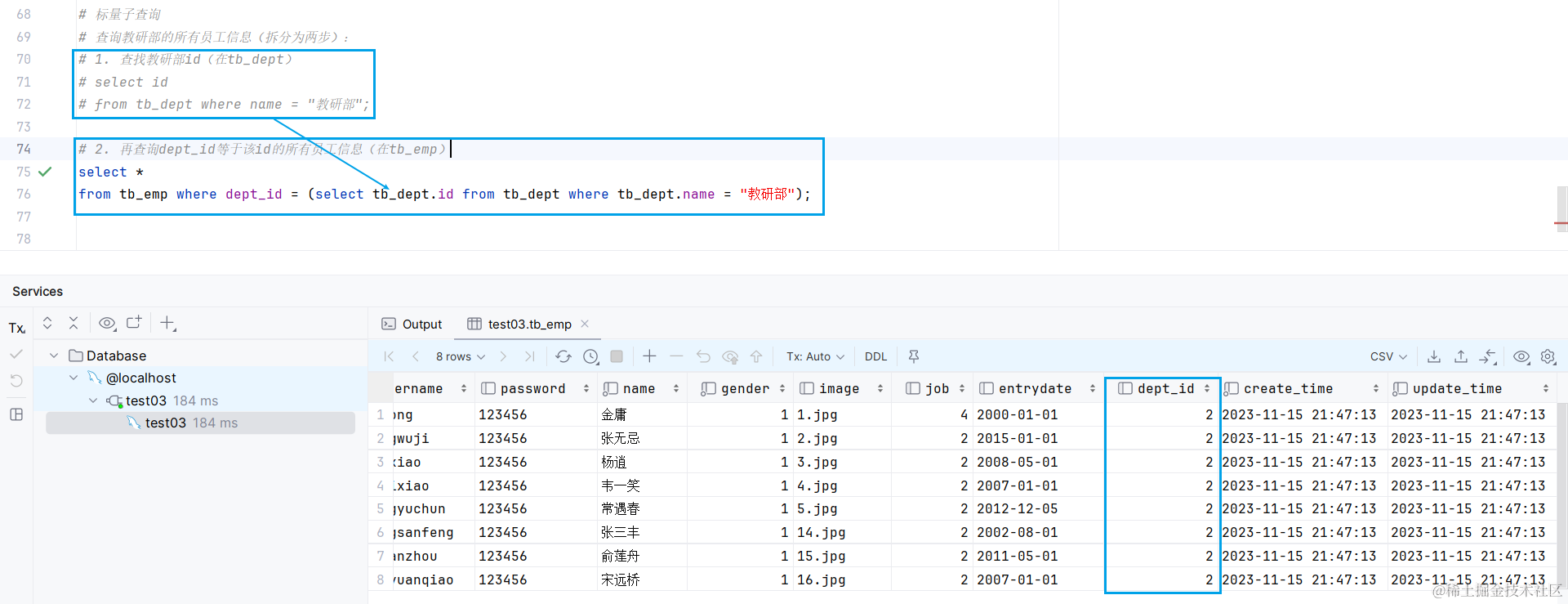
列子查询: 返回的是一列多行的数据

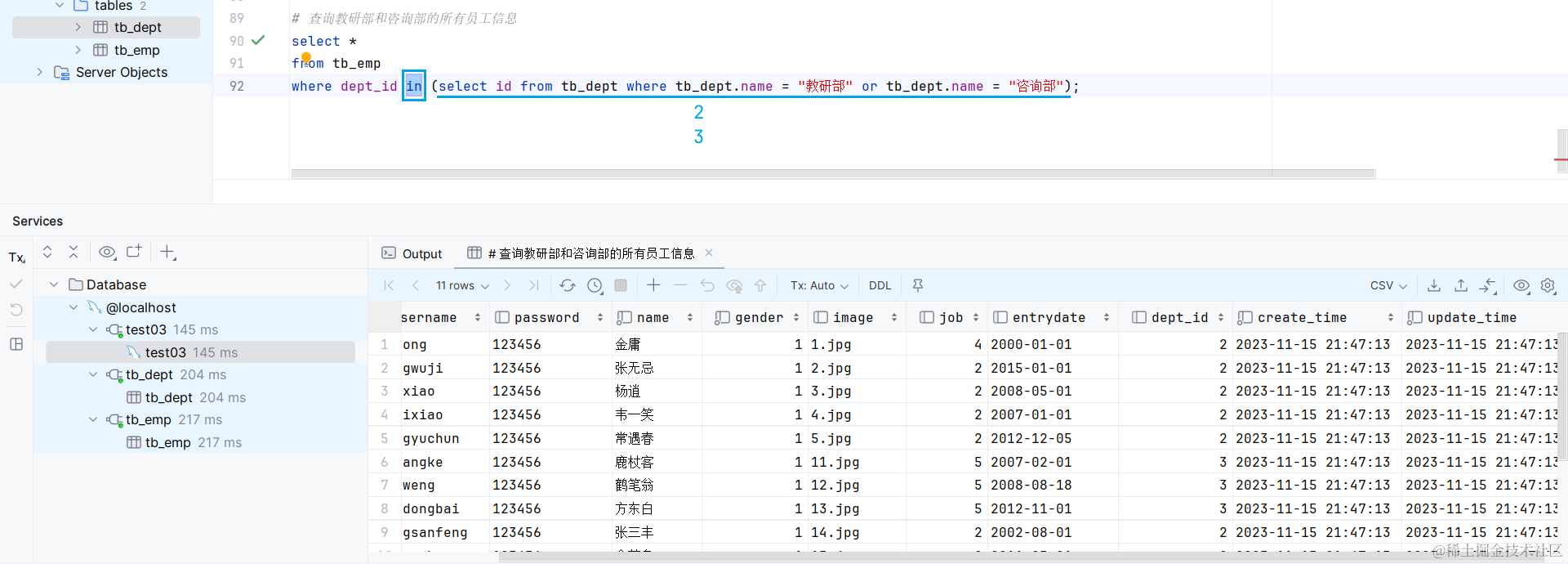
行子查询: 返回的是一行多列的数据

表子查询: 返回的是一个临时的表

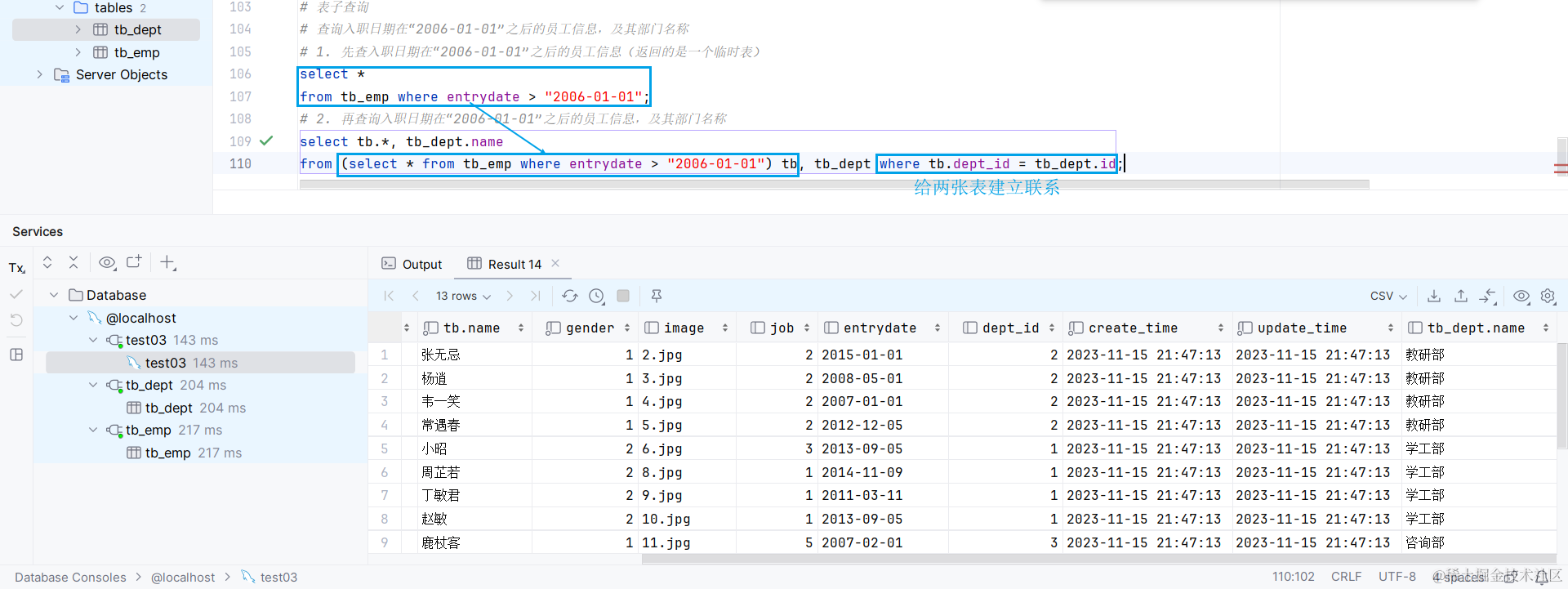
2.3.7 事务
场景: 对多表进行操作时,需要格外关注数据一致性的问题

如何解决数据一致性问题?
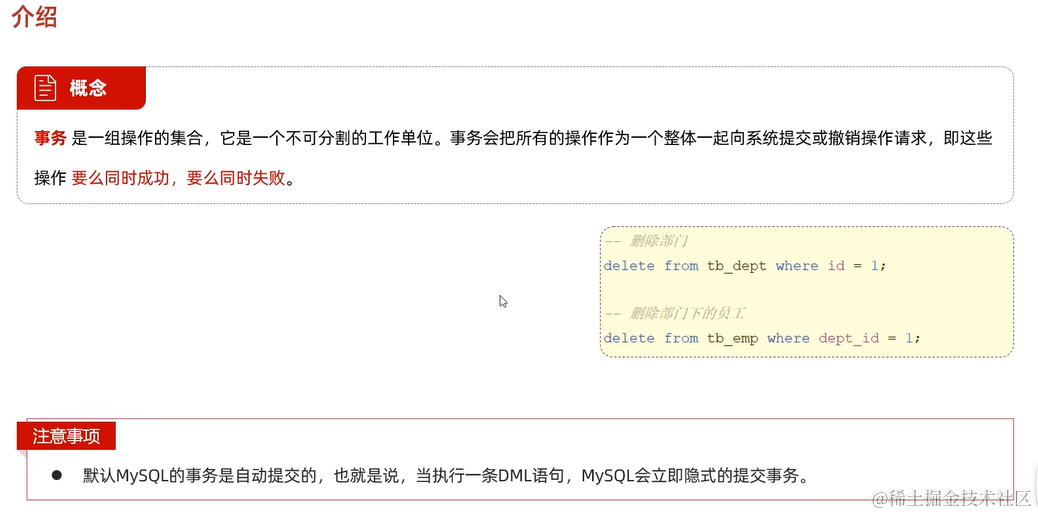

start transaction; # 开启事务
delete from tb_dept where id = 1;
delete from tb_emp where dept_id = 1;
# 若所有的SQL语句执行成功,则:
commit; # 提交事务(需要提交给数据库服务器)
# 若有SQL执行失败,则手动回滚:
rollback; # 回滚数据
事务的四大特性ACID: 面试题

2.3.8 索引
数据库优化策略之一
当数据库表的数据很多时,查询会明显耗费更多时间
对600 0000条数据进行select
不用索引:13s
使用索引:4ms


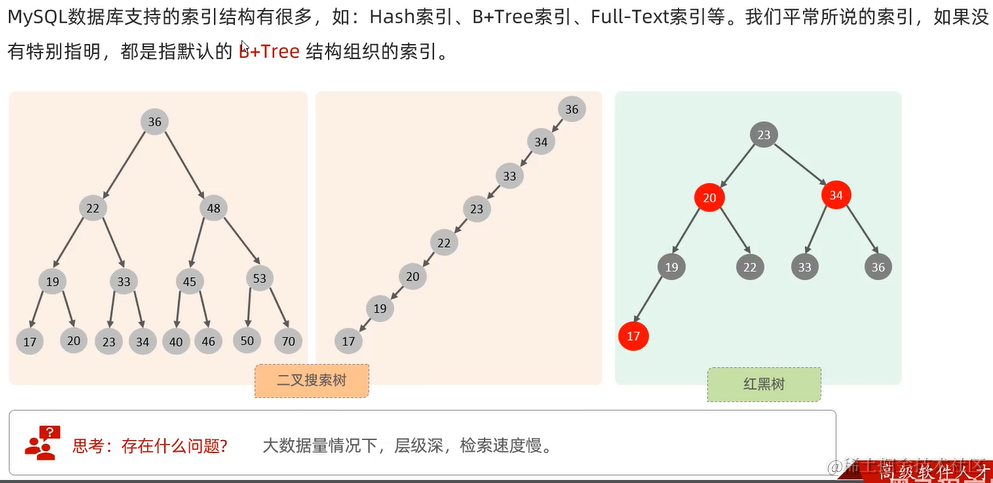
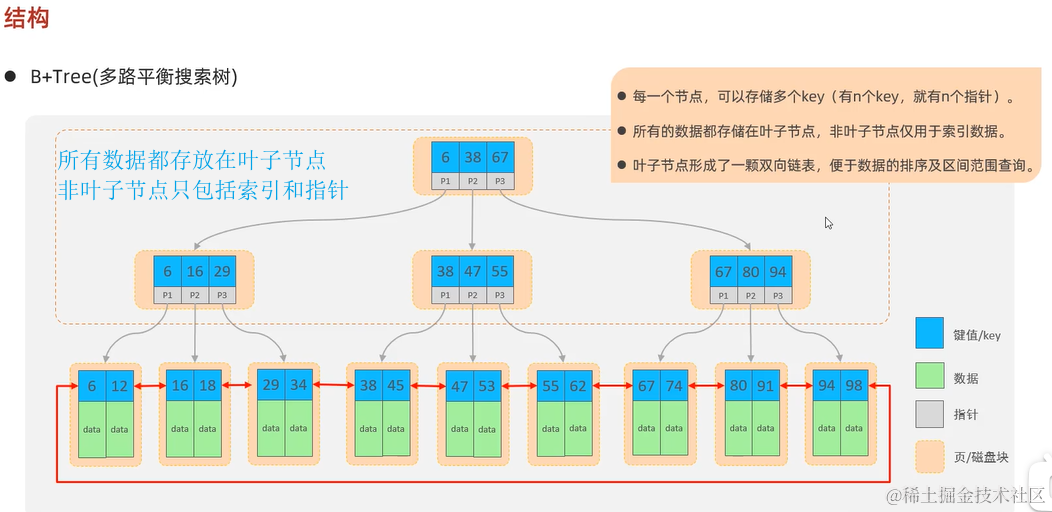
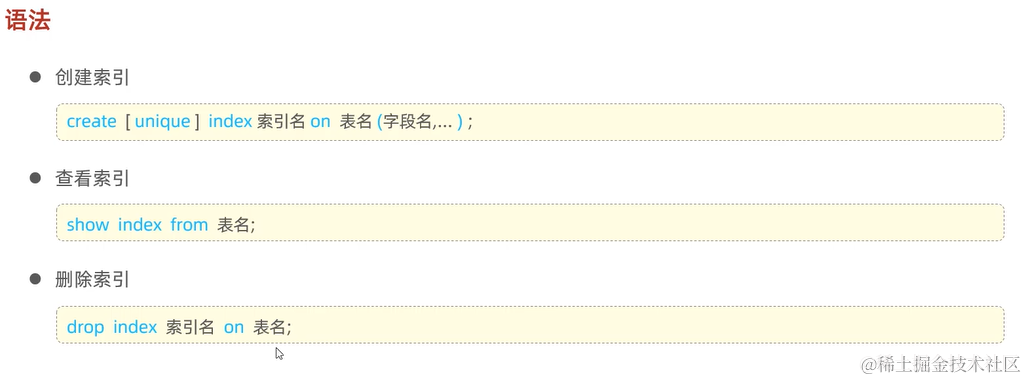
2.4 Mybatis
优秀的持久层/数据访问层/dao/(Mybatis中叫Mapper)框架,用于简化JDBC的开发

2.4.1 入门
1. Mybatis全流程
-
准备工作:
-
创建springboot工程,引入Mybatis相关依赖
-
<!-- https://mvnrepository.com/artifact/org.mybatis.spring.boot/mybatis-spring-boot-starter --> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>2.3.1</version> </dependency> -
<!-- https://mvnrepository.com/artifact/com.mysql/mysql-connector-j --> <dependency> <groupId>com.mysql</groupId> <artifactId>mysql-connector-j</artifactId> <version>8.0.33</version> <scope>runtime</scope> </dependency>
-
-
创建数据库表user
-
创建实体类User(实体类的属性和数据库表一一对应,建议类型都用封装类型,如int->Integer)
-
/** * 与test04数据库中的user表对应 */ public class User { private Integer id; private String name; private Short age; private Short gender; private String phone; // constructors public User() {} // 无参构造 public User(Integer id, String name, Short age, Short gender, String phone) {...} // 有参构造 // setters and getters ... // toString @Override public String toString() {...} }
-
-
-
配置数据库连接(4点,在springboot的application.properties)
- 配置数据库驱动类:
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver - 配置数据库服务器url地址:
spring.datasource.url=jdbc:mysql://localhost:3306/mybatis(/后为服务器地址,若本机作为数据库服务器,则用localhost:3306;mybatis为数据库的名称) - 配置数据库用户名:
spring.datasource.username=root - 配置密码:
spring.datasource.password=123456
- 配置数据库驱动类:
-
编写SQL语句(注解/XML)
编写SQL语句可采用
注解@或XML映射文件的形式-
在Mybatis中,创建一个package名为mapper(相当于dao数据访问层,只不过mapper层专门访问数据库)
-
在Mapper中创建一个访问user表的接口UserMapper
/** * 与数据库中的user表交互 */ @Mapper // 将该接口交给Mybatis管理,运行时会自动生成相应对象,并交给IOC容器管理,使用时直接@Autowired来创建对象 public interface UserMapper { @Select("select * from user") public List<User> list(); } -
访问数据库user表时:
@Autowired private UserMapper userMapper; // 先Autowired一个UserMapper对象 // 然后再获取到数据库操作结果: public void testUserMapperlist(){ List<User> userlist = userMapper.list(); userlist.forEach(user -> { System.out.println(user); }); }
-
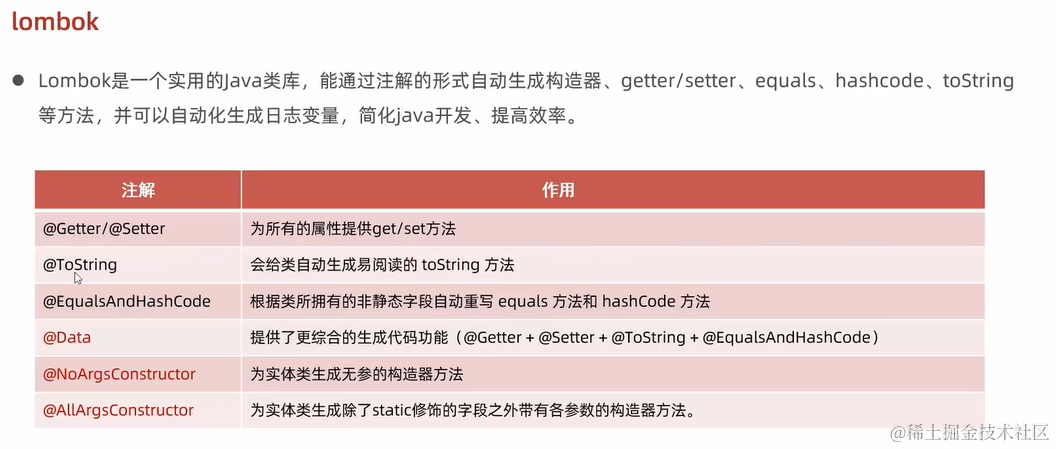
2. lombok
简化实体类的编写,无需再手写setter, getter, toString, constructors,只需使用几个注解
2.4.2 基础操作
可配置Mybatis的日志信息,并指定在控制台输出
# application.properties # 配置Mybatis日志,并指定输出到控制台中 mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
1. select
@Mapper // 将该接口交给Mybatis管理,运行时会自动生成相应对象,并交给IOC容器管理,使用时直接@Autowired来创建对象
public interface EmpMapper {
/**
* 选择所有的员工信息
* @return
*/
@Select("select * from emp")
public List<Emp> list();
}
2. delete
@Mapper // 将该接口交给Mybatis管理,运行时会自动生成相应对象,并交给IOC容器管理,使用时直接@Autowired来创建对象
public interface EmpMapper {
/**
* 根据id删除某员工
*/
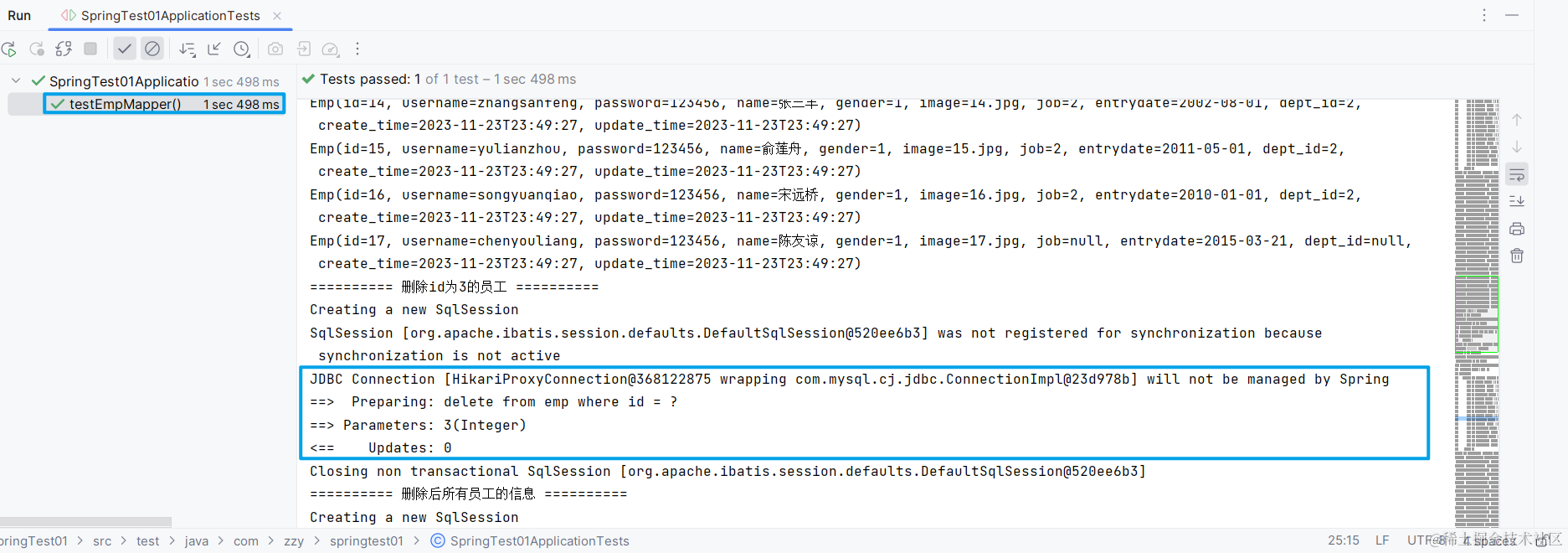
@Delete("delete from emp where id = #{id}")
public void deleteEmp(Integer id); // @Delete其实有返回值,会返回操作(删除)了多少条数据,但一般就用void
}
#{}为SQL的占位符,使用${}也可以,但是存在SQL注入的问题。所以一般若需给SQL语句传参,都使用#{},它会在编译时生成预编译的SQL,更高效也更安全面试题区别:
delete from emp where id = #{id} id=3
- 编译后会生成预编译语句:
delete from emp where id = ? parameters = 3
delete from emp where id = ${id} id=3
- 编译后会生成:
delete from emp where id=3
3. insert
@Mapper // 将该接口交给Mybatis管理,运行时会自动生成相应对象,并交给IOC容器管理,使用时直接@Autowired来创建对象
public interface EmpMapper {
/**
* 插入一条员工信息
* @param emp
*/
@Insert("insert into emp(username, name, gender, image, job, entrydate, dept_id, create_time, update_time) value (#{username},#{name},#{gender},#{image},#{job},#{entrydate},#{dept_id},#{create_time},#{update_time})")
public void insertEmp(Emp emp); // #{}内的内容是Emp对象的属性名
}
主键返回
有些应用场景需要我们获取到刚刚插入的数据的主键值。比如维护中间关系表时。

4. update
常见的应用场景为弹出一个表单,用于修改当前已有的数据。
@Mapper // 将该接口交给Mybatis管理,运行时会自动生成相应对象,并交给IOC容器管理,使用时直接@Autowired来创建对象
public interface EmpMapper {
/**
* 传入更新后的Emp对象,对数据库中相应id的元组进行更新
* @param emp
*/
@Update("update emp set username=#{username}, name=#{name},gender=#{gender},image=#{image},job=#{job},entrydate=#{entrydate},dept_id=#{dept_id},update_time=#{update_time} where id=#{id}")
public void updateEmp(Emp emp);
}
5. 查询
@Mapper // 将该接口交给Mybatis管理,运行时会自动生成相应对象,并交给IOC容器管理,使用时直接@Autowired来创建对象
public interface EmpMapper {
/**
* 根据id查询员工信息
* @param id
*/
@Select("select * from emp where id=#{id}")
public Emp queryEmpById(Integer id);
}
查询时,有时会出现查询到的字段值为
null的情况原因:当字段名和属性名一致时,Mybatis会自动封装;当不一致时,Mybatis无法自动封装
解决办法:
方案一:在SQL语句中,给字段名和属性名不一致的字段起别名
@Select("select dept_id deptId, update_time updateTime from emp where id=#{id}") // 其中dept_id, update_time为数据库中的字段名,deptId, updateTime为封装的Emp类中的属性名方案二:通过
@Results,@Result注解进行手动映射(麻烦不推荐)@Results({ @Result(column="dept_id", property="deptId"), @Result(column="update_time", property="updateTime") }) @Select("select * from emp where id=#{id}")方案三:开启Mybatis的下划线命名法<->驼峰命名法自动映射开关
// application.properties mybatis.configuration.map-underscore-to-camel-case=true
2.4.3 使用XML映射文件编写SQL语句
使用Mybatis在Java中编写SQL语句,既可以采用注解@的形式,也可采用XM了映射文件的形式
XML映射文件更适用于较复杂的SQL语句的编写
-
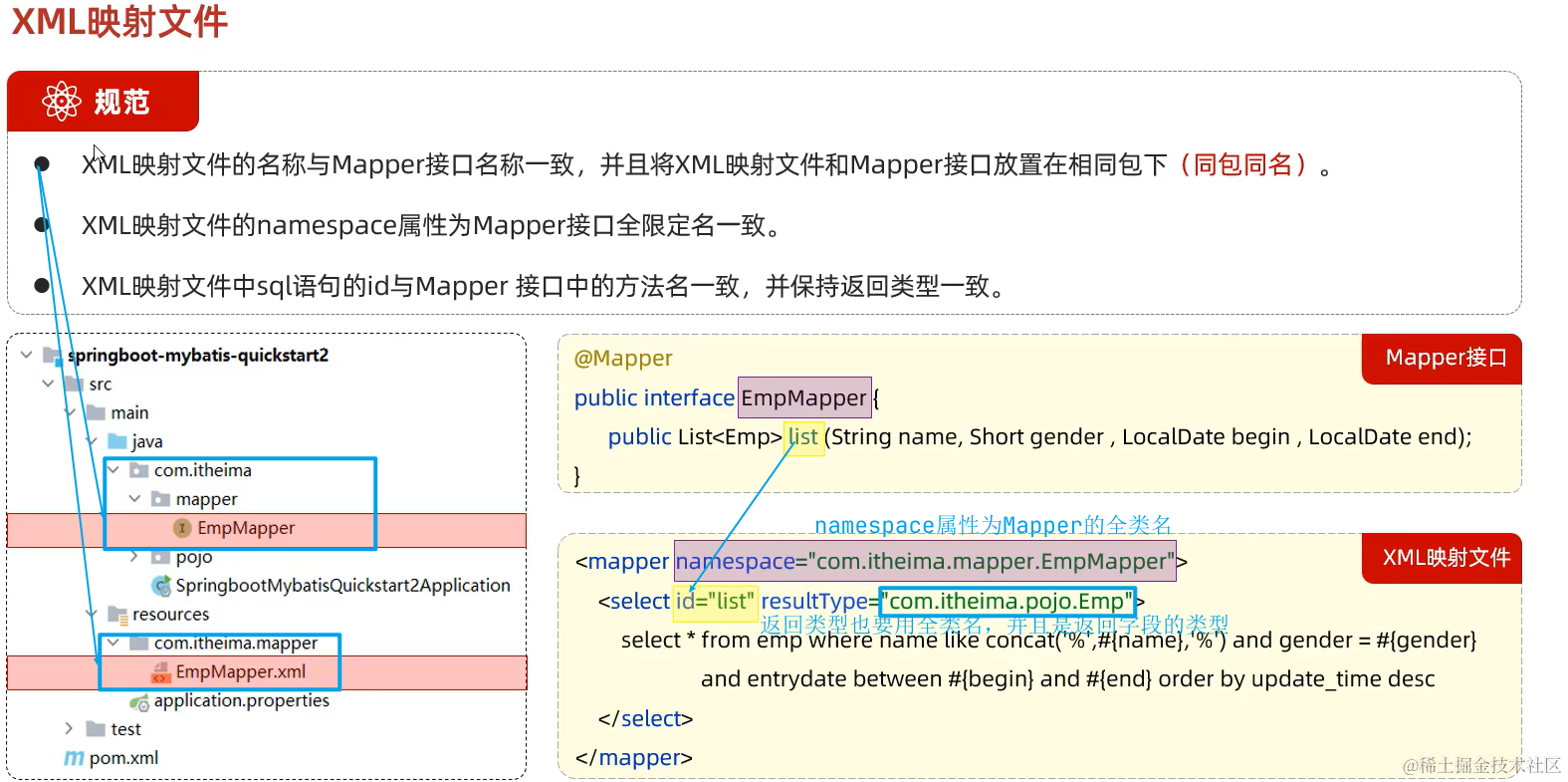
定义XML映射文件
-
建好EmpMapper.xml
-
建好xml映射文件的结构:
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.zzy.springtest01.mapper.EmpMapper" > ... </mapper> -
编写SQL语句
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.zzy.springtest01.mapper.EmpMapper"> <insert id="insertEmp"> insert into emp(username, name, gender, image, job, entrydate, dept_id, create_time, update_time) value (#{username},#{name},#{gender},#{image},#{job},#{entrydate},#{dept_id},#{create_time},#{update_time}) </insert> <update id="updateEmp"> update emp set username=#{username}, name=#{name},gender=#{gender},image=#{image},job=#{job},entrydate=#{entrydate},dept_id=#{dept_id},update_time=#{update_time} where id=#{id} </update> <select id="list" resultType="com.zzy.springtest01.pojo.Emp"> select * from emp; </select> <delete id="deleteEmp"> delete from emp where id = #{id} </delete> </mapper>
-
2.4.4 动态SQL
随着用户的输入或外部条件的变化而变化的SQL语句称为动态SQL
1. if标签

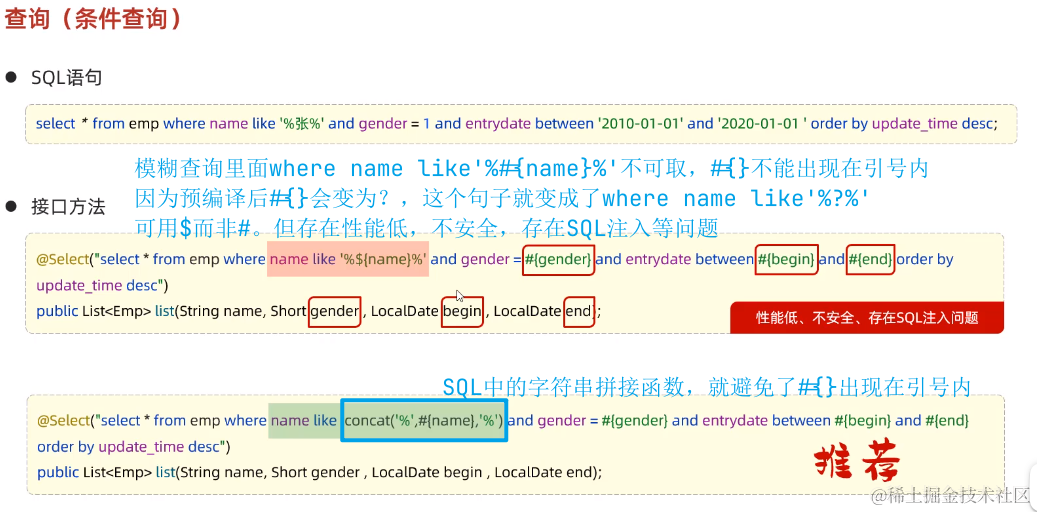
原:
<select id="listSomeEmp" resultType="com.zzy.springtest01.pojo.Emp">
select *
from emp
where
name like concat('%', #{name}, '%')
and gender = #{gender}
and entrydate between #{begin} and #{end}
order by update_time desc;
</select>
现:
<select id="listSomeEmp" resultType="com.zzy.springtest01.pojo.Emp">
select *
from emp
<where> // <where>标签能自动判断<if>标签中的条件并相应地生成SQL语句,并且删掉多余的"and"
<if test="name!=null"> // test属性中填条件
name like concat('%', #{name}, '%')
</if>
<if test="gender!=null">
and gender = #{gender}
</if>
<if test="begin!=null and end!=null">
and entrydate between #{begin} and #{end}
</if>
</where>
order by update_time desc;
</select>
2. where标签
标签用于:
- 要是
select * from emp where...的where条件全为null,则不生成where关键字---->select * from emp - 自动删除多余的and关键字和多余的
,等符号
3. set标签
标签用于update语句:
-
自动删除多余的
,等符号 -
原: <update id="updateEmp"> update emp set <if test="username!=null"> username=#{username}, </if> <if test="name!=null"> name=#{name}, </if> <if test="gender!=null"> gender=#{gender}, </if> <if test="image!=null"> image=#{image}, </if> <if test="job!=null"> job=#{job}, </if> <if test="entrydate!=null"> entrydate=#{entrydate}, </if> <if test="dept_id!=null"> dept_id=#{dept_id}, </if> <if test="update_time!=null"> update_time=#{update_time} </if> where id = #{id} </update>现: <update id="updateEmp"> update emp <set> <if test="username!=null"> username=#{username}, </if> <if test="name!=null"> name=#{name}, </if> <if test="gender!=null"> gender=#{gender}, </if> <if test="image!=null"> image=#{image}, </if> <if test="job!=null"> job=#{job}, </if> <if test="entrydate!=null"> entrydate=#{entrydate}, </if> <if test="dept_id!=null"> dept_id=#{dept_id}, </if> <if test="update_time!=null"> update_time=#{update_time} </if> </set> where id = #{id} </update>
4. foreach标签
<!-- delete from emp where id in (15,16,17) -->
<delete id="deleteInBulk">
delete
from emp
where id in
<foreach collection="ids" item="id" separator="," open="(" close=")">
#{id}
</foreach>
</delete>
属性:
- collection=“Mapper传入的要遍历的集合的名称”
- item=“遍历出来的每一项,自行命名”
- separator=“遍历出来的每一项要拼接在一起,用什么分隔符来拼接”
- open=“遍历出来第一项的前面需要加什么符号”
- close=“遍历出来最后一项的后面需要加什么符号”
5. SQL抽取与include
在真实的应用场景中,不推荐使用select *,查询效率低下,而是建议将要查询的所有字段都显式地写出来
这样在xml映射文件中就会出现大量重复的例如:select id, username, name, gender, entrydate, job,... from emp等语句
能否将这些重复的部分给封装起来,以便复用?
SQL抽取:
<sql id="CommonSelect">
select id, username, name, gender, entrydate, job,... from emp
</sql>
include:
<include refid="CommonSelect" />
例子:
<mapper ... >
<sql id="CommonSelect">
select id, username, name, gender, entrydate, job,... from emp
</sql>
<select id="..." resultType="...">
<include refid="CommonSelect"/>
<where>
<if test="name!=null">
name like concat('%', #{name}, '%')
</if>
<if test="gender!=null">
and gender = #{gender}
</if>
<if test="begin!=null and end!=null">
and entrydate between #{begin} and #{end}
</if>
</where>
order by update_time desc;
</select>
</mapper>
智能推荐
没有U盘Win10电脑下如何使用本地硬盘安装Ubuntu20.04(单双硬盘都行)_没有u盘怎么装ubuntu-程序员宅基地
文章浏览阅读3.6k次,点赞2次,收藏2次。DELL7080台式机两块硬盘。_没有u盘怎么装ubuntu
【POJ 3401】Asteroids-程序员宅基地
文章浏览阅读32次。题面Bessie wants to navigate her spaceship through a dangerous asteroid field in the shape of an N x N grid (1 <= N <= 500). The grid contains K asteroids (1 <= K <= 10,000), which are conv...
工业机器视觉系统的构成与开发过程(理论篇—1)_工业机器视觉系统的构成与开发过程(理论篇—1-程序员宅基地
文章浏览阅读2.6w次,点赞21次,收藏112次。机器视觉则主要是指工业领域视觉的应用研究,例如自主机器人的视觉,用于检测和测量的视觉系统等。它通过在工业领域将图像感知、图像处理、控制理论与软件、硬件紧密结合,并研究解决图像处理和计算机视觉理论在实际应用过程中的问题,以实现高效的运动控制或各种实时操作。_工业机器视觉系统的构成与开发过程(理论篇—1
plt.legend的用法-程序员宅基地
文章浏览阅读5.9w次,点赞32次,收藏58次。legend 传奇、图例。plt.legend()的作用:在plt.plot() 定义后plt.legend() 会显示该 label 的内容,否则会报error: No handles with labels found to put in legend.plt.plot(result_price, color = 'red', label = 'Training Loss') legend作用位置:下图红圈处。..._plt.legend
深入理解 C# .NET Core 中 async await 异步编程思想_netcore async await-程序员宅基地
文章浏览阅读2.2k次,点赞3次,收藏11次。深入理解 C# .NET Core 中 async await 异步编程思想引言一、什么是异步?1.1 简单实例(WatchTV并行CookCoffee)二、深入理解(异步)2.1 当我需要异步返回值时,怎么处理?2.2 充分利用异步并行的高效性async await的秘密引言很久没来CSDN了,快小半年了一直在闲置,也写不出一些带有思想和深度的文章;之前就写过一篇关于async await 的异步理解 ,现在回顾,真的不要太浅和太陋,让人不忍直视!好了,废话不再啰嗦,直入主题:一、什么是异步?_netcore async await
IntelliJ IDEA设置类注释和方法注释带作者和日期_idea作者和日期等注释-程序员宅基地
文章浏览阅读6.5w次,点赞166次,收藏309次。当我看到别人的类上面的多行注释是是这样的:这样的:这样的:好装X啊!我也想要!怎么办呢?往下瞅:跟着我左手右手一个慢动作~~~File--->Settings---->Editor---->File and Code Templates --->Includes--->File Header:之后点applay--..._idea作者和日期等注释
随便推点
发行版Linux和麒麟操作系统下netperf 网络性能测试-程序员宅基地
文章浏览阅读175次。Netperf是一种网络性能的测量工具,主要针对基于TCP或UDP的传输。Netperf根据应用的不同,可以进行不同模式的网络性能测试,即批量数据传输(bulk data transfer)模式和请求/应答(request/reponse)模式。工作原理Netperf工具以client/server方式工作。server端是netserver,用来侦听来自client端的连接,c..._netperf 麒麟
万字长文详解 Go 程序是怎样跑起来的?| CSDN 博文精选-程序员宅基地
文章浏览阅读1.1k次,点赞2次,收藏3次。作者| qcrao责编 | 屠敏出品 | 程序员宅基地刚开始写这篇文章的时候,目标非常大,想要探索 Go 程序的一生:编码、编译、汇编、链接、运行、退出。它的每一步具体如何进行,力图弄清 Go 程序的这一生。在这个过程中,我又复习了一遍《程序员的自我修养》。这是一本讲编译、链接的书,非常详细,值得一看!数年前,我第一次看到这本书的书名,就非常喜欢。因为它模仿了周星驰喜剧..._go run 每次都要编译吗
C++之istringstream、ostringstream、stringstream 类详解_c++ istringstream a >> string-程序员宅基地
文章浏览阅读1.4k次,点赞4次,收藏2次。0、C++的输入输出分为三种:(1)基于控制台的I/O (2)基于文件的I/O (3)基于字符串的I/O 1、头文件[cpp] view plaincopyprint?#include 2、作用istringstream类用于执行C++风格的字符串流的输入操作。 ostringstream类用_c++ istringstream a >> string
MySQL 的 binglog、redolog、undolog-程序员宅基地
文章浏览阅读2k次,点赞3次,收藏14次。我们在每个修改的地方都记录一条对应的 redo 日志显然是不现实的,因此实现方式是用时间换空间,我们在数据库崩了之后用日志还原数据时,在执行这条日志之前,数据库应该是一个一致性状态,我们用对应的参数,执行固定的步骤,修改对应的数据。1,MySQL 就是通过 undolog 回滚日志来保证事务原子性的,在异常发生时,对已经执行的操作进行回滚,回滚日志会先于数据持久化到磁盘上(因为它记录的数据比较少,所以持久化的速度快),当用户再次启动数据库的时候,数据库能够通过查询回滚日志来回滚将之前未完成的事务。_binglog
我的第一个Chrome小插件-基于vue开发的flexbox布局CSS拷贝工具_chrome css布局插件-程序员宅基地
文章浏览阅读3k次。概述之前介绍过 移动Web开发基础-flex弹性布局(兼容写法) 里面有提到过想做一个Chrome插件,来生成flexbox布局的css代码直接拷贝出来用。最近把这个想法实现了,给大家分享下。play-flexbox插件介绍play-flexbox一秒搞定flexbox布局,可直接预览效果,拷贝CSS代码快速用于页面重构。 你也可以通过点击以下链接(codepen示例)查_chrome css布局插件
win10下安装TensorFlow-gpu的流程(包括cuda、cuDnn下载以及安装问题)-程序员宅基地
文章浏览阅读308次。我自己的配置是GeForce GTX 1660 +CUDA10.0+CUDNN7.6.0 + TensorFlow-GPU 1.14.0Win10系统安装tensorflow-gpu(按照步骤一次成功)https://blog.csdn.net/zqxdsy/article/details/103152190环境配置——win10下TensorFlow-GPU安装(GTX1660 SUPER+CUDA10+CUDNN7.4)https://blog.csdn.net/jiDxiaohuo/arti