有Mysql数据库的情况下为什么要用Hive数据库?-程序员宅基地
有Mysql数据库的情况下为什么要用Hive?
最近接到公司的一个需求,要求使用Hive做数据查询。当时第一反应就是What?Hive是什么鬼?一脸懵逼状。(请原谅一个刚开始实习的Java实习生见识短浅)然后发现了hive的一些问题。下面简单介绍一下Hive。
网上对于hive与mysql的区别的文章也不是很多。so只能问问公司大牛们,看看他们是怎样理解的。
由于 Hive 采用了 SQL 的查询语言 HQL,因此很容易将 Hive 理解为数据库。其实 从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。
数据库可以用在 Online 的应用中,但是 Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性。
一、Hive是一个基于Hadoop的数据仓库平台。通过hive,我们可以方便地进行ETL的工作。hive定义了一个类似于SQL的查询语言:HQL,能 够将用户编写的QL转化为相应的Mapreduce程序基于Hadoop执行。
Hive是Facebook 2008年8月刚开源的一个数据仓库框架,其系统目标与 Pig 有相似之处,但它有一些Pig目前还不支持的机制,比如:更丰富的类型系统、更类似SQL的查询语言、Table/Partition元数据的持久化等。
Hive 可以看成是从SQL到Map-Reduce的 映射器
Hive的数据放在哪儿?
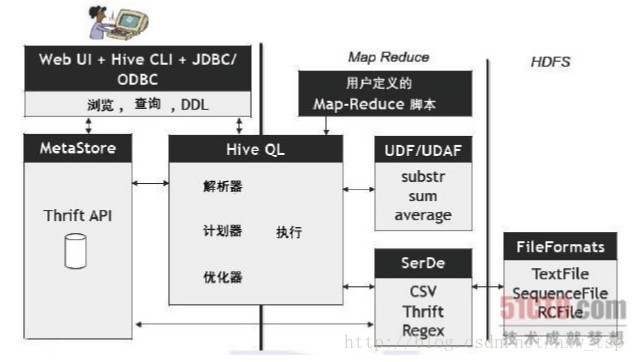
数据在HDFS的warehouse目录下,一个表对应一个子目录。
本地的/tmp目录存放日志和执行计划
hive的表分为两种,内表和外表。
Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。
在删除表的时候,内部表的元数据和数据会被一起删除, 而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
使用Mysql作为Hive metaStore的存储数据库
其中主要涉及到的表如下:
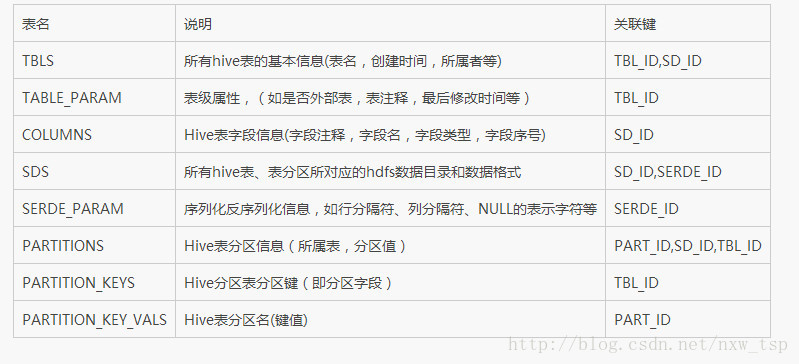
但是对于一个菜鸟来说,看完这些还是有点云里雾里。
下面来看他们的异同。
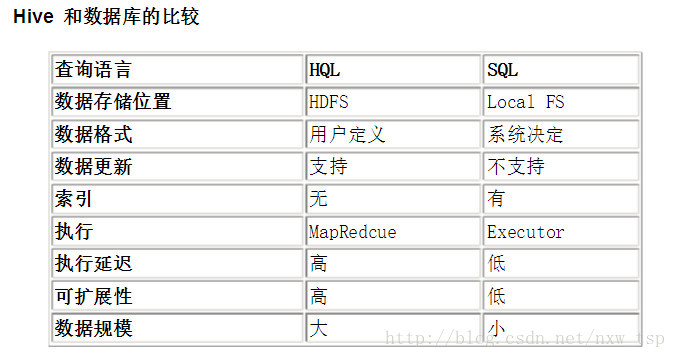
查询语言。由于 SQL 被广泛的应用在数据仓库中,因此,专门针对 Hive 的特性设计了类 SQL 的查询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。
数据存储位置。Hive 是建立在 Hadoop 之上的,所有 Hive 的数据都是存储在 HDFS 中的。而数据库 则可以将数据保存在本地文件系统中。
数据格式。Hive 中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三 个属性:列分隔符(通常为空格、”\t”、”\x001″)、行分隔符(”\n”)以及读取文件数据的方法(Hive 中默认有三个文件格式 TextFile,SequenceFile 以及 RCFile)。由于在加载数据的过程中,不需要从用户数据格式到 Hive 定义的数据格式的转换,因此,Hive 在加载的过程中不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的 HDFS 目录中。而在数据库中,不同的数据库有不同的存储引擎,定义了自己的数据格式。所有数据都会按照一定的组织存储,因此,数据库加载数据的过程会比较耗时。
数据更新。由于 Hive 是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive 中不 支持对数据的改写和添加,所有的数据都是在加载的时候中确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO … VALUES 添加数据,使用 UPDATE … SET 修改数据。
索引。之前已经说过,Hive 在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描, 因此也没有对数据中的某些 Key 建立索引。Hive 要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于 MapReduce 的引入, Hive 可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive 仍然可以体现出优势。数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询。
执行。Hive 中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的(类似 select * from tbl 的查询不需要 MapReduce)。而数据库通常有自己的执行引擎。
执行延迟。之前提到,Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外 一个导致 Hive 执行延迟高的因素是 MapReduce 框架。由于 MapReduce 本身具有较高的延迟,因此在利用 MapReduce 执行 Hive 查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive 的并行计算显然能体现出优势。
可扩展性。由于 Hive 是建立在 Hadoop 之上的,因此 Hive 的可扩展性是和 Hadoop 的可扩展性是 一致的(世界上最大的 Hadoop 集群在 Yahoo!,2009年的规模在 4000 台节点左右)。而数据库由于 ACID 语义的严格限制,扩展行非常有限。目前最先进的并行数据库 Oracle 在理论上的扩展能力也只有 100 台左右。
数据规模。由于 Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模的 数据;对应的,数据库可以支持的数据规模较小。
看了这些,我说为什么hive查询数据怎么这么慢呢。
最后再来一下数据库和数据仓储的区别。
> 数据库是面向事务的设计,数据仓库是面向主题设计的。 数据库一般存储在线交易数据,数据仓库存储的一般是历史数据。
> 数据库设计是尽量避免冗余,一般采用符合范式的规则来设计,数据仓库在设计是有意引入冗余,采用反范式的方式来设计。
> 数据库是为捕获数据而设计,数据仓库是为分析数据而设计,它的两个基本的元素是维表和事实表。(维是看问题的角度,比如时间,部门,维表放的就是这些东西的定义,事实表里放着要查询的数据,同时有维的ID)
以上文章部分内容来自与网络。
智能推荐
理解崩溃和崩溃日志(WWDC 2018 session 414)_4418 崩溃-程序员宅基地
文章浏览阅读1.8k次。WWDC 2018 session 414: Understanding Crashes and Crash Logs每个人在写代码的时候,或多或少都会犯错。有的错误就会导致程序崩溃,这非常影响用户体验。本session主要介绍崩溃的原理,他们为什么会发生,以及如何查看、分析崩溃日志,找到并解决问题。基础知识崩溃是什么?崩溃指的是应用程序在尝试执行不允许的操作时,突然中止的..._4418 崩溃
九度1167 数组排序-程序员宅基地
文章浏览阅读1.2k次。/********************************* * 日期:2013-1-29 * 作者:SJF0115 * 题号: 九度1167 * 题目:数组排序 * 来源:http://ac.jobdu.com/problem.php?pid=1167 * 结果:AC * 题意: * 总结:****************
组合预测模型 | GA-LSTM遗传算法优化长短期记忆网络多输入单输出数据回归预测模型(Matlab程序)-程序员宅基地
文章浏览阅读397次。组合预测模型 | GA-LSTM遗传算法优化长短期记忆网络多输入单输出数据回归预测模型(Matlab完整程序)_ga-lstm
文件操作工具类FileUtil_fileutil依赖-程序员宅基地
文章浏览阅读1.1k次。分享一个文件处理的工具类,依赖如下: <dependency> <groupId>org.apache.ant</groupId> <artifactId>ant</artifactId> <version>1.10.5</versi..._fileutil依赖
(附源码)spring boot火车订票系统 毕业设计 031012_火车购票系统三层数据流-程序员宅基地
文章浏览阅读1.3k次,点赞9次,收藏42次。车订票系统主要功能模块包括系统用户管理、车票中心、购票订票、退票纪录,采取面对对象的开发模式进行软件的开发和硬体的架设,能很好的满足实际使用的需求,完善了对应的软体架设以及程序编码的工作,采取MySQL作为后台数据的主要存储单元,采用Springboot框架、JSP技术、Ajax技术进行业务系统的编码及其开发,实现了本系统的全部功能。_火车购票系统三层数据流
mysql计算上个月,MySQL查询以计算上个月-程序员宅基地
文章浏览阅读95次。I would like to calculate total order amount in the previous month.I got the query for getting the data for the present month from the current date.SELECT SUM(goods_total) AS Total_Amount FROM orders..._mysql last month
随便推点
禾川Q1系列PLC官方教程_禾川学院培训资料-程序员宅基地
文章浏览阅读3.2k次。禾川Q系列PAC教程_禾川学院培训资料
Eclipse详细安装教程_eclipse的安装步骤-程序员宅基地
文章浏览阅读9.3k次,点赞7次,收藏26次。Eclipse安装教程前言一、Eclipse是什么?二、安装步骤1. Eclipse下载下载网址2. Eclipse安装前言Eclipse 是一个开放源代码的、基于Java的可扩展开发平台。一、Eclipse是什么?Eclipse 是一个开放源代码的、基于Java的可扩展开发平台。就其本身而言,它只是一个框架和一组服务,用于通过插件组件构建开发环境。幸运的是,Eclipse 附带了一个标准的插件集,包括Java开发工具(Java Development Kit,JDK)。二、安装步骤1. E_eclipse的安装步骤
计算机组成原理练习题_在底数取16及尾数为二进制的浮点数中,为了保持数值不变,阶码加1,尾数要( )。-程序员宅基地
文章浏览阅读497次,点赞20次,收藏21次。4. (单选题, 7分)计算机问世至今,新型机器不断推陈出新,不管怎样更新,依然保有“存储程序”的概念,最早提出这种概念的是( )。3. (单选题, 5分)在底数取 16及尾数为二进制的浮点数中 , 为了保持数值不变 , 阶码加 1, 尾数小数点要_( )__。2. (单选题, 5分)若浮点数的机器表示中,尾数用补码表示,则判断该浮点数是否为规格化的方法是尾数的最高数值位__( )__。5. (单选题, 5分)x=+0. 1011, y=+0. 0110,用补码运算得到[x-y]补 =___( )__。_在底数取16及尾数为二进制的浮点数中,为了保持数值不变,阶码加1,尾数要( )。
2013年东北c语言考试题答案,2013东北大学c语言试题-程序员宅基地
文章浏览阅读104次。信息学院 2013-2014 学年第 1 学期 程序设计基础 试题 a总分 班 级装一二 30三 24四 26五六七八九十(10) 若有说明语句:int *p,a;则能通过 scanf 语句正确给输入项读入数据 的程序段是_______。 A) *p=&a; scanf(“%d”,p); B) *p=&a; scanf(“%d”,*p); C) p=&a; scanf(“%..._c语言中的数据的类型不同,在内存中占据不同长度的存储单元
Meta 的 LLaMa 2 许可证并非开源许可证-程序员宅基地
文章浏览阅读347次。作者有幸受邀参加 Linux 基金会 7 月 27 日在瑞士日内瓦举办的 Open Source Congress,议程如下:https://oscongress2023.sched.com/。我看到了互动讨论环节建议参会者预先阅读的一些报告和文章里,其中有一篇 OSI 的博客《Meta 的 LLaMa 2 许可证不是开源许可证》,特别引起了我的注意,也因此取得了 OSI 的同意,将它翻译出来..._2023年7月20日,开源组织osi(open source initiative)发文指出,llama 2所适用的许
XSS 跨站点脚本漏洞详解_xss变形-程序员宅基地
文章浏览阅读307次。xss攻击手法以及绕过防御_xss变形