论文导读 | 大语言模型中应用到的强化学习算法_大模型 强化学习-程序员宅基地
摘要
在最近取得广泛关注的大规模语言模型(LLM)应用强化学习(RL)进行与人类行为的对齐,进而可以充分理解和回答人的指令,这一结果展现了强化学习在大规模NLP的丰富应用前景。本文介绍了LLM中应用到的RL技术及其发展路径,希望给读者们一些将RL更好地应用于大规模通用NLP系统的提示与启发。
大规模语言模型向RL的发展
语言模型(LM)是一种编码和理解自然语言的NLP模型。早期的Word2Vec等研究工作试图进行字词编码表示语义,但这一做法讲所有字/词的语义编码固定,无法充分利用上下文信息处理一词多义等复杂语义。因此,以BERT为代表的LM通过预训练学习整句的语义表示,达到了更好的自然语言理解性能。此后,一系列研究扩大了语言模型的规模(LLM),其参数在近几年达到了千亿量级,同样取得了进一步的表现提升;为了充分利用LLM的能力,T5等工作提出了基于prompt的自然语言理解和生成范式。
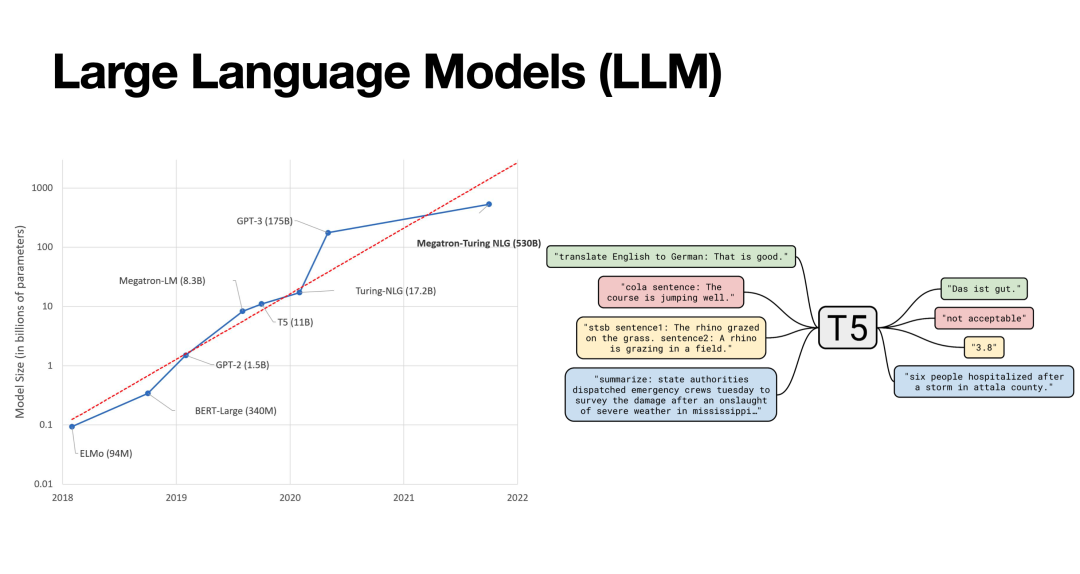
LLM固然有很强的自然语言理解能力,但我们还是希望它能成为人类的好助手。从这个角度上看,让LLM的行为与人类“对齐”,使其能够理解人类指令并做出对人有帮助的回答,是一个亟待解决的问题。为此,以InstructGPT为代表的一系列工作便尝试通过强化学习让LLM与人类的行为对齐。
具体而言,这些工作通过一个反馈模型(RM)模拟一个人对LLM输出的偏好程度打分,并让LLM利用这一反馈优化其输出策略,进而得到一个能输出“令人满意”的内容的LLM。那么如何让LLM根据RM的反馈优化策略?这便是强化学习所擅长解决的问题,下文将介绍其使用的主要方法;而这一利用“人”的反馈进行强化学习的思路也被称为RLHF。

策略梯度:强化学习的基础方法
如上所述,强化学习是一种利用反馈来学习策略的范式。具体而言,如下图所示,强化学习的模型(Agent)与环境交互,对于每个给定状态st采取动作at并从环境获得奖励rt,同时进入下一状态s[t+1],这一过程循环往复。在积累了这一系列交互经验后,模型通过调整自己的策略以让交互过程得到的奖励最大化。这样一来Agent就学习到了在给定状态下采取有益的动作的策略,实现了强化学习的目标。
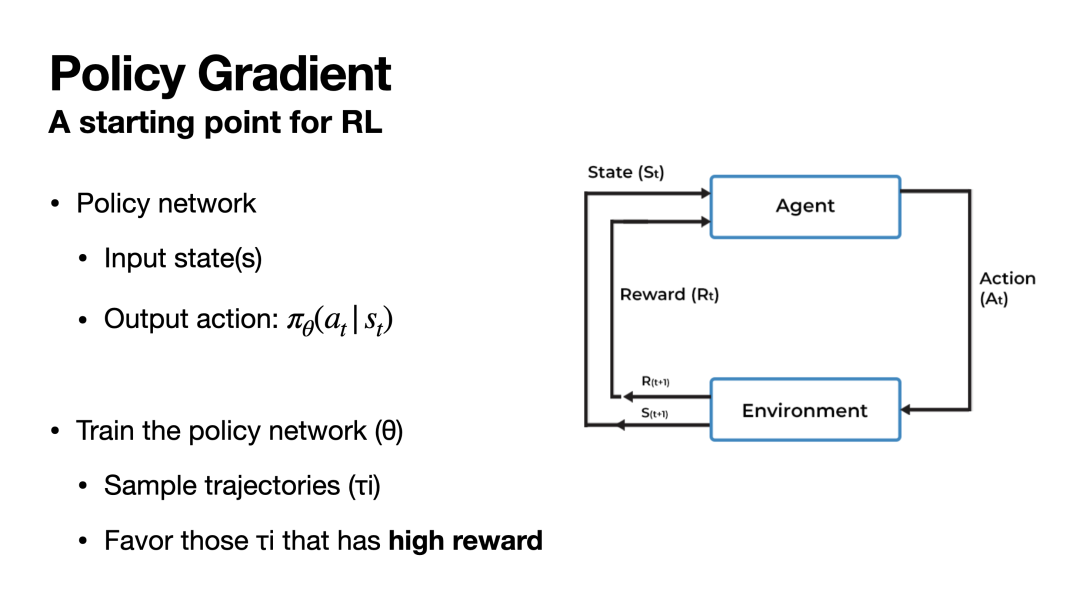
那么,如何调整策略以最大化奖励呢?换言之,如何设计一个可学习的优化目标,使奖励最大化呢?下图的公式就实现了这一目标。具体而言,我们首先与环境进行一系列交互,从初始状态s1开始到结束状态s_final,模型依次做出了动作a1~an并分别获得了奖励r1~rn,在每步做决策时,模型都会给出概率分布π(at|st)。这一从开始到结束的交互过程我们称之为一条轨迹,将这条轨迹的所有奖励求和即可得到轨迹的总奖励R(π)。
不难发现,上图中的公式就衡量了给定策略下采样若干轨迹所能得到的期望奖励,利用梯度上升优化这一目标即可使得策略往“奖励更大”的方向优化,即得到更优的策略。这一直接的思路被称为策略梯度,是RL的基础方法之一。

策略梯度的问题与优化
策略梯度方法虽然直观,但在实践中往往难以取得效果,这是因为每条轨迹的奖励本身具有较大的方差,可能导致训练难以收敛。具体而言,如果有些较大价值的轨迹没有被采样到,根据现有优化目标,模型可能反而会提升一些价值较小的轨迹的策略概率。因此,如果我们能让奖励有正有负,坏于平均值的奖励被认定为负数,这样即便只采样到这些不太好的轨迹,我们仍然能让模型对这些轨迹的策略概率下降。
这便是Baseline的思想:通过一个变量b估计所有轨迹奖励的平均水平,并在最终的优化目标中将轨迹的奖励减去b,即可实现奖励的有正有负。这样一来策略梯度训练就可以变得稳定一些。
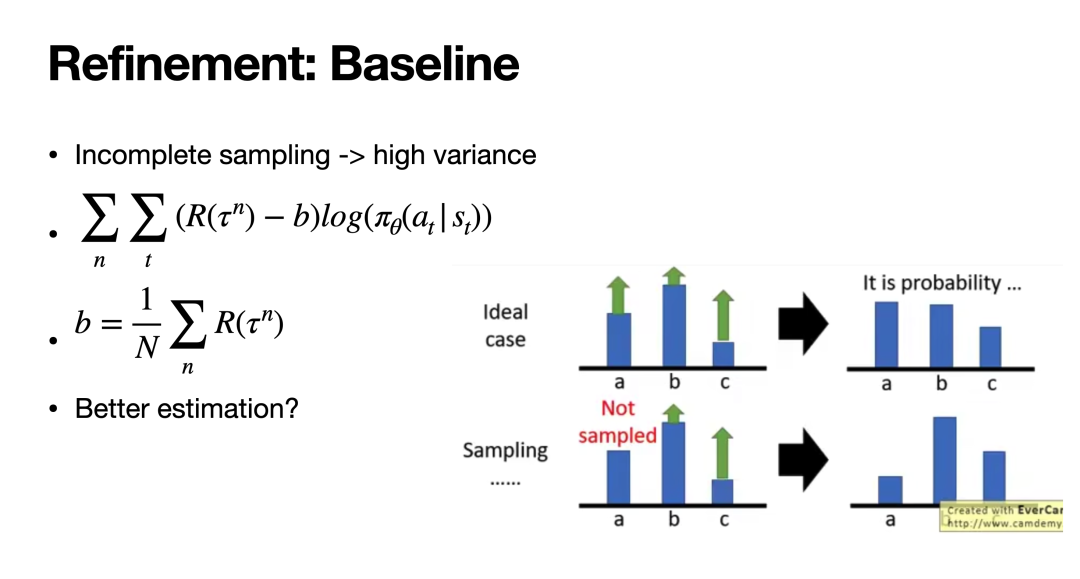
然而,引入baseline并没有彻底解决方差的问题。一方面,b本身也需要通过采样-平均来估计,这本身无法保证b的准确性;另一方面,上述所有计算都是针对一些采样到的轨迹计算得到的奖励,这可能与轨迹真正的价值存在偏差。因此,我们希望直接估计某条轨迹的“价值”,亦即它的总奖励的期望,这便是接下来即将介绍的Actor-Critic的思想。
Q-learning 与 Actor-Critic
如上所述,我们希望估计 R(τ)-b 的期望。从另一个角度理解,这个值也可以被视为在st上采取动作at后,未来的期望收益能带来多大的提升。我们将这个值的期望写作A(st,at),这个A是优势函数(Advantage)的缩写。那么,这个优势函数又该如何计算呢?

为此,我们需要先简单介绍一下Q-learning相关的概念。现在我们用V(s)代表采取某种策略下,状态s后所能获得的期望收益。如果我们能准确估计V(s),那优势函数即可被表示为 A(st,at) = rt+V(s[t+1])-V(st)。这是因为优势函数衡量的就是在st下采取at后,相比起采取其他动作能带来多少额外收益;在st下采取at本身获得了奖励rt,在之后有期望收益V(s[t+1]),而本来采取所有其他动作所对应的期望收益就是V(st)。显然,上式是优势函数的一个正确表示。

最后,我们只需要考虑如何估计V函数即可。值得注意的是,对V的估计本身就是强化学习中另一主流分支Q-learning的研究课题,在这一领域内有大量的研究(DQN、Double-DQN等),在这里我们只介绍最基础、最直觉的V估计方法。如下图所示,顾名思义,既然V(s)衡量状态s以后的期望收益,我们可以直接采样轨迹,平均所有采样到的s后收益来衡量V,这一方法被称为Monte-Carlo(MC)。这种基于采样的方法同样具有较高的方差,为了提高稳定性,我们可以利用动态规划的思路,即如果st转换到s[t+1]获得了收益rt,那这两个状态的价值应满足V(st)=rt+V(s[t+1])。基于这种状态转移方程来训练V网络的方式被称为Temporal Difference(TD)。

完成了对V的估计,我们便可以利用优势函数训练策略网络了。在训练中我们会同时训练两个模型,一个是策略网络(Actor),一个是估计V的估值网络(Critic),因此这类方法也被称为Actor-Critic(AC)。
PPO
Actor-Critic虽然解决了方差高的问题,但在实践中仍可能遇到困难。具体而言,训练AC时需要与环境交互来采样很多轨迹,然后利用这些轨迹训练Actor和Critic;然而,这一过程是十分费时的,这可能导致我们无法高效的采集大量数据,进而充分的训练模型。因此,我们考虑是否能将已有的轨迹数据复用以提高训练效率。
这一思路将我们指向了off-policy RL的道路。具体而言,我们希望有两个策略网络π1和π2,其中π1不断与环境交互收集数据,这些数据可以重复使用以训练π2的参数。这看似能够解决上述问题,但不难发现,如果通过π1来采样数据,π2上的优化目标的期望可能发生改变(下图)。换言之,利用这种方式来训练会偏移我们最初“最大化期望收益”的目标,造成不良的收敛效果。

为保持优化目标的等价性,我们可以利用importance sampling的思想,在原函数后乘上两个分布的概率比例,再重新求期望(下图),这样即可满足从π1采样和从π2采样的等价性。
但这又引入了一个问题,虽然此时二者期望相等,后者的方差可能显著大于前者,进而再次导致训练不稳定。可以证明,如果我们保证π1与π2的分布不相差太远,后者的方差便不会显著增大。因此,在进行off-policy RL时我们还需要尽量控制π1与π2间的差距。

将上述内容总结,即可得到Off-policy RL的总体思路:优化调整后的训练目标,同时保证π1与π2分布的KL散度尽量小,如下图所示。值得注意的是,优化目标中的π2/π1项是一个标量而非概率分布向量,在求梯度时它是不可导的(不像后面的log(π2)可导),因此,在求梯度后,下图中第一行的优化目标实际上与第二行等价,因此我们实际上可以用更简洁的第二行作为训练中的实际优化目标。

有了这些铺垫,我们终于得到了一个可以高效训练的RL算法:Proximal Policy Optimization(PPO),近期获得很大关注的InstructGPT、ChatGPT便在底层使用了PPO进行强化学习。PPO是一种对上述Off-policy RL目标的实现,分析其优化目标不难发现,它首先最大化原始优化目标A*π2/π1,其次又防止π2/π1偏离1太多,即控制了两个分布的差距。实验证明,这一实现相比简单通过KL惩罚项实现的Off-policy RL效果更好。

InstructGPT中的强化学习
最后我们简单介绍一下ChatGPT的核心方法——InstructGPT是如何利用上述方法进行RLHF的。如下图所示,InstructGPT的核心由两个模型构成:1)一个反馈模型(RM),它给定一对模型输入和输出,反馈该输出的合理程度(有多好)打分;2)一个生成式语言模型,给定输出生成一段输出,并利用RM给出的打分作为奖励进行强化学习。只要让RM能很好的反应人类的偏好,我们就可以让生成模型与人类行为进行对齐。
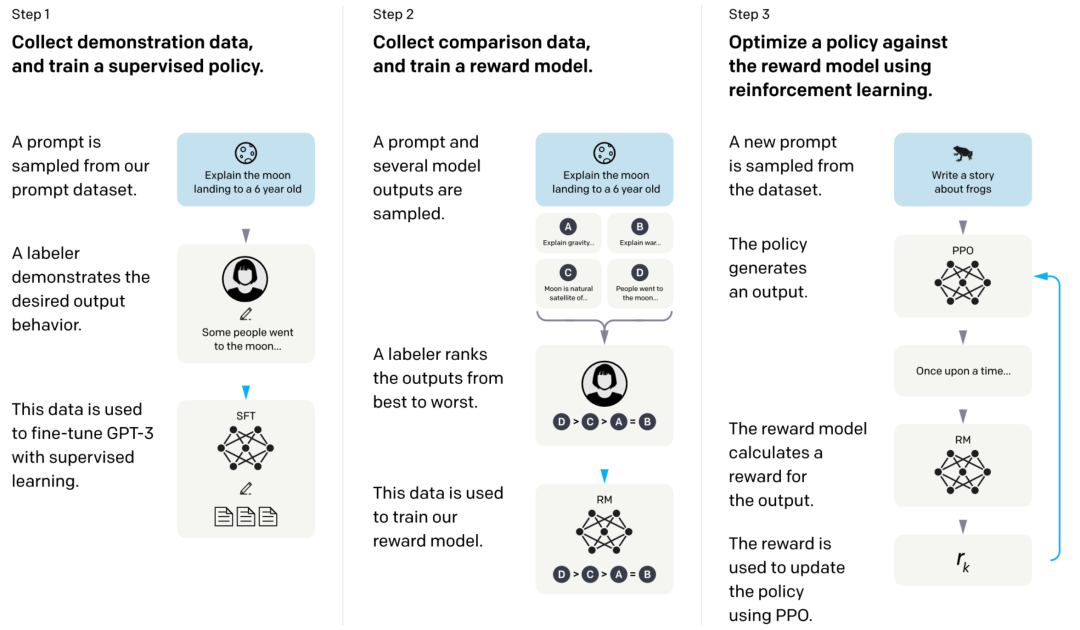
接下来简要介绍训练这两个模型的一些细节。对于RM的训练是很直观的,我们只需人工标注一些偏好数据(例如对于一个输入,我们让模型给出若干输出,并由标注人员对这些输出的好坏程度进行排序),并通过对比学习让RM最大化好输出与坏输出的分数差。
对于生成模型的训练,我们可以将“输入-生成模型输出-RM反馈”作为一个只有一步的轨迹(输入是s1,输出是a1,RM的反馈是奖励),并在这些轨迹上利用PPO进行强化学习。如下图所示,我们只需最大化PPO的优化目标即可实现对生成模型的训练。

总结
本文以大语言模型中应用到的强化学习算法——PPO为核心,介绍了从基础强化学习算法(策略梯度、AC等)到PPO的发展路径、核心问题及解决思路,最后简介了PPO在InstructGPT的应用。希望本文可以启发更多NLP研究者将RL更多、更好的应用在NLP的模型和场景之中。
致谢
部分实例及图表资料源自李宏毅老师的深度强化学习公开课程,感谢他为这一领域研究思路的普及做出的贡献和提出的思考。链接:https://www.youtube.com/playlist?list=PLJV_el3uVTsODxQFgzMzPLa16h6B8kWM_
参考文献
[1] Church K W. Word2Vec[J]. Natural Language Engineering, 2017, 23(1): 155-162.
[2] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[3] Raffel C, Shazeer N, Roberts A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer[J]. The Journal of Machine Learning Research, 2020, 21(1): 5485-5551.
[4] Sutton R S, McAllester D, Singh S, et al. Policy gradient methods for reinforcement learning with function approximation[J]. Advances in neural information processing systems, 1999, 12.
[5] Mnih V, Badia A P, Mirza M, et al. Asynchronous methods for deep reinforcement learning[C]//International conference on machine learning. PMLR, 2016: 1928-1937.
[6] Schulman J, Wolski F, Dhariwal P, et al. Proximal policy optimization algorithms[J]. arXiv preprint arXiv:1707.06347, 2017.
[7] Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. Advances in Neural Information Processing Systems, 2022, 35: 27730-27744.
智能推荐
maven的下载与安装教程(超详细)_maven安装-程序员宅基地
文章浏览阅读10w+次,点赞432次,收藏1.1k次。前言本篇文章是基于win10系统下载安装Maven的教程。一、 Maven介绍1. 什么是Maven Maven是一个跨平台的项目管理工具。作为Apache组织的一个颇为成功的开源项目,其主要服务于基于Java平台的项目创建,依赖管理和项目信息管理。maven是Apache的顶级项目,解释为“专家,内行”,它是一个项目管理的工具,maven自身是纯java开发的,可以使用maven对java项目进行构建、依赖管理。2. Maven的作用依赖管理依赖指的就是是 我们项目中需要使用的第三方_maven安装
研究生如何读文献 写论文 发文章 毕业论文_研究生一天读多少文献-程序员宅基地
文章浏览阅读2.1k次,点赞3次,收藏13次。研究生论文写作步骤1. 先看综述,后看论著。看综述搞清概念,看论著掌握方法。2. 早动手在师兄师姐离开之前学会关键技术。3. 多数文章看摘要,少数文章看全文。掌握了一点查全文的技巧,往往会以搞到全文为乐,以至于没有时间看文章的内容,更不屑于看摘要。真正有用的全文并不多,过分追求全文是浪费,不可走极端。当然只看摘要也是不对的。4. 集中时间看文献,看过总会遗忘。看文献的时间越分散_研究生一天读多少文献
微光app电脑版_智米电暖器智能版1S体验:全面领跑AIoT、将智能生活进行到底-程序员宅基地
文章浏览阅读547次。【科技犬体验】2019年10月15日,智米正式推出了旗下电暖器新品——智米电暖器1S和智米电暖器智能版1S对于没有集中供暖的长江中下游地区居民而言,电暖器是不折不扣的"保命神器"。而在深秋的北方,昼夜温差较大,这种时候使用灵活、易于搬运的电暖器也成为更加明智的选择。在北方每年的冬季,室内温度就直接关系着大家在家的舒适度,而对于室内温度不达标的用户,购买电暖器就成为几乎唯一的选择。科技犬已经入手智米..._智米电暖器智能版app
《Hadoop与大数据挖掘》——2.6 TF-IDF算法原理及Hadoop MapReduce实现-程序员宅基地
文章浏览阅读312次。本节书摘来自华章计算机《Hadoop与大数据挖掘》一书中的第2章,第2.6节,作者 张良均 樊哲 位文超 刘名军 许国杰 周龙 焦正升,更多章节内容可以访问云栖社区“华章计算机”公众号查看。2.6 TF-IDF算法原理及Hadoop MapReduce实现2.6.1 TF-IDF算法原理原理:在一份给定的文件里,词频(Term Frequency,..._hadoop mapreduce如何实现实现tf-idf
Layui实现点击文字、缩略图查看图片功能_layui查看图片-程序员宅基地
文章浏览阅读4.3k次。刚完成一个客户需求,同一个页面上要有点击缩略图查看大图功能,也有点击图片名称查看原图的功能。点击缩略图查看大图的功能点击缩略图查看大图的功能实现用的是layui开发文档内的layer.photos-相册层。官方开发文档里photos支持传入json和直接读取页面图片两种方式。下面是官方开发文档的截图,官方开发文档链接:https://www.layui.com/doc/m..._layui查看图片
ueditor的配置和使用-程序员宅基地
文章浏览阅读89次。ueditor下载好之后直接复制到项目的WebContent目录下,并将ueditor\jsp\lib下的jar包复制或者剪切到项目的lib目录下。先看一下效果,如下:v1.文件的上传 首先在ueditor/jsp目录下找到config.json文件,就拿Image上传来说吧。 "imageUrlPrefix": "http:/..._ueditor json = new function("return " + result)();
随便推点
乌龙(一)ntp对时_ntp对时 时区-程序员宅基地
文章浏览阅读107次。emmm…今天新搭了一套虚拟机(安装时一步过了 啥也没配置),操作时发现系统时间一直不对,于是安装了ntp跟阿里云等时钟源对过,发现一对时系统就变成了昨天,我把系统时间强制改为了现在,再次对时,时间又回退到昨天,最后发现时区选错了,选成了PST。解决方法cp -f /usr/share/zoneinfo/Asia/Shanghai /etc/localtime..._ntp对时 时区
数据结构_实验三_二叉树的基本操作_二叉树叶子节点实验-程序员宅基地
文章浏览阅读6.3k次,点赞18次,收藏81次。1.需求分析1.1 输入数据建立二叉树,分别以前序、中序、后序的遍历方式显示输出二叉树的遍历结果。输入输出形式:124$$5$3$$preOrder1 2 4 5 3inOrder4 2 5 1 3afterOrder4 5 2 3 1功能:利用树存储数据,采用递归的方式做到先序、中序、后序三种遍历方式输出数据范围:0~9测试数据: 124$$5$3$$ ..._二叉树叶子节点实验
P5738 【深基7.例4】歌唱比赛-程序员宅基地
文章浏览阅读311次。题目描述n(n\le 100)n(n≤100)名同学参加歌唱比赛,并接受m(m\le 20)m(m≤20)名评委的评分,评分范围是 0 到 10 分。这名同学的得分就是这些评委给分中去掉一个最高分,去掉一个最低分,剩下m-2m−2个评分的平均数。请问得分最高的同学分数是多少?评分保留 2 位小数。输入格式无输出格式无输入输出样例输入 ..._【深基7.例4】歌唱比赛
Vue简明实用教程(04)——事件处理_vue html里面如何直接写事件函数-程序员宅基地
文章浏览阅读1.1k次,点赞4次,收藏5次。在Vue中可非常便利地进行事件处理,例如:点击事件、鼠标悬停事件等。_vue html里面如何直接写事件函数
南京邮电大学离散数学实验一(求主析取和主合取范式)-程序员宅基地
文章浏览阅读4.5k次,点赞15次,收藏67次。南京邮电大学离散数学实验一(求主析取和主合取范式)_离散数学实验
{spring.cloud.client.ipAddress}_spring.cloud.client.ip-address-程序员宅基地
文章浏览阅读1.5w次,点赞2次,收藏5次。1.在springcloud中服务的 Instance ID 默认值是:${spring.cloud.client.hostname}:${spring.application.name}:${spring.application.instance_id:${server.port}},也就是:主机名:应用名:应用端口。如图12.可以自定义:eureka.instance...._spring.cloud.client.ip-address