SHA算法系列介绍-程序员宅基地
小明:老师,有个问题不懂。
老师:什么问题,说吧。
小明:我最近在研究微信支付接口,发现它不仅支持MD5摘要的验签,还支持SHA-256摘要。这个SHA是什么鬼?
老师:和MD5算法类似,SHA(Secure Hash Algorithm)也是一种生成信息摘要的算法。
小明:可是我看到网上以SHA命名的算法五花八门,什么SHA-1,SHA2,SHA-256等等,为什么会有这么多名字呢?
老师:这是因为SHA算法分为很多版本。最大的版本分类是SHA-1和SHA-2,SHA-2又包含了很多子版本。
老师:SHA-2的子版本包括SHA-224,SHA-256,SHA-384,SHA-512。这些版本共同构成了SHA的大家族。
小明:SHA算法和MD5算法有什么区别呢?SHA的这么多版本之间又有什么不同?
老师:要回答这个问题,我们先从SHA-1说起吧。
SHA-1
SHA-1算法可以从明文生成160bit的信息摘要,示例如下:
给定明文:abcd
SHA-1摘要:81FE8BFE87576C3ECB22426F8E57847382917ACF
SHA-1 与 MD5的主要区别是什么呢?
1.摘要长度不同。
MD5的摘要的长度尽128bit,SHA-1摘要长度160bit。多出32bit意味着什么呢?不同明文的碰撞几率降低了2^32 = 324294967296倍。
2.性能略有差别
SHA-1生成摘要的性能比MD5略低。
小明:SHA-1这么强大,应该没人能破解吧?
老师:很遗憾,早在2005年,人们就研究出了破解SHA-1的方法。近期谷歌的Chrome小组也宣城要淘汰SHA-1。
小明:连SHA-1都不安全了,这可怎么办?
老师:别担心,我们还有更安全的算法SHA-2。
SHA-2
SHA-2是一系列SHA算法变体的总称,其中包含如下子版本:
SHA-256:可以生成长度256bit的信息摘要。
SHA-224:SHA-256的“阉割版”,可以生成长度224bit的信息摘要。
SHA-512:可以生成长度512bit的信息摘要。
SHA-384:SHA-512的“阉割版”,可以生成长度384bit的信息摘要。
显然,信息摘要越长,发生碰撞的几率就越低,破解的难度就越大。但同时,耗费的性能和占用的空间也就越高。
小明:为什么SHA-2要有这么多的版本呢?只使用最长的一种不就行了吗?
老师:这是为了适应不同的应用场景,从而对安全、性能、空间等因素做出权衡。比如说过我的需求仅仅是验证数据完整性,使用SHA-512显然是浪费了。另外,如果想要追求安全性,也可以考虑把多种摘要算法结合使用。比如下面这样:
明文: abcd
MD5摘要:e2fc714c4727ee9395f324cd2e7f331f
SHA-256摘要:
88d4266fd4e6338d13b845fcf289579d209c897823b9217da3e161936f031589
合成摘要:e2fc714c4727ee93209c897823b9217da3e161936f031589
取MD摘要的前16和SHA-256摘要的后32位,拼成一个长度48位的合成摘要。这样除非知道拼接规则,否则外人是无从破解的。
小明:还真是个好办法。最后一个问题,SHA-1和SHA-2系列算法生成摘要的底层原理是什么样呢?
老师:SHA算法的底层原理和MD5很相似,只是在摘要分段和处理细节上有少许差别。
我们先来回顾一下MD5算法的核心过程,简而言之,MD5把128bit的信息摘要分成A,B,C,D四段(Words),每段32bit,在循环过程中交替运算A,B,C,D,最终组成128bit的摘要结果。
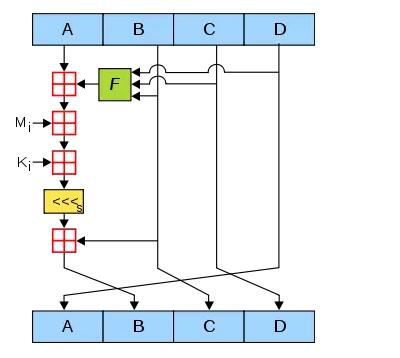
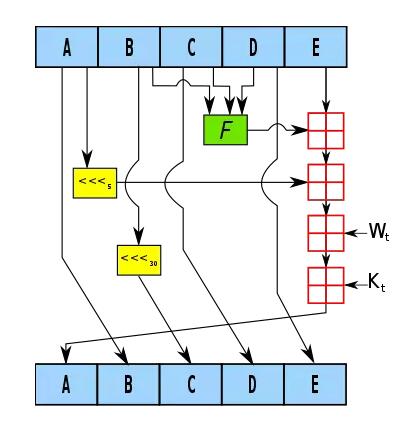
再看一下SHA-1算法,核心过程大同小异,主要的不同点是把160bit的信息摘要分成了A,B,C,D,E五段。
再看一下SHA-2系列算法,核心过程更复杂一些,把信息摘要分成了A,B,C,D,E,F,G,H八段。
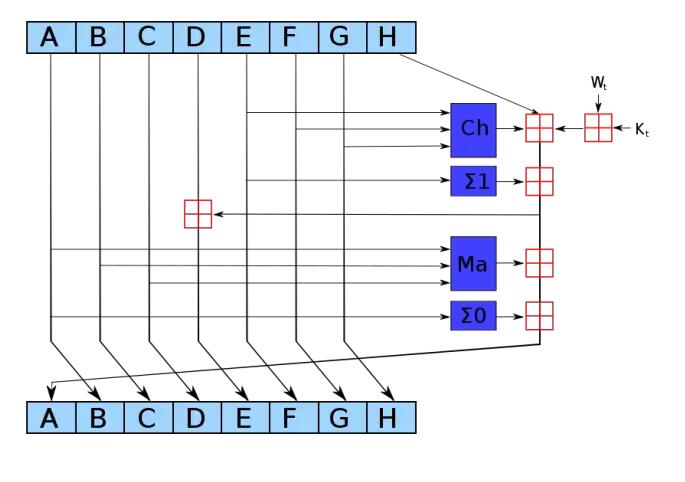
其中SHA-256的每一段摘要长度是32bit,SHA-512的每一段摘要长度是64bit。SHA-224和SHA-384则是在前两者生成结果的基础上做出裁剪。
几点补充:
SHA家族的最新成员SHA-3已经于2015年问世。关于SHA-3的细节,有兴趣的小伙伴们可以查询资料进一步学习。

智能推荐
(最终)如何利用印象笔记搭建自己的知识体系_印象笔记建立个人知识体系-程序员宅基地
文章浏览阅读1k次。1、 为什么要记录笔记这个问题我印象中探讨过很多次,但是简单来讲就是方便日后在遇到相似问题时查询解决方式,并在记录笔记的过程汇总中对知识进行一轮新的复习。这样一生,如果作为一个技术人员来讲的话,我不可能只学习一门技能,需要学习的东西很多。当只会一门技能时,做不做笔记其实无所谓,但是当你学会多种技能时,你需要笔记这样一个第二大脑来帮助存储那些琐碎并不通用的知识,你自己的大脑来记忆通用性的知识,可以迁移的方法。在遇到问题时,知道做什么永远比怎么做更重要。1.1 知识的分类1.1.1 元认知解释:能指导_印象笔记建立个人知识体系
FATFS文件系统详解-程序员宅基地
文章浏览阅读2.7k次,点赞13次,收藏96次。随着硬盘/flash容量不断增大,存储的数据也越来越多,早期单一的对应地址存放对应数据的方案已经无法满足我们的需求,因此一群大佬们便开始设计文件系统这样一个东西,用来管理硬盘/flash上的数据信息。本文主要分享关于FAT文件系统的详细设计。通过对FAT文件系统组成介绍,字段分析并采用新增文件实践分析的方式,详细阐述FAT文件系统的工作原理!_fatfs
【企业架构师】12 项企业架构师认证-程序员宅基地
文章浏览阅读3k次,点赞2次,收藏7次。企业架构师是使 IT 战略与业务目标保持一致的重要且不断增长的角色。无论您对云、应用程序、软件还是系统感兴趣,企业架构认证都可以提升您的职业生涯。如果您计划从事企业架构师 (EA) 的职业,那么认证是验证您的 EA 技能的好方法。作为 EA,您将负责为企业制定 IT 战略,以使业务目标与 IT 目标保持一致。公司严重依赖技术,因此 IT 现在是任何强大业务战略的基础部分。..._企业架构师认证
如何构建一个自己的代理ip池_如果制作代理ip池-程序员宅基地
文章浏览阅读5.9k次,点赞2次,收藏29次。相比前两种搭建IP池的方法来说,付费代理IP更能满足用户的需求,但对于有些特殊要求的朋友来说,他们想一次提取很多个或者多次提取很多个,存放在本地建立的IP池里,这种方法在一定的程度上优化了方案。只不过长期下来的话,服务器的维护成本较高,并且需要定时的维护,消耗大量的时间,如果是个人的话,搭建起来后期维护的成本太高了,如果您不是高端玩家的话,不建议使用这种方式搭建IP池。相对于免费的代理IP来说,收费代理IP虽然需要付出一定的成本,但是IP资源都是真实IP,并且高匿性,稳定性也好。一、默认自动切换IP。..._如果制作代理ip池
Linux下解压与压缩命令_linux解压rpm-程序员宅基地
文章浏览阅读4.3k次,点赞4次,收藏34次。本文主要是总结题主在学习与工作中使用到的Linux环境下解压与压缩命令,内容不算很全,但是囊括了大部分需求场景,如有误笔之处,还请同学指正。_linux解压rpm
前端展示后台服务器中图片的功能实现_前端访问后端图片展示-程序员宅基地
文章浏览阅读451次,点赞11次,收藏8次。这里的按钮我是放在了table表格的末尾,目的是获取每一行中的批次号,然后根据批次号读取后台服务器的图片,并且展示在前端的dialog中。有图片的效果图,这里只是做了个测试,图片的大小暂时还未调整。主要是一个接口还有个工具类,代码如下。dialog部分的代码。_前端访问后端图片展示
随便推点
SpringSecurity6 | 核心过滤器-程序员宅基地
文章浏览阅读1.4w次,点赞27次,收藏21次。大家好,我是Leo哥,上一节我们通过源码剖析以及图文分析,了解了关于委派筛选器代理和过滤器链代理的原理和作用。这节课我们接着学习SpringSecurity的过滤器,了解SpringSecurity中都有哪些核心过滤器。好了,话不多说让我们开始吧。以上便是本文的全部内容,本人才疏学浅,文章有什么错误的地方,欢迎大佬们批评指正!我是Leo,一个在互联网行业的小白,立志成为更好的自己。如果你想了解更多关于Leo,可以关注公众号-程序员Leo,后面文章会首先同步至公众号。
面试ASP.NET程序员的笔试题和机试题-程序员宅基地
文章浏览阅读128次。面试 一般会叫你填两个表 1个是你的详细信息表 1个是面试题答卷 两个都要注意反正面是否都有内容不要遗漏,如果考你机试一般也有两种,就是程序连接数据库或一些基本的算法(二分查找,递归等),公司一般都是测试你的基本功是否扎实,如果你基本功好就游刃有余不必紧张! asp.net面试题 1.new有几种用法 第一种:new Class(); 第二种:覆盖方法 public new XXXX()..._.net面试机试题
【二、大数据环境篇】001、方法论_方法论semma-程序员宅基地
文章浏览阅读405次。1、官网的文档无论是学习Hadoop的hdfs、hive,还是hbase等,都要非常看重官网的文档。大数据的很多框架,都是Apache的顶级项目,各个组件框架的官网链接都可以从下面的链接进入:Hadoop:http://hadoop.apache.org/Avro: 序列化系统HBase: 分布式数据库Hive: 数据仓库Mahout: 机器学习与数据挖掘库Pig: 并行计算的高级数据..._方法论semma
LDA算法的数学推导过程详解-程序员宅基地
文章浏览阅读411次,点赞8次,收藏21次。主题模型是自然语言处理和文本挖掘领域的一个重要研究方向,它可以自动发现文档集合中潜在的主题结构。其中,潜在狄利克雷分配(Latent Dirichlet Allocation, LDA)是最常用和最成功的主题模型之一。LDA是一种无监督的贝叶斯概率模型,能够有效地发现文档集合中隐藏的主题结构。LDA模型的核心思想是:每个文档可以表示为多个主题的概率分布,每个主题又可以表示为词语的概率分布。通过学习这些潜在的主题分布和词语分布,LDA模型可以发现文档集合中蕴含的语义主题信息。
Python利用fitz库提取pdf中的图片(针对多种类型pdf)_import fitz-程序员宅基地
文章浏览阅读2.3w次,点赞17次,收藏98次。目录一. 安装fitz二. pdf文件格式问题2.1 pdf文件存在多种格式2.2 分析问题三. 代码一. 安装fitz安装:需要安装fitz和PyMuPDF,否则会报如下错误:ModuleNotFoundError: No module named ‘frontend’pip install fitz PyMuPDF二. pdf文件格式问题2.1 pdf文件存在多种格式pdf文件的格式有好几种,用Adobe Acrobat比较正常的如下所示:这种类型的pdf文件可以比较正常地提取里面的图片_import fitz
for循环倒序java_for循环-程序员宅基地
文章浏览阅读5.4k次。除了while和do while循环,Java使用最广泛的是for循环。for循环的功能非常强大,它使用计数器实现循环。for循环会先初始化计数器,然后,在每次循环前检测循环条件,在每次循环后更新计数器。计数器变量通常命名为i。我们把1到100求和用for循环改写一下:// for----public class Main {public static void main(String[] arg..._java for 倒序