深度学习(9)之 easyOCR使用详解-程序员宅基地
技术标签: python 计算机视觉 深度学习 人工智能 # 深度学习 OCR
easyOCR使用详解
- 本文在 OCR-easyocr初识 基础上进行修改
- EasyOCR 是一个python版的文字识别工具。目前支持80中语言的识别。其对应的 github 地址:EasyOCR
- 可以在网站版测试 demo 测试效果:https://www.jaided.ai/easyocr/
- 其在字符识别上的效果如下:

一、介绍
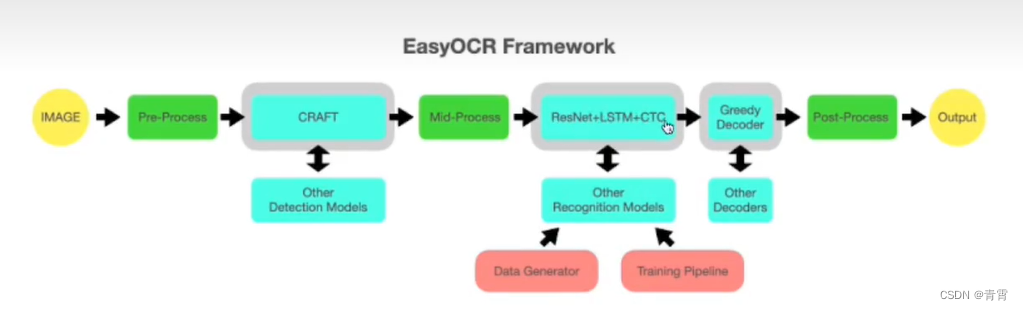
二、安装
- Install using pip
For the latest stable release:
pip install easyocr
For the latest development release:
pip install git+https://github.com/JaidedAI/EasyOCR.git
- 模型储存路径:
windows: C:\Users\username\.EasyOCR\linux:/root/.EasyOCR/
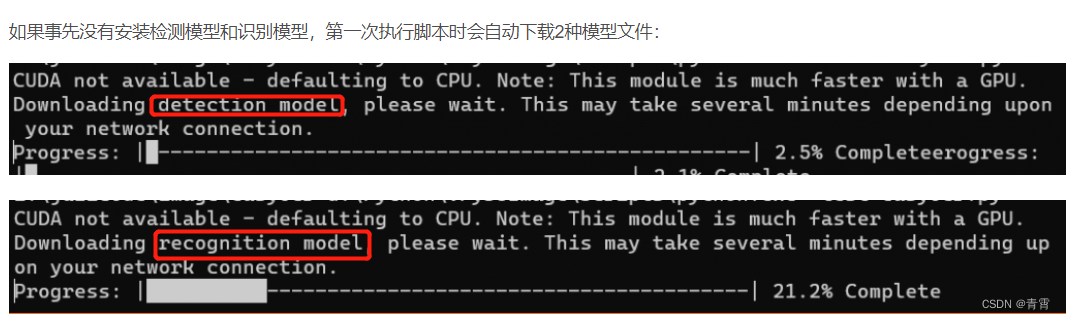

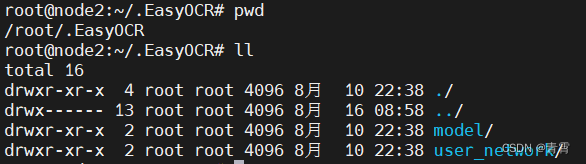
三、API文档
3.1、easyocr.Reader class:
-
lang_list (list) - 识别的语言代码列表,例如 ['ch_sim','en']
-
gpu (bool, string, default = True) - 启用 GPU
-
model_storage_directory (string, default = None) - 模型数据目录的路径。如果未指定,将从环境变量 EASYOCR_MODULE_PATH(首选)、MODULE_PATH(如果已定义)或 ~/.EasyOCR/ 定义的目录中读取模型。
-
download_enabled (bool, default = True) - 如果 EasyOCR 无法找到模型文件,则启用下载;
-
user_network_directory (bool, default = None) - 用户模型存储的路径。如果未指定,将从 MODULE_PATH + '/user_network' (~/.EasyOCR/user_network) 读取模型;
-
recog_network (string, default = 'standard') - 用户模型、模块和配置文件的名称;
-
detector (bool, default = True) - 将检测模型加载到内存中
-
recognizer (bool, default = True) - 将识别模型加载到内存中
-
lang_char - 显示当前模型中的所有可用字符
3.2、reader.readtext()
-
image (string, numpy array, byte) - 输入图像;
-
decoder (string, default = 'greedy')- 选项有 'greedy'、'beamsearch' 和 'wordbeamsearch';
-
beamWidth (int, default = 5) - 当解码器 = 'beamsearch' 或 'wordbeamsearch' 时要保留多少光束;
-
batch_size (int, default = 1) - batch_size>1 将使 EasyOCR 更快但使用更多内存;
-
worker (int, default = 0) - 数据加载器中使用的编号线程;
-
allowlist (string) - 强制 EasyOCR 只识别字符的子集。对特定问题有用(例如车牌等);
-
blocklist (string) - 字符的块子集。如果给定了允许列表,则此参数将被忽略。
-
detail (int, default = 1) - 将此设置为 0 以进行简单输出;
-
paragraph (bool, default = False) - 将结果合并到段落中;
-
min_size (int, default = 10) - 过滤文本框小于最小值(以像素为单位);
-
rotation_info (list, default = None) - 允许 EasyOCR 旋转每个文本框并返回具有最佳置信度分数的文本框。符合条件的值为 90、180 和 270。例如,对所有可能的文本方向尝试 [90, 180 ,270]。
-
contrast_ths (float, default = 0.1) - 对比度低于此值的文本框将被传入模型 2 次。首先是原始图像,其次是对比度调整为“adjust_contrast”值。结果将返回具有更高置信度的那个;
-
adjust_contrast (float, default = 0.5) - 低对比度文本框的目标对比度级别。
-
text_threshold (float, default = 0.7) - 文本置信度阈值
-
low_text (float, default = 0.4) - 文本下限分数
-
link_threshold (float, default = 0.4) - 链接置信度阈值
-
canvas_size (int, default = 2560) - 最大图像尺寸。大于此值的图像将被缩小。
-
mag_ratio (float, default = 1) - 图像放大率
-
slope_ths (float, default = 0.1) - 考虑合并的最大斜率 (delta y/delta x)。低值意味着不会合并平铺框。
-
ycenter_ths (float, default = 0.5) - y 方向的最大偏移。不应该合并不同级别的框。
-
height_ths (float, default = 0.5) - 盒子高度的最大差异。不应合并文本大小非常不同的框。
-
width_ths (float, default = 0.5) - 合并框的最大水平距离。
-
add_margin (float, default = 0.1) - 将边界框向所有方向扩展某个值。这对于具有复杂脚本的语言(例如泰语)很重要。
-
x_ths (float, default = 1.0) - 当段落=True 时合并文本框的最大水平距离。
-
y_ths (float, default = 0.5) - 当段落 = True 时合并文本框的最大垂直距离。
四、识别模型
 https://github.com/JaidedAI/EasyOCR/blob/master/custom_model.md
https://github.com/JaidedAI/EasyOCR/blob/master/custom_model.md4.1、训练识别模型
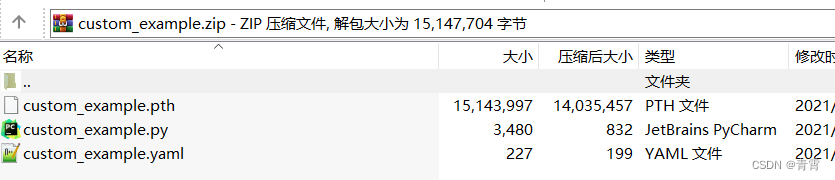
4.2、使用自定义的识别模型
五、使用
5.1、基本使用1
$ easyocr -l ch_sim en -f chinese.jpg --detail=1 --gpu=True
5.2、基本使用2

代码实现如下:
import easyocr
reader = easyocr.Reader(
lang_list=['ch_sim', 'en'], # 需要导入的语言识别模型,可以传入多个语言模型,其中英语模型en可以与其他语言共同使用
gpu=False, # 默认为True
download_enabled=True # 默认为True,如果 EasyOCR 无法找到模型文件,则启用下载
)
result = reader.readtext('id_card.jpg', detail=1 ) # 图片可以传入图片路径、也可以传入图片链接。但推荐传入图片路径,会提高识别速度。包含中文会出错。设置detail=0可以简化输出结果,默认为1
print(result)
readtext 返回的列表中,每个元素都是一个元组,内含三个信息:位置、文字、置信度:
[
([[27, 37], [341, 37], [341, 79], [27, 79]], '姓 名 爱新觉罗 。玄烨', 0.6958897643232619),
([[29, 99], [157, 99], [157, 135], [29, 135]], '性 别 男', 0.914532774041559),
([[180, 95], [284, 95], [284, 131], [180, 131]], '民蔟满', 0.4622474180193509),
([[30, 152], [94, 152], [94, 182], [30, 182]], '出 生', 0.6015505790710449),
([[110, 152], [344, 152], [344, 184], [110, 184]], '1654 年54日', 0.42167866223467815),
([[29, 205], [421, 205], [421, 243], [29, 243]], '住 址 北京市东城区景山前街4号', 0.6362530289101117),
([[105, 251], [267, 251], [267, 287], [105, 287]], '紫禁城乾清宫', 0.8425745057905053),
([[32, 346], [200, 346], [200, 378], [32, 378]], '公民身份证号码', 0.22538012770296922),
([[218, 348], [566, 348], [566, 376], [218, 376]], '000003165405049842', 0.902066405195785)
]
detail=0,从而只返回文字内容:
['姓 名 爱新觉罗 。玄烨', '性 别 男', '民蔟满', '出 生', '1654 年54日', '住 址 北京市东城区景山前街4号', '紫禁城 乾清宫', '公民身份证号码', '000003165405049842']
5.3、基本使用3


智能推荐
获取大于等于一个整数的最小2次幂算法(HashMap#tableSizeFor)_整数 最小的2的几次方-程序员宅基地
文章浏览阅读2w次,点赞51次,收藏33次。一、需求给定一个整数,返回大于等于该整数的最小2次幂(2的乘方)。例: 输入 输出 -1 1 1 1 3 4 9 16 15 16二、分析当遇到这个需求的时候,我们可能会很容易想到一个"笨"办法:..._整数 最小的2的几次方
Linux 中 ss 命令的使用实例_ss@,,x,, 0-程序员宅基地
文章浏览阅读865次。选项,以防止命令将 IP 地址解析为主机名。如果只想在命令的输出中显示 unix套接字 连接,可以使用。不带任何选项,用来显示已建立连接的所有套接字的列表。如果只想在命令的输出中显示 tcp 连接,可以使用。如果只想在命令的输出中显示 udp 连接,可以使用。如果不想将ip地址解析为主机名称,可以使用。如果要取消命令输出中的标题行,可以使用。如果只想显示被侦听的套接字,可以使用。如果只想显示ipv4侦听的,可以使用。如果只想显示ipv6侦听的,可以使用。_ss@,,x,, 0
conda activate qiuqiu出现不存在activate_commandnotfounderror: 'activate-程序员宅基地
文章浏览阅读568次。CommandNotFoundError: 'activate'_commandnotfounderror: 'activate
Kafka 实战 - Windows10安装Kafka_win10安装部署kafka-程序员宅基地
文章浏览阅读426次,点赞10次,收藏19次。完成以上步骤后,您已在 Windows 10 上成功安装并验证了 Apache Kafka。在生产环境中,通常会将 Kafka 与外部 ZooKeeper 集群配合使用,并考虑配置安全、监控、持久化存储等高级特性。在生产者窗口中输入一些文本消息,然后按 Enter 发送。ZooKeeper 会在新窗口中运行。在另一个命令提示符窗口中,同样切换到 Kafka 的。Kafka 服务器将在新窗口中运行。在新的命令提示符窗口中,切换到 Kafka 的。,应显示已安装的 Java 版本信息。_win10安装部署kafka
【愚公系列】2023年12月 WEBGL专题-缓冲区对象_js 缓冲数据 new float32array-程序员宅基地
文章浏览阅读1.4w次。缓冲区对象(Buffer Object)是在OpenGL中用于存储和管理数据的一种机制。缓冲区对象可以存储各种类型的数据,例如顶点、纹理坐标、颜色等。在渲染过程中,缓冲区对象中存储的数据可以被复制到渲染管线的不同阶段中,例如顶点着色器、几何着色器和片段着色器等,以完成渲染操作。相比传统的CPU访问内存,缓冲区对象的数据存储和管理更加高效,能够提高OpenGL应用的性能表现。_js 缓冲数据 new float32array
四、数学建模之图与网络模型_图论与网络优化数学建模-程序员宅基地
文章浏览阅读912次。(1)图(Graph):图是数学和计算机科学中的一个抽象概念,它由一组节点(顶点)和连接这些节点的边组成。图可以是有向的(有方向的,边有箭头表示方向)或无向的(没有方向的,边没有箭头表示方向)。图用于表示各种关系,如社交网络、电路、地图、组织结构等。(2)网络(Network):网络是一个更广泛的概念,可以包括各种不同类型的连接元素,不仅仅是图中的节点和边。网络可以包括节点、边、连接线、路由器、服务器、通信协议等多种组成部分。网络的概念在各个领域都有应用,包括计算机网络、社交网络、电力网络、交通网络等。_图论与网络优化数学建模
随便推点
android 加载布局状态封装_adnroid加载数据转圈封装全屏转圈封装-程序员宅基地
文章浏览阅读1.5k次。我们经常会碰见 正在加载中,加载出错, “暂无商品”等一系列的相似的布局,因为我们有很多请求网络数据的页面,我们不可能每一个页面都写几个“正在加载中”等布局吧,这时候将这些状态的布局封装在一起就很有必要了。我们可以将这些封装为一个自定布局,然后每次操作该自定义类的方法就行了。 首先一般来说,从服务器拉去数据之前都是“正在加载”页面, 加载成功之后“正在加载”页面消失,展示数据;如果加载失败,就展示_adnroid加载数据转圈封装全屏转圈封装
阿里云服务器(Alibaba Cloud Linux 3)安装部署Mysql8-程序员宅基地
文章浏览阅读1.6k次,点赞23次,收藏29次。PS: 如果执行sudo grep 'temporary password' /var/log/mysqld.log 后没有报错,也没有任何结果显示,说明默认密码为空,可以直接进行下一步(后面设置密码时直接填写新密码就行)。3.(可选)当操作系统为Alibaba Cloud Linux 3时,执行如下命令,安装MySQL所需的库文件。下面示例中,将创建新的MySQL账号,用于远程访问MySQL。2.依次运行以下命令,创建远程登录MySQL的账号,并允许远程主机使用该账号访问MySQL。_alibaba cloud linux 3
excel离散度图表怎么算_excel离散数据表格-Excel 离散程度分析图表如何做-程序员宅基地
文章浏览阅读7.8k次。EXCEL中数据如何做离散性分析纠错。离散不是均值抄AVEDEV……=AVEDEV(A1:A100)算出来的是A1:A100的平均数。离散是指各项目间指标袭的离散均值(各数值的波动情况),数值较低表明项目间各指标波动幅百度小,数值高表明波动幅度较大。可以用excel中的离散公式为STDEV.P(即各指标平均离散)算出最终度离散度。excel表格函数求一组离散型数据,例如,几组C25的...用exc..._excel数据分析离散
学生时期学习资源同步-JavaSE理论知识-程序员宅基地
文章浏览阅读406次,点赞7次,收藏8次。i < 5){ //第3行。int count;System.out.println ("危险!System.out.println(”真”);System.out.println(”假”);System.out.print(“姓名:”);System.out.println("无匹配");System.out.println ("安全");
linux 性能测试磁盘状态监测:iostat监控学习,包含/proc/diskstats、/proc/stat简单了解-程序员宅基地
文章浏览阅读3.6k次。背景测试到性能、压力时,经常需要查看磁盘、网络、内存、cpu的性能值这里简单介绍下各个指标的含义一般磁盘比较关注的就是磁盘的iops,读写速度以及%util(看磁盘是否忙碌)CPU一般比较关注,idle 空闲,有时候也查看wait (如果wait特别大往往是io这边已经达到了瓶颈)iostatiostat uses the files below to create ..._/proc/diskstat
glReadPixels读取保存图片全黑_glreadpixels 全黑-程序员宅基地
文章浏览阅读2.4k次。问题:在Android上使用 glReadPixel 读取当前渲染数据,在若干机型(华为P9以及魅族某魅蓝手机)上读取数据失败,glGetError()没有抓到错误,但是获取到的数据有误,如果将获取到的数据保存成为图片,得到的图片为黑色。解决方法:glReadPixels实际上是从缓冲区中读取数据,如果使用了双缓冲区,则默认是从正在显示的缓冲(即前缓冲)中读取,而绘制工作是默认绘制到后缓..._glreadpixels 全黑