Pytorch多GPU训练:DataParallel和DistributedDataParallel
”DataParallel“ 的搜索结果
使用DataParallel和DistributedDataParallel的两种多GPU分布式训练方法包含加载单GPU和多GPU保存的预训练模型权重的迁移学习
这里为你收集整理了关于AI,机器学习,深度学习相关的资料一份,质量非常高,如果你投入时间去研究几天相信肯定对你有很大的帮助。到时候你会回来感谢我的。 本资源是经过本地编译测试、可打开、可运行的文件或源码...
PyTorch是一个流行的深度学习框架,提供了DataParallel和DistributedDataParallel两种多GPU训练方法。在本文中,我们将深入探讨这两种方法的核心概念、算法原理和实际应用场景,并提供一些最佳实践和代码示例。 1. ...
在之前的一篇博客中提到了Pytorch框架下,模型使用GPU多卡并行运算来解决显存不足的问题,即使用:但运行后意料之外地出现了如下的error:你也许会很纳闷,明new_model与model已经设置为相同结构了,为什么会报出...
前言 pytorch中的GPU操作默认是异步的,当调用一个使用GPU的函数时,这些操作会在特定设备上排队但不一定在稍后执行。这就使得pytorch可以进行并行计算。但是pytorch异步计算的效果...net = torch.nn.DataParallel(net,
We employ data parallelism paradigm that is suitable for handling large-scale processing on multi-core computers to achieve a high degree of parallelism. Using the data parallelism paradigm, we ...
1.DataParallel DataParallel更易于使用(只需简单包装单GPU模型)。然而,由于它使用一个进程来计算模型权重,然后在每个批处理期间将分发到每个GPU,因此通信很快成为一个瓶颈,GPU利用率通常很低。 nn.Data...
torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0) 当给定model时,主要实现功能是将input数据依据batch的这个维度,将数据划分到指定的设备上。其他的对象(objects)复制到每个设备...
nn.DataParallel 如果默认不是序号0的话需要添加 os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID" os.environ["CUDA_VISIBLE_DEVICES"] = "2, 3" device_ids = [0, 1] model = torch.nn.DataParallel(net, device...
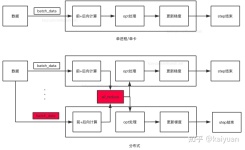
参考博客: https://blog.csdn.net/baidu_35120637/article/details/110785801 ...在多卡的GPU服务器,当我们在上面跑程序的时候,当迭代次数或者epoch足够大的时候,我们通常会使用nn.DataParallel
PyTorch官网的手册:torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0) 2. 使用方法 具体使用也比较简单,如下所示,其余的不需要变化 # 当不限制GPUs的个数时,默认使用全部的GPU
PyTorch 使用DataParallel()实现多GPU训练

【代码】torch.nn.DataParallel使用细节。
平衡数据并行这里是改进了pytorch的DataParallel,使用了平衡第一个GPU的显存使用量本代码来自transformer-XL: : 代码不是本人写的,但是感觉很好用,就分享一下。怎么使用:这个BalancedDataParallel类使用起来和...

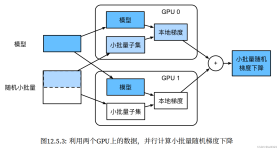
使用多GPU对神经网络进行训练时,pytorch有相应的api将模型放到多GPU上运行。 torch.nn.parallel.DistributedDataParallel(model, device_...torch.nn.DataParallel(model.cuda(), decice_ids=gpus, output_device=gpu

现在Pytorc下进行多卡训练主流的是采用torch.nn.parallel.DistributedDataParallel()(DDP)方法,但是在一些特殊的情况下这样的方法就使用不了了,特别是在进行与GAN相关的训练的时候,假如使用的损失函数是 WGAN-...
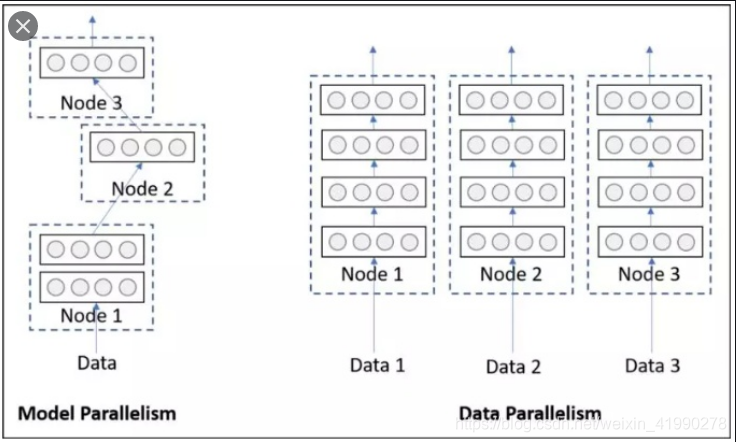
公司配备多卡的GPU服务器,当我们在上面跑程序的时候,当迭代次数或者epoch足够大的时候,我们通常会使用nn.DataParallel函数来用多个GPU来加速训练。一般我们会在代码中加入以下这句: device_ids = [0, 1] ...
公司配备多卡的GPU服务器,当我们在上面跑程序的时候,当迭代次数或者epoch足够大的时候,我们通常会使用nn.DataParallel函数来用多个GPU来加速训练。一般我们会在代码中加入以下这句: device_ids = [0, 1] ...

本文源自 ...在本教程中,我们将学习如何使用多个GPU: DataParallel 的用法. 与PyTorch一起使用GPU非常容易。您可以将模型放在GPU上: device = torch.device("cuda:0") model...
最近工作涉及到修改分布式训练代码,以前半懂非懂,...torch.nn.DataParallel ==> 简称 DP torch.nn.parallel.DistributedDataParallel ==> 简称DDP 其中 DP 只用于单机多卡,DDP 可以用于单机多卡也可用于多...
模型用DataParallel包装一下: device_ids = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # 10卡机 model = torch.nn.DataParallel(model, device_ids=device_ids) # 指定要用到的设备 model = model.cuda(device=device_ids[0...
推荐文章
- html5如何设置div高度,jsp中设置div的高度为页面高度.怎么设置/-程序员宅基地
- 基于Kubernetes的云上机器学习—GPU弹性扩缩容-程序员宅基地
- 杭州程序员对薪酬最满意,上海程序员最辛苦...原来我们是这样的程序员_杭州软件比上海-程序员宅基地
- Unity Shader - 在 URP 获取 Ambient(环境光) 颜色_unity ambient-程序员宅基地
- TCPIP详解卷1第3章IP网际协议3.2IP首部3.3IP路由选择-程序员宅基地
- linux which,whereis,locate,find的区别_linux中whereis locate which的区别-程序员宅基地
- olat中解决查看gui_demo源代码异常或debug模式下查看源代码异常_guidemo_main不显示-程序员宅基地
- 自定义View-Rect和RectF_android根据rect坐标添加控件-程序员宅基地
- CCS5导入工程时出错:Issues that may require your attention were encountered while importing the projects-程序员宅基地
- Android4.0 Toast显示问题分析_安卓4.0不支持uni.showtoast-程序员宅基地