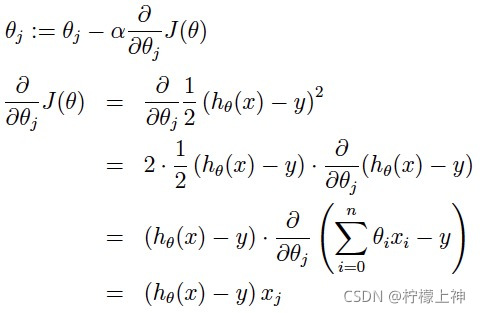
”SGD“ 的搜索结果
在深度学习中,优化器是一个非常重要的组成部分,它通过调整模型参数的方式来最小化损失函数。本教程将介绍三种常用的优化器以及如何选择最合适的优化器。
SGD.zip_SGD
标签: sgd
executable program for scanning graph data value

很多情况下,我们调用优化器的时候都不清楚里面的原理和构造,主要基于自己数据集和模型的特点,然后再根据别人的经验来选择或者尝试优化器。下面分别对SGD的原理、pytorch代码进行介绍和解析。
1.背景介绍 深度学习是当今人工智能领域最热门的研究方向之一,它主要通过多层神经网络来学习数据中的复杂关系。随着数据规模的增加,深度学习模型的复杂性也不断增加,这导致了训练模型的计算成本也不断增加。...
从Adam切换到SGD 表明:“即使在自适应解决方案具有更好的训练性能的情况下,通过自适应方法发现的解决方案的普遍性也比SGD差(通常显着更差)。这些结果表明,从业者应该重新考虑使用自适应方法来训练神经网络。 ...
【深度学习中常见的优化器总结】SGD+Adagrad+RMSprop+Adam优化算法总结及代码实现
BGD vs SGDBGD vs SGD名词解释功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一...
常规的随机梯度下降公式如下:其中是学习率,是损失关于参数的梯度(有的资料中会写成等形式),不过相SGD,的更多的还是批量梯度下降(mBGD)算法,不
linear_regression_SGD:从头开始实施SGD以进行线性回归
该版本允许通过以下接口使用任意目标函数(类似于Schmidt的minFunc):sgd(funObj,funPrediction,x0,train,valid,options,varargin) 我提供了源代码以及示例(softmax目标函数)。 gd_matlab是一种类似于SGD...
可打印版本附pdf下载链接本思想来下这篇佬的章:Juliuszh:个框架看懂优化算法之异同 SGD/AdaGrad/Adam主要是对深度学习各种优化器 (从SG
安川伺服Σ-7S 伺服单元 模拟量电压、脉冲序列指令形 Σ-7系列 AC伺服驱动器 产品手册 电机驱动器手册
SGD随机梯度下降Matlab代码
主要介绍了Keras SGD 随机梯度下降优化器参数设置方式,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
SGD7S_120A00A驱动器说明书手册范本.doc
逻辑回归matlab代码VR-SGD VR-SGD演示(与一些主要算法比较)。 方法“ VR-SGD”在论文中进行了描述:“ VR-SGD:一种用于机器学习的简单随机方差降低基准”,尚凡华,IEEE会员,周开文,James Cheng,曾钰成,曾...
SGD网站项目 该项目是用于SGD Nextgen重新设计的前端Web应用程序。 它从SGDBackend检索JSON格式的数据,然后创建网站的页面。 构建应用 前提条件,node.js> 4.2.0和python 2.7.x. o管理python依赖关系,为此项目...
SGD和有区别的私人SGD computeCost.m-根据一组观察值计算成本值computeGradient.m-基于单个观测值计算梯度laplace.m-为差分私有SGD生成拉普拉斯噪声矢量SGD.m-标准随机梯度下降的代码DPSGD.m-差分
引入了新的变量来充当“惯性”或者“速度”的角色。使用momentum的SGD算法更新时使用上一步的动量减去当前的梯度(即加上负梯度)。动量 被定义为之前所有梯度
torch.optim的灵活使用详解 ...optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum=0.9) 2. 灵活的设置各层的学习率 将model中需要进行BP的层的参数送到torch.optim中,这些层不一定是连续的。
# SGD和Adam优化器在卷积神经网络上的结果对比实验 文档+代码整理 1. 使用ResNet18进行实验,研究了batch size、学习率和权重初始化对图像分类任务的影响; 2. 针对LeNet、AlexNet、ResNet18三种卷积神经网络,比较...
斑马打印机ZPL脚本使用说明
新币 注意 这个包是无人维护的。 不保证其可靠性。 介绍 Julia的新元
一方面,同步版本包括一个主节点,该主节点可确保在工作节点之间协调梯度的计算和SGD的更新步骤。 另一方面,在异步版本中,工作节点自己执行计算,并经常相互交换权重更新。 主机仅管理完整算法的开始和结束(例如...

这是SGD算法的并行在全球第一次被提出时的论文,为后面并行算法的发展提供了很多基础铺垫。
Spark 上用于矩阵分解的分布式 SGD AWS 设置 在主人上: ./start-master.sh 关于奴隶: ./start-slave.sh org.apache.spark.deploy.worker.Worker spark://ip-172-31-44-204.ec2.internal:7077 用法 实验一: ....
Parallel SGD Parallel-SGD v0.7 本项目为分布式并行计算框架&简易CPU神经网络模型库。可用于联邦学习和分布式学习中的关于网络架构和通信编码部分的实验,参考ICommunication_Ctrl接口说明( );可用于神经...
推荐文章
- Windows系统鼠标右键菜单添加打开cmd终端_we右键进入cmd-程序员宅基地
- python汇编语言还是机器语言_深入理解计算机系统(3.1)------汇编语言和机器语言...-程序员宅基地
- android毕设各种app项目,安卓毕设,android毕设_app毕业设计-程序员宅基地
- Keil侧边工具栏(项目窗口)打开方式_keil侧边栏-程序员宅基地
- 算法学习,转载记录(持续记录)-程序员宅基地
- 局域网探测器_局域网检测-程序员宅基地
- 【C语言基础系列,阿里java面试流程_c语言java面试-程序员宅基地
- Linux技术简历项目经验示例(二)_linux简历工作经验怎么写-程序员宅基地
- 安卓手机软键盘弹出后不响应onKeyDown、onBackPressed方法解决方案-程序员宅基地
- 使用二维数组实现存储学生成绩_c#创建控制台应用程序studentscore,生成学生成绩单——二维数组的使用。-程序员宅基地