”Spark“ 的搜索结果
执行spark-shell报错 [root@hadoop101 conf]# spark-shell 2.报错 Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 2020-...
spark数据处理sparkinmemoryclustercomputingforiterativeandinteractiveapplications共43页.pdf.zip
配置基于Zookeeper的一个ha是非常简单的,只需要在spark-env.sh中添加一句话即可。添加上如下内容:配置的时候保证下面语句在一行,否则配置不成功,每个-D参数使用空格分开。master挂掉,便无法对外提供新的服务,...
SparkCore写入ClickHouse,可以直接采用写入方式。下面案例是使用SparkSQL将结果存入ClickHouse对应的表中。

Spark框架包含多个紧密集成的组件,包括Spark SQL(即席查询)、Spark Streaming(实时流处理)、Spark MLlib(机器学习库)、Spark GraphX(图计算)。3、spark更加通用,spark提供了多个功能API,另外还有流式处理...
2、zookeeper安装成功3、hadoop2.6.0 HA安装成功4、Scala安装成功(不安装进程也可以启动)
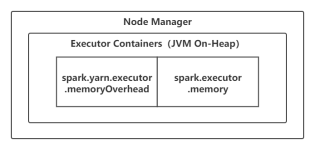
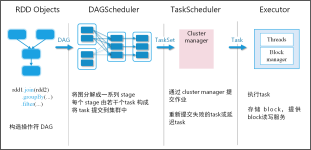
1)粗粒度:启动时就分配好资源, 程序启动,后续具体使用就使用分配好的资源,不需要再分配资源;优点:作业特别多时,资源复用率高,适合粗粒度;缺点:容易资源浪费,假如一个job有1000个task,完成了999个,还有...
通过正确配置HA、 测试故障转移、监控集群健康状况和确保数据一致性,您可以提高系统的可用性和稳定性。在大数据 领域,HA环境不仅仅是一种最佳实践,而且是确保数据分析任务能够持。

笔记实验六,spark,大数据分析
【代码】使用Spark操作Hudi表详细教程_spark读取hudi。
Spark SQL 可以通过 JDBC 从关系型数据库中读取数据的方式创建 DataFrame,通过对DataFrame 一系列的计算后,还可以将数据再写回关系型数据库中。如果使用 spark-shell 操作,可在启动 shell 时指定相关的数据库驱动...

知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到...
cogroup:对多个(2~4)RDD 中的 KV 元素,每个 RDD 中相同 key 中的元素分别聚合成一个集合。与 reduceByKey 不同的是:reduceByKey 针对一个 RDD 中相同的 key 进行合并。而cogroup 针对多个 RDD 中相同的 key 的...

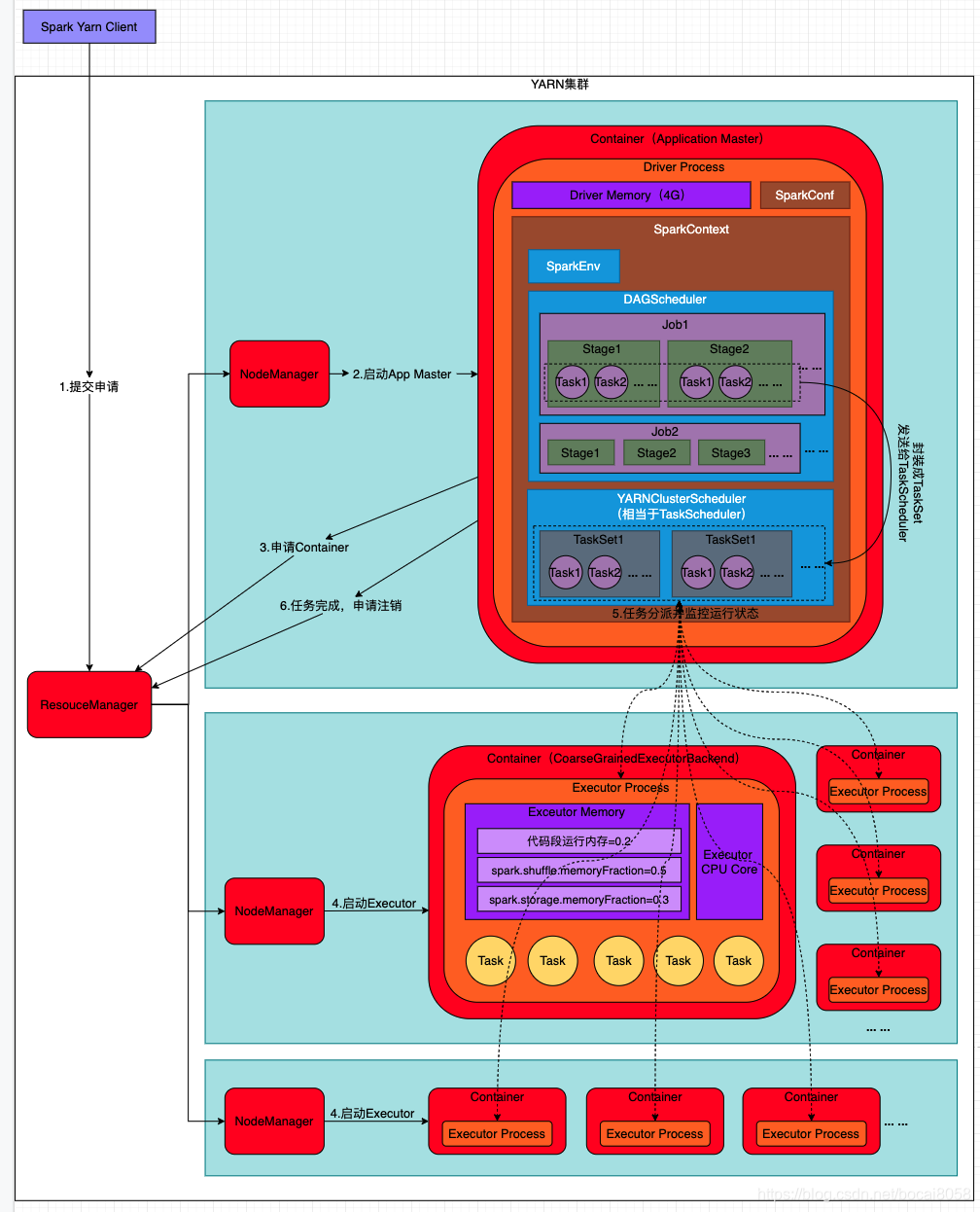
Spark使用不同的数据源,Spark SQL开发,性能调优



该文介绍了Spark的五种作业提交方式
2.关闭spark 进入以下目录:/usr/local/softwares/spark-2.3.2-bin-hadoop2.7/sbin 执行以下命令,关闭spark: ./stop-all.sh 3.关闭hadoop 进入以下目录:/usr/local/softwares/hadoop-2.7.2/sbin 执行以下...
基于Spark的电影推荐系统 本次项目是基于大数据过滤引擎的电影推荐系统--“懂你”电影网站,包含了爬虫、电影网站(前端和后端)、后台管理系统以及推荐系统(Spark)。 一、爬虫 开发环境:pycharm + python...

推荐文章
- SAP SMARTFORMS打印设置默认LP01格式打印_sap lp01-程序员宅基地
- Kubernetes Service与Ingress详解_ingresses service-程序员宅基地
- 高效Web开发的10个jQuery代码片段-程序员宅基地
- 公司感染勒索病毒怎么办 怎样及时补救?-程序员宅基地
- Nginx 开启 IPv6 Nginx 开启 IPv6 SSL_nginx 支持ipv6版本-程序员宅基地
- 空间关系_空间数据库touch,inside关系-程序员宅基地
- Vmware虚拟机安装Ubuntu 18.04.2 LTS(长期支持)版本+VMware tools安装总结_虚拟机怎么打开usr文件夹-程序员宅基地
- Ardunio开发ESP8266 中断问题_arduino esp8266 定时器中断-程序员宅基地
- css -- ie兼容写法_css ie兼容写法-程序员宅基地
- 蓝桥杯 2014 B组_蓝桥c语言字符串进位-程序员宅基地