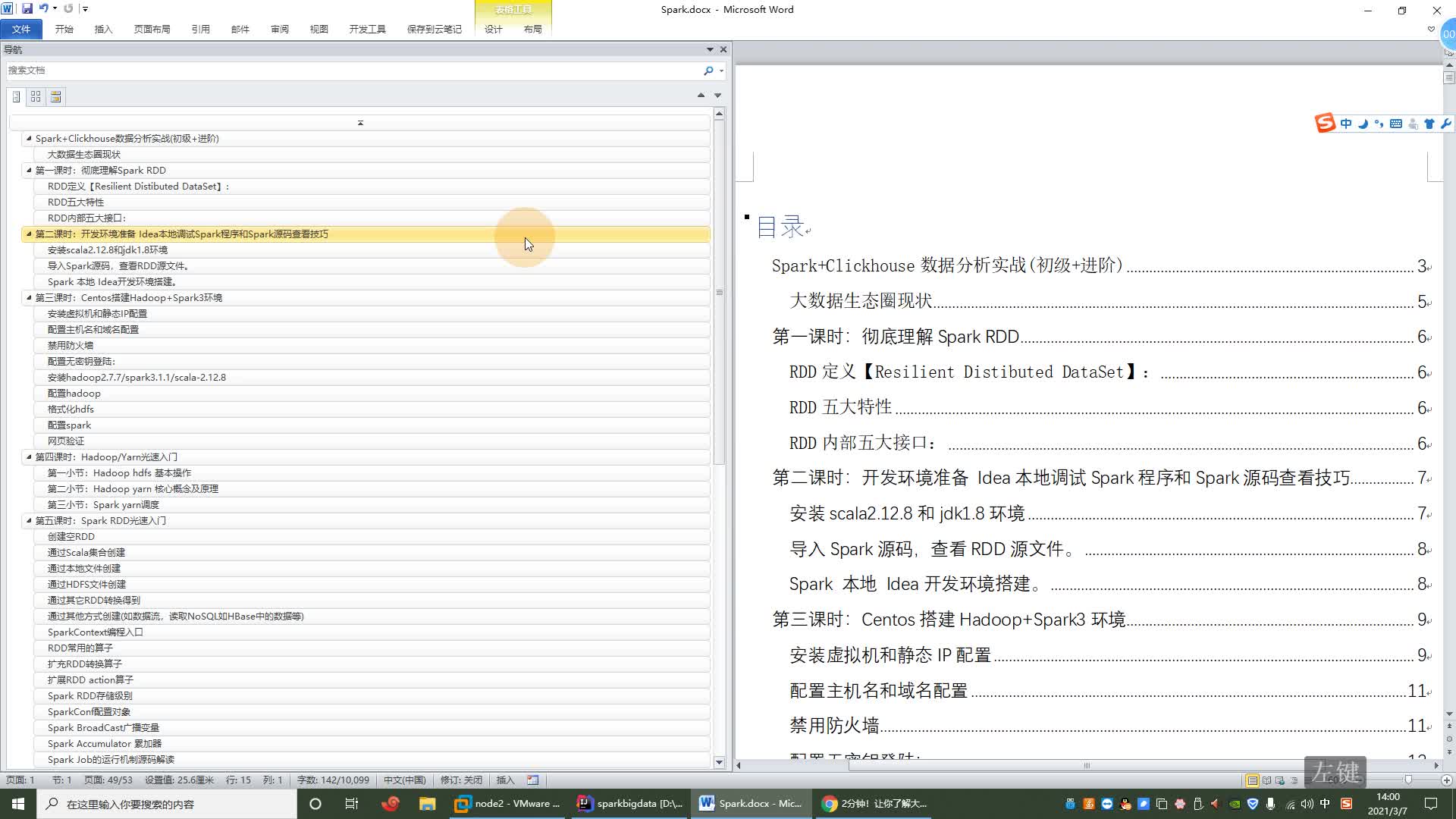
”Spark“ 的搜索结果
Hadoop 是一个提供分布式存储和计算的。
而我们之前采用的PostgreSQL驱动的方式就是因为使用了JDBC,导致写入速度非常慢。综合官网提供的这3中方式,我们最终选择了Greenplum-Spark Connector这种方式,但是只提供了Spark2.3版本支持,其他版本未验证过。。

Hadoop 是一个提供分布式存储和计算的。
【代码】Spark运行流程及架构设计。
本文主要介绍了spark的执行计划explain的使用方法,以及对逻辑执行计划和物理执行计划进行了说明,让大家更加了解spark的运行原理。
文章总结:Spark Streaming是Spark的实时流计算API,将连续的流数据按时间间隔划分为数据块,每个块是一个RDD,具备RDD的优点,如快速处理和数据容错性。然而,实时延迟较高,不支持小批处理时间间隔。Spark ...
在 DAG 中又进行 Stage 的划分,划分的依据...Spark 的 Job 来源于用户执行 action 操作(这是 Spark 中实际意义的 Job),就是从 RDD 中获取结果的操作,而不是将一个 RDD 转换成另一个 RDD 的 transformation 操作。
1)输入:在Spark程序运行中,数据从外部数据空间(如分布式存储:textFile读取HDFS等,parallelize方法输入Scala集合或数据)输入Spark,数据进入Spark运行时数据空间,转化为Spark中的数据块,通过BlockManager进行...
spark on hive : hive只作为存储角色,spark 负责sql解析优化,底层运行的还是sparkRDD 具体可以理解为spark通过sparkSQL使用hive语句操作hive表,底层运行的还是sparkRDD, 步骤如下: 1.通过sparkSQL,加载...

易于使用:Spark的版本已经更新到了Spark3.1.2(截止日期2021.06.01),支持了包括Java、、Python、R和SQL语言在内的多种语言。为了兼容Spark2.x企业级应用场景,Spark仍然持续更新Spark2版本。通用性强:在Spark的...
(2)复制spark-env.sh.template并重命名为spark-env.sh,并在文件最后添加配置内容。(3)复制slaves.template成slaves (配置worker节点)讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**4、Scala安装...

通过数据平台上的DataX把Hive表数据同步至Greenplum(因为DataX原生不支持Greenplum Writer,只能采用PostgreSQL驱动的方式),但是同步速度太慢了,
卸载相关服务,键入命令rpm -e --nodeps删除的包 将安装包解压到/usr/local/src目录下,将安装包放在root目录下 ...在文件最后增加两行export JAVA_HOME=/usr/local/src/jdk1.8.0_152export PATH=$PATH:$JAVA_...
:quit
Spark独立集群管理器,一种简单的Spark集群管理器,很容易建立集群,基于Spark自己的Master-Worker集群 Apache Mesos,一种能够运行Haoop MapReduce和服务应用的集群管理器 Hadoop YARN,Spark可以和...
当以分布式集群部署的时候,可以根据自己集群的实际情况选择Standalone模式(Spark自带的模式)、Spark on YARN模式或者Spark on mesos模式。Spark的各种运行模式虽然在启动方式、运行位置、调度策略上各有不同,但...
Spark Installation with Maven & Eclipse IDE 文章目录Spark Installation with Maven & Eclipse IDE安装说明Maven & Eclipse IDE说明参考网站安装过程JDK安装Eclipse IDE安装Maven安装Spark安装新建...
spark为什么快
Table or view not found: aaa.bbb The column number of the existing table dmall_search.query_embedding_data_1(struct<>) doesn’t match the data schema(struct<user_id:string,dt:string,sku_list:...


推荐文章
- EVO-CNN-LSTM-multihead-Attention能量谷算法优化模型结合多头注意力机制多维时序预测-程序员宅基地
- Objective-C 中的id到底是什么-程序员宅基地
- 好记性不如烂笔头---Archlinux优化简介-程序员宅基地
- 3DREM16P-7X/250YG24-8K4V比例减压阀放大器-程序员宅基地
- python文件操作(open()、write()、writelines()、read()、readline()、readlines()、seek()、os)_python open writeline-程序员宅基地
- 分布式限流实战--redis实现令牌桶限流_分布式令牌限流-程序员宅基地
- 【Linux】文件系统-程序员宅基地
- python实现ks算法_python, 在信用评级中,计算KS statistic值-程序员宅基地
- 类加载过程 与 代码的执行顺序_类加载后代码的执行顺序-程序员宅基地
- Oracle LiveLabs实验:Introduction to Oracle Spatial Studio_oracle_spatial 可视化-程序员宅基地