
”WordCount“ 的搜索结果
批处理 import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.ExecutionEnvironment; import org.apache.flink.api.java.operators.AggregateOperator; import org.apache.flink....
说在前面 一直又想写博客的想法,而自己又太懒,感觉也写不出来什么。...1、首先要认识到:hadoop的输入输出都是在hdfs文件系统上的,而hdp自带的wordcount例子需要有输入文件,所以需要先上传输入文件到


用一个并行计算任务显然是无法同时完成单词词频统计和排序的,这时我们可以利用 Hadoop 的任务管道能力,用上一个任务(词频统计)的输出做为下一个任务(排序)的输入,顺序执行两个并行计算任务。...
1、单线程实现WordCount package cn.kgc.kb11.wc; import java.io.BufferedReader; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.util.Iterator; ...
hadoop实现wordcount
Hadoop自带了个单词计数的MapReduce程序WordCount,下面用三种方法运行该程序 在开始前先在hdfs上面创建输入和输出路径: 1、使用hdfs dfs -mkdir /input命令创建一个input文件夹 2、使用hdfs dfs -put /home/...

在笔记本虚拟机上部署Hadoop集群后运行Wordcount程序报错Connection refused
目录快速开始Maven 快速入门流处理wordcount流处理wordcount2批处理 快速开始 Maven 快速入门 创建项目 唯一的要求是安装Maven 3.0.4(或更高版本)和Java 8.x。 使用以下命令之一创建项目: $ mvn archetype:...

wordcount-mapreduce Hadoop MapReduce WordCount 示例应用程序
基于C#Winform的一个简单的单词及时间统计程序


hadoop入门级的代码 Java编写 eclipse可运行 包含 hdfs的文件操作 rpc远程调用的简单示例 map-reduce的几个例子:wordcount 学生平均成绩 手机流量统计
var wordCount = require ( '@ycjcl868/wordcount' ) ; wordCount ( 'count words.' ) ; //=> 2 wordCount ( 'count words, again.' ) ; //=> 3 wordCount ( '<p>should 你好 html</p><br><p>hello</p>' ) //=> 4 ...

Mapreduce实现Wordcount一、程序实现1.1 mapper类:1.2 reducer类:1.3 main类:二、操作实例2.1 打包2.2 数据操作 一、程序实现 1.1 mapper类: // Mapper的四个参数:第一个Object表示输入key的类型;第二个Text...
在/usr/local目录中新建wordCount文件夹mkdir /wordCountecho "hello hadoop">./input/file1写入数据2。Hadoop 的 classhpath 信息添加到 CLASSPATH 变量中,在 ~/.bashrc 中增加:vi ~/.bashrc...

本资源使用的是python语言来编写,利用Python的multiprocessing,多线程并行计算处理单词统计,代码里面有注释,该资源有单词统计的代码,单词统计文本,包括程序运行的单词统计结果,使用最基本结构来实现,还有很...

因为Hadoop要求输出文件夹不能存在,所以这只是空文件夹,在执行时再确定输出文件夹,如/wcoutput/output1。执行wordcount程序(词频统计)
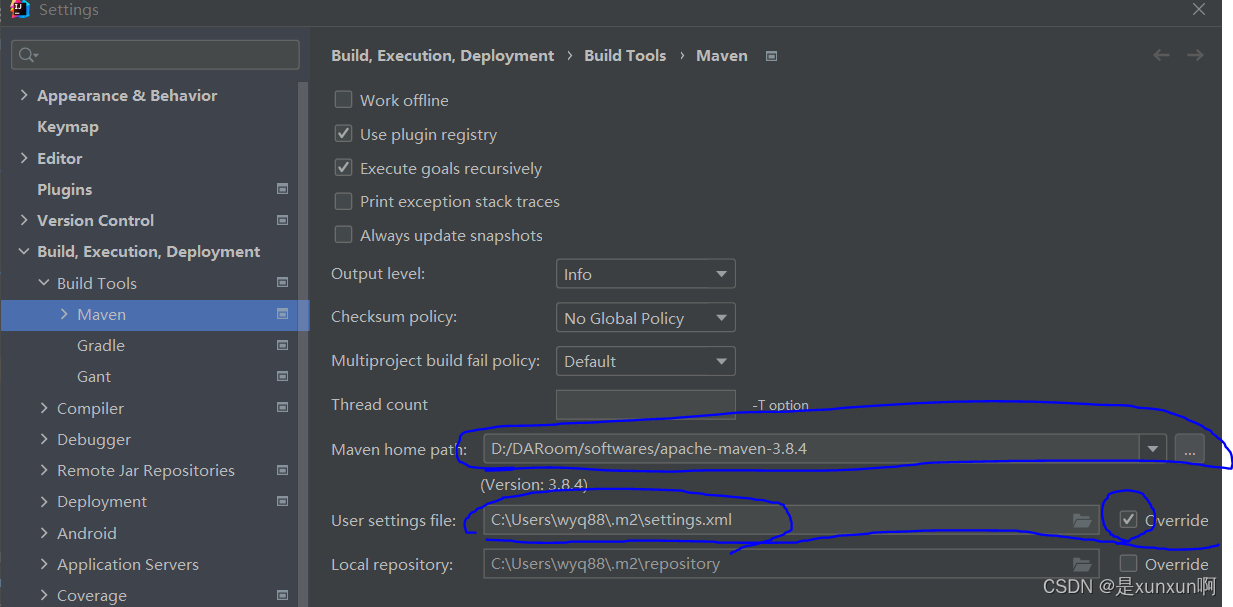
一、idea环境配置 要使用MapReduce来进行单词计数,需要导入需要的jar包,所以我们这里使用Maven来建工程,可以通过配置文件参数来自动引入所需要的jar包,下面是配置文件poem.xml的参数: <...
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供了计算...1、Hadoop示例程序WordCount详解及实例2、hadoop学习笔记:mapreduce框架详解3、hadoop示例程序wo
MapReduce经典案例wordCount的设计思想 Mapper阶段 1.我们将MapTask传给我们的文本内容先转换成一行字符串 2.根据空格对这一行进行分割,从而形成多个单词 3.通过for循环我们将得到一系列<单词,1>这样形式的...
推荐文章
- 大数据和云计算哪个更简单,易学,前景比较好?_大数据和云计算哪个好-程序员宅基地
- python操作剪贴板错误提示:pywintypes.error: (1418, 'GetClipboardData',线程没有打开的剪贴板)...-程序员宅基地
- IOS知识点大集合_ios /xmlib.framework/headers/xmmanager.h:66:32: ex-程序员宅基地
- Android Studio —— 界面切换_android studio 左右滑动切换页面-程序员宅基地
- 数据结构(3):java使用数组模拟堆栈-程序员宅基地
- Understand_6.5.1175::New Project Wizard_understand 6.5.1176-程序员宅基地
- 从零开始带你成为MySQL实战优化高手学习笔记(二) Innodb中Buffer Pool的相关知识_mysql_global_status_innodb_buffer_pool_reads-程序员宅基地
- 美化上传文件框(上传图片框)_文件上传框很丑-程序员宅基地
- js简单表格操作_"var str = '<table border=\"5px\"><tr><td>序号</td><-程序员宅基地
- Power BI销售数据分析_powerbi汇总销售人员业绩包括无销售记录的人-程序员宅基地