很多小伙伴在搭建完hadoop集群后,还不太会在上面跑测试程序,作为大数据入门学习的Hello world程序,我总结了三种方法。 第一种:用hadoop上自带的jar包(hadoop-mapreduce-examples-2.7.0.jar)实现 第二种:不用...
”hadoopwordcount“ 的搜索结果
hadoop wordcount2.0 包含省略标点,忽略大小写等内容
1、MapReduce理论简介 1.1 MapReduce编程模型 MapReduce采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主... 在Hadoop中,用于执行MapReduce任务的机器角色有两个:一个是JobTrack...
wordcount
大致流程如下: 第一步:开发Map阶段代码 第二步:开发Reduce阶段代码 第三步:组装Job 在idea中创建WordCountJob类 添加注释,梳理一下需求: 需求:读取hdfs上的hello.txt文件,计算文件中每个单词出现的总...
2、Ubuntu 12.10 +Hadoop 1.2.1版本集群配置:...安装完hadoop后,运行hadoop自带的程序wordcount时,出现卡住的问题,等再长的时间也无法计算完。在网上查找资料后得到,这一般是因为网络没有设置好引起的。...
使用hadoop实现WordCount详细实验报告,配有环境变量配置截图以及实验运行及结果详细过程描述与截图
mapreduce hadoop中的分布式运算编程框架,只要按照其编程规范,只需要编写少量的业务逻辑代码即可实现一个强大的海量数据并发处理程序 Demo开发——wordcount 1、需求 从大量(比如T级别)文本文件中,统计出每...
hadoop wordcount 打包部署
面向有wordcount输出结果的,经过默认排序的 由于wordcount自带的是按照字母表顺序排序的,所以我们第一步就是要把自带排序给替换成按照value降序排序的 @DecreasingComparator.java public class ...

Maven在Eclipse中远程调试hadoop2.6.0项目 1.系统环境 调试:Win7,64bit Cluster: Linux, Centos 2.创建hadoop项目命令 mvn archetype:generate -DarchetypeGroupId=org.apache.maven.archetypes -DgroupId=org....
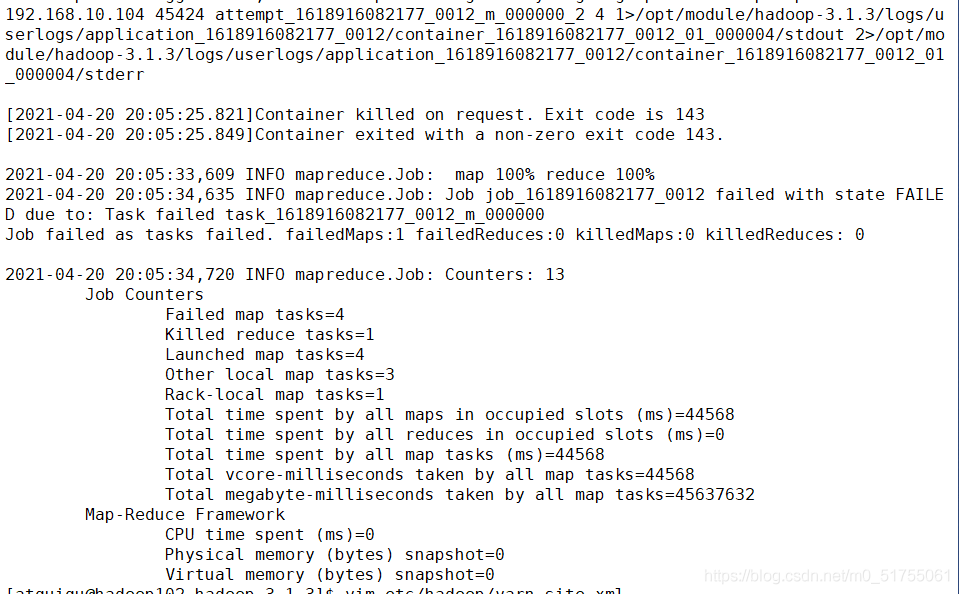
运行wordcount案例的时候总是卡住,查了一圈,有说把mapred-site.xml中 <name>mapreduce.framework.name</name> <value>yarn</value> 这一条删除的,但是删除了相当于仅仅在本机上运行,...
WordCount.java: import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io....
1、在本地解压hadoop安装包,然后修改系统变量,增加HADOOP_HOME及HADOOP_USER_NAME,HADOOP_USER_NAME为实际集群运行用户 2、修改项目的Pom文件 org.apache.hadoop hadoop-common 2.9.0
采用64位Oracle Linux 6.4, JDK:1.8.0_131 64位, Hadoop:2.7.3 Spark集群实验环境共包含3台服务器,每台机器的主要参数如表所示: 服务器 HOSTNAME IP 功能 spark1 spark1 92.16.17.1 NN/DN/RM Master/...
闲来无事,想看看小说中的什么字出现的频率比较高,就改了一下WordCount的程序。 原理: 主要的核心就是WordCount,那就先说下WordCount。 WordCount: Map: 对每一行的输入,扫描到一个单词就将key设置为...
3.hadoop jar wordcount.jar com.hadoop.mr.WordCount hdfs dfs -ls /data/output hdfs dfs -cat /data/output/part-r-00000 也可以把内容copy到当前的目录 hdfs dfs -get /data/output/* ./ package ...
下载Hadoop WordCount可以通过以下步骤完成: 1. 打开Hadoop官方网站(https://hadoop.apache.org/)。 2. 导航至Hadoop的下载页面。 3. 在下载页面上,选择适合您操作系统的稳定版本。 4. 点击下载按钮,开始下载...
需求:读取hdfs上的hell.txt文件,计算文件中每个单词出现的总次数。* 第一个LongWritable K1代表每行行首的偏移量。// k1代表的是每一行的行首偏移量,v1代表的是每一行内容。* 这个map函数就是可以接收k1,v1, ...
java程序如下 import java.io.IOException; import java.util....import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import ...
马克-to-win @ 马克java社区:下载hadoop-2.7.4-src.tar.gz,拷贝hadoop-2.7.4-src.tar.gz中hadoop-mapreduce-project\hadoop-mapreduce-examples\src\main\java\org\apache\hadoop\examples下的WordCount.java文件...
作为Hadoop的入门程序,我相信大家对wordCount一定不陌生。但是对于刚刚接触Hadoop的人来说,可能很难理解程序运行过程中具体流程是怎么样的。这篇博客我讲讲我对其流程的理解,有错误的地方尽情拍砖。...
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; imp....

通过hadoop 来进行感情分析,代码可以实现将几个GB大小的数据,来统计词的数量
1、首先搭建hadoop环境:...2、使用hadoop自带的jar包测试wordcount,cd到包目录: /usr/local/Cellar/hadoop/2.8.2/libexec/share/hadoop/mapreduce 3、执行命令 hadoop jar ./hadoop-...
hadoop3.x访问:http://localhost:9870 选择浏览 打开output文件夹: 下载该文件即可
推荐文章
- rotation matrix &reflection matrix-程序员宅基地
- [Layui]JS实现Layui树形表格treetable演示下载_layuiadmin下载 treetable-程序员宅基地
- 【Liunx笔记】Linux常用命令,值得收藏_常用linux命令笔记-程序员宅基地
- 微服务项目之电商--3.eureka集群搭建及eureka客户端详述及负载均衡Ribbon的使用和底层源码分析_高可用eureka集群+ribbon负载均衡-程序员宅基地
- Java字符串常量池-程序员宅基地
- Android 图片转动_android 图片转圈-程序员宅基地
- c语言.jpg图片转成数组_电脑使用图片转换器打开heic图片方法-程序员宅基地
- 2019年中国软杯-基于深度学习的银行卡号识别系统-程序员宅基地
- js清除HTML的input数据,js 清空 input file 的值的方法-程序员宅基地
- stm32H743 使用HAL库SPI读写外部flash失败原因_4线spi读不到flash-程序员宅基地