Hive正则表达式
”hive“ 的搜索结果
hive是Hadoop的客户端,启动hive前必须启动hadoop,同时hive的元数据存储在mysql中,是由于hive自带的derby数据库不支持多客户端访问。 2.开启metastore服务的参数 hive-site.xml中打开metastore的连接地址。 <!-...
解决方法:查看hadoop安装目录下 share/hadoop/common/lib 内 guava.jar 版本,查看 hive安装目录下lib内guava.jar的版本,如果两者不一致,删除版本低的,并拷贝高版本的。在表student_zqc中添加两个分区Dept=’CS...
基于上述原因,Hive在3.0.0版本中宣布移除了索引功能。这是一个经过深思熟虑的决定,目的是简化Hive的使用,避免用户对索引抱有不切实际的性能提升期望,并鼓励用户采用更适合大数据处理的数据组织方式。Hive在早期...

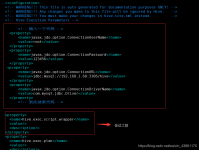
【代码】使用Hive时几个重要配置。
/ 数据清洗和处理(如筛选某一列、计算平均值等操作)// 通过Hive查询HBase数据。// 使用Java API查询数据。// 导入数据到HBase。// 创建Hive表。4. 清洗和处理数据。
一.Hive安装 1、下载安装包:apache-hive-3.1.1-bin.tar.gz 上传至linux系统/opt/software路径 2、解压软件 cd /opt/software tar -zxvf apache-hive-3.1.1-bin.tar.gz -C /opt/module/ 3、修改系统环境变量 vi /...

/ 数据清洗和处理(如筛选某一列、计算平均值等操作)// 通过Hive查询HBase数据。// 使用Java API查询数据。// 导入数据到HBase。// 创建Hive表。4. 清洗和处理数据。
今天我们复习了面试中常考的Hive相关的五个问题,你做到心中有数了么?其实做这个专栏我也有私心,就是希望借助每天写一篇面试题,督促自己学习,以免在吹水群甚至都没有谈资!对了,如果你的朋友也在准备面试,请将...
文章目录一、Hive 数据仓库的操作1、创建数据仓库2、查看 db 数据仓库的信息及路径3、删除 db 数据仓库二、Hive 数据表的操作1、创建内部表2、创建内部表3、修改表结构4、删除表5、创建同结构表三、Hive 中数据的...
1.SparkSQL 整合 Hive 导读 开启Hive的MetaStore独立进程 整合SparkSQL和Hive的MetaStore 和一个文件格式不同,Hive是一个外部的数据存储和查询引擎, 所以如果Spark要访问Hive的话, 就需要先整合Hive ...
本栏目大数据开发岗高频面试题主要出自大数据技术专栏的各个小专栏,由于个别笔记上传太早,排版杂乱,后面会进行原文美化、增加。
有30w条数据
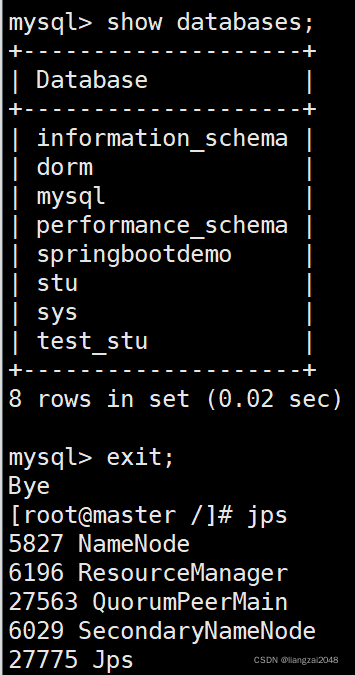
Apache Flink 从 1.9.0 版本开始增加了与 Hive 集成的功能,用户可以通过 Flink 来访问 Hive 的元数据,以及读写 Hive 中的表,Hive 是大数据领域最早出现的 SQL 引擎,发展至今有着丰富的功能和广泛的用户基础。...
面试前的“练手”还是很重要的,所以开始面试之前一定要准备好啊,不然也是耽搁面试官和自己的时间。我自己是刷了不少面试题的,所以在面试过程中才能够做到心中有数,基本上会清楚面试过程中会问到哪些知识点,高频...
使用 nohup 启动 beeline 并执行 SQL 脚本。# 定义需要执行的 SQL 脚本列表。# 循环执行每个 SQL 脚本。# 输出日志文件路径。
hive报错Error: Error while processing statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask (state=08S01,code=2)
jdbc连接Hive
标签: hive
jdbc连接Hive 1.使用sqoop将stu表导入到hive中 数据库表位于hadoop102上的test数据库 bin/sqoop import \ --connect jdbc:mysql://hadoop102:3306/test \ --username root \ --password 000000 \ --table stu ...
1,执行#hive命令进入Hive CLI时报如下错误: Exception in thread "main" java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata....
hive是facebook开源,并捐献给了apache组织,作为apache组织的顶级项目(hive.apache.org)。 hive是一个基于大数据技术的数据仓库(DataWareHouse)技术,主要是通过将用户书写的SQL语句翻译成MapReduce代码,然后发布...

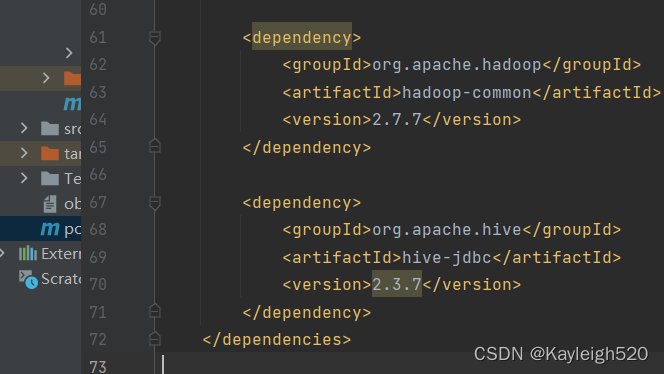
Hive的安装和配置-安装步骤: 1.配置Hadoop环境 2.安装MySQL数据库 3.配置MySQL相关 4.上传hive安装包,解压,重命名 5.设置环境变量 6.修改hive配置文件 7.上传MySQL连接驱动 8.初始化元数据 9.启动Hive 下面开始:...
1.1 Hive引擎简介 Hive引擎包括:默认MR、tez、spark Hive on Spark:Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。 Spark on Hive : Hive只作为存储元...
Hive与Hadoop的关系3. Hive中的命令3.1 创建数据库并指定hdfs存储位置3.2 修改数据库3.3 查看数据库信息3.4 创建表并指定字段之间的分隔符4. Hive中的四种表结构4.1 内部表4.2 外部表4.3 分区表4.4 分桶表 1. 概念 ...
推荐文章
- 探索Kinto FormBuilder:一款强大的在线表单构建器-程序员宅基地
- 关于地址引脚、数据引脚与片选-程序员宅基地
- 二级考试C语言基础知识精讲概述(三)-程序员宅基地
- [Latex]newcommand\renewcommand\newtheorem的使用、总结、报错_latex renewcommand-程序员宅基地
- 内存泄漏检测工具(转载)-程序员宅基地
- FPGA入门学习网站汇总【自学FPGA专用】_fpga学习课程推荐 csdn-程序员宅基地
- esp8266通过串口与stm32通信,实现远程控制pca9685_服务器下发指令通过sp8266控制stm32-程序员宅基地
- 记一次服务器(centos7)出现奇怪进程,占用CPU奇高的排查过程_centos7排查cpu历史高峰进程-程序员宅基地
- 付费短剧小程序源码 小剧场短剧影视小程序源码 带支付收益等 全开源优化版-程序员宅基地
- pack_padded_sequence和pad_packed_sequence&&rnn的输出_pack_padded_sequence后怎么用rnn训练-程序员宅基地