”hive“ 的搜索结果
在Hive中,删除部分数据是一个常见的操作,特别是当我们需要清除不再需要的数据或者进行数据更新时。Hive提供了多种方式来删除部分数据,本文将介绍其中几种常用的方法。

Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的...
Hive到0.13.0版本为止已经支持越来越多的数据类型,像传统数据库中的VCHAR、CHAR、DATE以及所特有的复合类型MAP、STRUCT等。Hive中的数据类型可以分为数值类型、字符串类型、日期时间类型、复合类型以及其它类型,...
Hive 远程连接配置
标签: hive
Hive 远程连接配置 1、配置 hive-site.xml 中的内容 打开 hive-site.xml 搜索 hive.server2.thrift.bind.host 如果存在则修改 value 值为 本机 域名或 ip <property> <name>hive.server2.thrift.bind....
文章目录01 引言02 Hive安装03 配置hive元数据库04 验证与运行hive4.1 运行前准备4.2 验证与运行 01 引言 hive本身是没有存储功能的,数据是存储在hadoop的hdfs里面。所以要安装并使用hive,需要现在装Hadoop,具体...
Hive on Spark配置
标签: hive

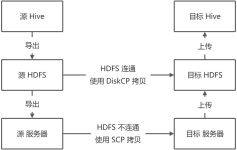
文章目录一、 什么是Hive二、 Hive的优缺点2.1 优点2.2 缺点三、 Hive架构原理3.1 用户接口:Client3.2 元数据:Metastore3.3 结合Hadoop3.4 驱动器:Driver四、 Hive和数据库比较4.1 查询语言4.2 数据更新4.3 执行...
Ubuntu20.04安装Hadoop和Hive一、安装Mysql二、安装Hadoop1.1创建Hadoop用户(如果需要将本机的账户与Hadoop分开,可以新建一个新用户)2.1安装SSH2.2安装JDK14.0.13.1下载Hadoop-3.2.13.2伪分布式配置3.3查看安装...

Flink 1.12.2 写入hdfs有3种方式,依照api出现的先后依次介绍,重点介绍Flink SQL on Hive的方式。 目录 1 streaming file sink 2 FileSink 3 Flink SQL on Hive 3.1添加依赖 3.2 配置Hive Catalog及使用Flink...
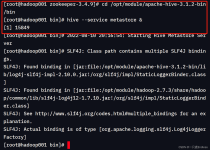
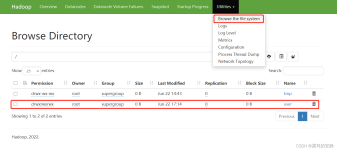
Spark on Hive & Hive on Spark你分清了吗
整理自 https://www.cnblogs.com/hark0623/p/5650075.html...下面这篇文章带你解密这些配置请跟随以下这些问题来看以下配置:1.hive输出格式的配置项是哪个?2.hive被各种语言调用如何配置?3.hive提交作业是在hiv...
文章目录Hive基本概念Hive的意义是什么Hive可以对数据进行存储与计算Hive的特性Hive缺点Hive的内部组成架构数据格式:Hive中没有定义专门的数据格式数据格式部分自定义:hive支持的数据格式Hive元数据Hive安装部署...
Hive安装与配置详解
标签: hive


文章目录什么是Hive的分区分区意义分区技术分区方法和本质创建一级分区表创建二级分区表如何修改Hive的分区查看分区添加分区分区名称修改修改分区路径删除分区分区类别hive的严格模式笛卡尔积分区表没有分区字段过滤...

使用Hive构建数据仓库已经成为了比较普遍的一种解决方案。目前,一些比较常见的大数据处理引擎,都无一例外兼容Hive。Flink从1.9开始支持集成Hive,不过1.9版本为beta版,不推荐在生产环境中使用。在Flink1.10版本中...
Hive的安装与配置 第1关:Hive的安装与配置
查看hive版本
Hive主键、唯一约束等条件探索一、官网查看二、探索1.官网操作2.查找资料3.官网验证4.探索意义 一、官网查看 点击此处查看官方文档 其中Create table: CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_...

推荐文章
- K2 blackpearl 流程开发(二)-程序员宅基地
- HTML5(超文本标记语言)-程序员宅基地
- 数据产品-指标体系和埋点设计_数据体系与埋点规划-程序员宅基地
- ROST情感分析的语法规则_NLP技术之句法分析-程序员宅基地
- Mysql 恢复误删库表数据_mysql还原删除的表数据-程序员宅基地
- Ubuntu22 安装 mysql5.7 过程记录_ubuntu 22 install mysql 5.7-程序员宅基地
- centos7终端命令查看图片_centos7 查看png图片-程序员宅基地
- Multi-Task Learning的几篇综述文章-程序员宅基地
- C语言获取硬件信息(CPU序列号,硬盘序列号,网卡IP、MAC地址、是否插入网线)_c获取cpu序列号-程序员宅基地
- 【Elasticsearch】es 定期删除 已经删除的数据 物理删除 不是等待段合并-程序员宅基地