spark submit 参数
”spark“ 的搜索结果
Spark基础以及WordCount实现
源码设计,具体请到资源详情查看使用前必读
[已解决]Spark执行wordcount找不到文件

机器学习算法的实现,对Hadoop,Spark,Hive等的搭建及其使用
计算机毕业设计灭绝导师Hadoop+Spark知识图谱体育赛事推荐系统 体育赛事热度预测系统 体育赛事数据分析 体育赛事可视化 体育赛事大数据 机器学习 大数据毕业设计 大数据毕设 机器学习 人工智能

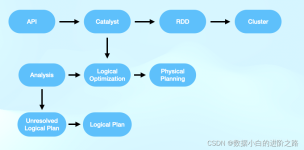
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点...
探索Spark Learning:数据处理与分析的新篇章 项目地址:https://gitcode.com/sjyttkl/spark_learning 在大数据处理和分析的世界中,Apache Spark以其高效、易用和弹性而闻名。现在,我们有了一个更深入学习Spark的...
IDEA 本地运行Spark
标签: spark

基于spark的共享单车数据分析前端后端的完整代码(优质项目).zip个人经导师指导并认可通过的98分毕业设计项目,主要针对计算机相关专业的正在做毕设的学生和需要项目实战练习的学习者。也可作为课程设计、期末大...
基于Spark+PageRank算法构建仿微博用户好友的分布式推荐系统.zip 1、该资源内项目代码经过严格调试,下载即用确保可以运行! 2、该资源适合计算机相关专业(如计科、人工智能、大数据、数学、电子信息等)正在做课程...
spark序列化方式 分布式的程序存在着网络传输,无论是数据还是程序本身的序列化都是必不可少的。spark自身提供两种序列化方式: java序列化:这是spark默认的序列化方式,使用java的ObjectOutputStream框架,只要是...
项目开发 系统设计 Spark 机器学习 大数据 算法 源码 项目开发 系统设计 Spark 机器学习 大数据 算法 源码 项目开发 系统设计 Spark 机器学习 大数据 算法 源码 项目开发 系统设计 Spark 机器学习 大数据 算法 源码 ...
详情请查看资源内容中的使用说明
我们在之前的文章中 已经了解了 spark支持的模式,其中一种就是 使用k8s进行管理。 hadoop组件—spark----全面了解spark以及与hadoop的区别 是时候考虑让你的 Spark 跑在K8s 上了 spark on k8s的优势–为什么要把...

随着大数据技术的发展,一些更加优秀的组件被提了出来,比如现在最常用的Spark组件,基于RDD原理在大数据处理中占据了越来越重要的作用。在此我们探索了Spark的原理,以及其在大数据开发中的重要作用。...


2018-11-02 Apache Spark 官方发布了 2.4.0版本,以下是 Release Notes,供参考: Sub-task [ SPARK-6236 ] - 支持大于2G的缓存块 [ SPARK-6237 ] - 支持上传块> 2GB作为流 [ SPARK-10884 ] - ...
包括:《Spark大数据处理:技术、应用与性能优 》 《Spark大数据处理技术》 《Spark高级数据分析》 《Spark快速数据处理_中文版》 《大数据Spark企业级实战》 《Spark 编程指南》 方便大家共同学习
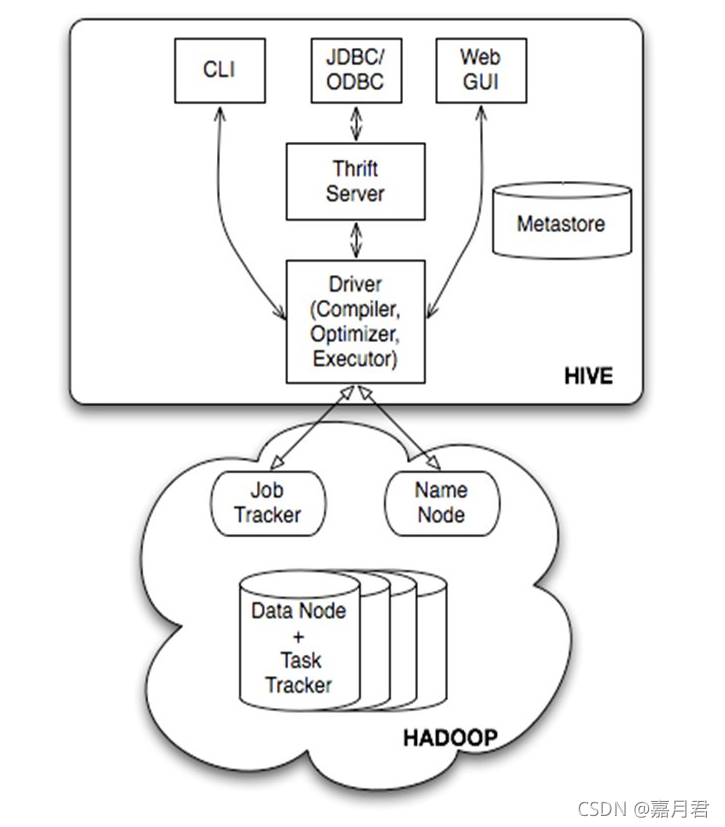
Hive和Spark
标签: hive
1. Hive简介 hive的定位是数据仓库,其提供了通过 sql 读写和管理分布式存储中的大规模的数据,即 hive即负责数据的存储和管理(其实依赖的是底层的hdfs文件系统或s3等对象存储系统),也负责通过 sql来处理和分析...


推荐文章
- yolov3系列(四)-keras-yolo3-实时眼睛鼻子嘴巴监测系统_眼睛 嘴巴 yolo-程序员宅基地
- C++类型支持之std::decltype-程序员宅基地
- GB/T28181国标视频监控平台TINYGBS支持4G执法记录仪接入大型可视指挥调度平台-程序员宅基地
- 毕设项目 基于wifi的室内定位算法设计与实现-程序员宅基地
- 【.Net】C# 根据绝对路径获取 带后缀文件名、后缀名、文件名、不带文件名的文件路径...-程序员宅基地
- c语言比用delay更好的延时,PIC单片机C语言程序设计(15)-程序员宅基地
- 微型计算机的细思维特征,详细版2014计算机基础期末考试大纲-程序员宅基地
- org.eclipse.wst.common.component_org/eclipse/wst/common/componentcore/resources/ivi-程序员宅基地
- 数据结构乐智教学百度云_数据结构 百度网盘分享-程序员宅基地
- Arcade 绘制全屏-程序员宅基地