Hadoop-eclipse-plugin插件安装 1、 下载与Hadoop对应版本的hadoop-eclipse-plugin-*.*.*.jar 2、 将“hadoop-eclipse-plugin-*.*.*.jar”复制到MyEclipse目录下的MyEclipse10下的dropins文件夹内(这里注意,...
”window安装hadoop3.1.3“ 的搜索结果

由于需要进行Hudi的详细选型,本文从0开始搭建一个Spark+Hudi的环境,并...Hadoop安装的是单节点伪分布式环境,版本选择和后继的Spark选择有关联。例如:Hadoop 3.2.3Hudi当前支持的是Spark3.2,对应的Spark也是3.2。1
第二章 Hadoop运行环境搭建 2.1 模板虚拟机环境准备 安装模板虚拟机 ip地址:192.168.10.100 主机名称: hadoop100 内存4G 硬盘50G hadoop100虚拟机配置要求如下(centos7.5-x86-1804) 使用yum安装需要虚拟机...
MapReduce是一个分布式运算程序的编程框架,是用户开发基于Hadoop的数据分享应用的核心框架。 MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序并发运行在一个Hadoop...
备赛笔记——2024全国职业院校技能大赛“大数据应用开发”赛项——任务2:离线数据处理
目录 1 软件环境:... 1 2 角色配置:... 1 3 Hadoop完全分布式集群配置... 1 3.1 下载安装JDK.. ...3.3安装hadoop. 4 3.4安装eclipse. 6 3.5安装hadoop的eclipse插件... 6 4安装maven. 8 5安装hbase. 9 6 安装hive.

hadoop就是java写的,所以必须要安装jdk 真实的工作是准备服务器,而不是虚拟机。 最小化的虚拟机,需要最少2G的内存 模板机,比较干净。 最小化的比图形化的省资源。 启动虚拟机,登录root用户 123321登陆进去。...
尚硅谷大数据开发Day02
标签: hadoop
这个博客是学习尚硅谷大数据课程所作的笔记,课程原地址可以访问https://www.bilibili.com/video/BV1Qp4y1n7EN?p=7&spm_id_from=pageDriver,感谢尚硅谷免费提供的课程资料,同时感谢...3)广义上来说,Hadoop..

1.安装前准备1.1 环境准备1.2 安装maven配置环境变量修改maven本地仓库配置和阿里云maven远程仓库。

'-Dhadoop.security.logger' 不是内部或外部命令,也不是可运行的程序 ‘-Dhadoop.security.logger’ 不是内部或外部命令,也不是...根据命令 java -version,where java 可以查看java版本和安装路径,我的问题是默认路径
【代码】大数据环境安装配置。
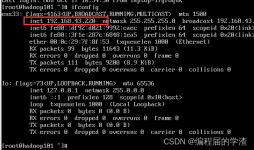

环境安装1.1 准备三台虚拟机,分别是hadoop102、hadoop103、hadoop1041.1.1 vagrant虚拟机配置1.1.2 虚拟机安装1.2 修改root用户密码1.3 修改host配置文件1.4 新增hadoop用户1.5 配置免密登录1.6 配置xsync脚本1.6 ...

java.net.ConnectException: Call From DW12136/10.10.0.41 to hadoop102:8020 failed on connection exception: java.net.ConnectException: Connection refused: no further information; For more details see: ...
@[TOC]从Linux的安装到HDFS上传再到MapReduce的词频统计 一、Linux的安装 在我们安装Linux之前我们需要装备一部分的镜像。正常来说,我们要做服务器的话会选择CentOS或者是Ubuntu Server;我们做桌面系统的话,我们...
1.安装说明1.1: 安装参数: ubuntu: 14.04.5; hadoop: 2.9.0; jdk: 1.8.0_1211.2: 配置集群机器:三台主机(或虚拟机)搭建分布式集群环境(Ubuntu-14.04.5)(同一局域网)(可先准备一台): ip hostname comment 192....
本文主要以Kettle概述、Kettle开发环境部署、mac m1 kettle安装、linux kettle安装、kettle集群安装部署、kettle输入、kettle输出、kettle转换、kettle批量加载、kettle流程、kettle脚本、kettle的Java代码案例、...
建议在Linux下进行开发,Windows下存在诸多的问题。 我的运行环境 CentOS 6.4 搭建过程 1,下载Eclipse ... 推荐下载J2EE版本,有备无患...根据自己操作系统的版本选择32位或64位 ...但是如果没有配置Java环境或安装...

java 大数据
在本文中,我们介绍了 AI 大模型的核心概念、未来发展趋势和挑战,以及其未来发展趋势和潜在应用领域的挑战的解决方案。我们 hope 这篇文章能够帮助读者更好地理解 AI 大模型的相关知识和应用。...
推荐文章
- Java---简单易懂的KNN算法_jf.knn-%; 9 &-程序员宅基地
- 最新版ffmpeg 提取视频关键帧_从视频中获取flag-程序员宅基地
- 【ARM Cache 系列文章 11 -- ARM Cache 直接映射 详细介绍】
- Objective-C学习计划
- 【数据结构】最小生成树(Prim算法、Kruskal算法)解析+完整代码
- python访问组策略_python 模块 wmi 远程连接 windows 获取配置信息-程序员宅基地
- html把div做成透明背景,DIV半透明层 CSS来实现网页背景半透明-程序员宅基地
- 关机恶搞小程序
- mnist手写数字分类的python实现_TensorFlow的MNIST手写数字分类问题 基础篇-程序员宅基地
- wxpython窗口跳转_WxPython-用按钮打开一个新窗口-程序员宅基地