用matlab编写的二维最大熵和最小交叉熵实现图像的分割,之后再用灰度值进行图像增强。
”交叉熵“ 的搜索结果
tensorflow四种交叉熵的详细的计算公式,及python实现方式
在信息论当中,我们经常用熵来表示信息的混乱程度和不确定程度。熵越大,信息的不确定性就越强。 熵的公式如下: (注:log默认以2为底) 把这个公式拆开来看其实非常简单:一个负号,一个p(x)以及log(p(x))。...
回归与分类是机器学习中的两个主要问题,二者有着紧密的联系,但又有所不同。在一个预测任务中,回归问题解决的是多少的问题,如房价预测问题,而分类问题用来解决是什么的问题,如猫狗分类问题。...
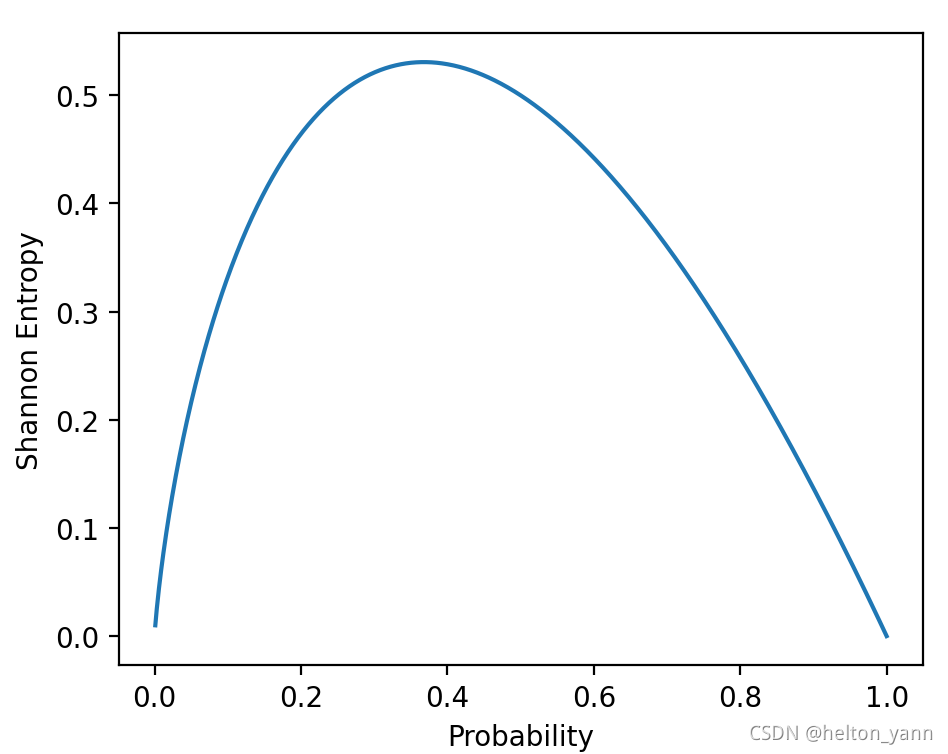
1、自信息、香农熵 信息论的基本思想是一个不太可能得事件居然发生了,要比一个非常可能发生的事件发生,能提供更多的信息。 定义一个事件发生的自信息为: I(x)=−logP(x) I(x) = -\log P(x) ...
交叉熵损失函数
标签: 深度学习 tensorflow python
交叉熵损失函数 多分类的交叉熵损失函数: CrossEntropy(x)=∑i=1cyi⋅log(y^)yi=softmax(xi)=exi∑i=1cexi CrossEntropy(x) = \sum_{i=1}^cy_i\cdot\log(\hat{y})\quad y_i = softmax(x_i)=\frac{e^{x_i}}{\sum_{...
压缩文件中有两个.py文件,分别为深度强化学习的交叉熵优化方法和策略优化方法的完整代码,readme文件中提供的资料中有具体的操作细节以及算法解释

交叉熵怎么会有负数。 经过排查,交叉熵不是有个负对数吗,当网络输出的概率是0-1时,正数。可当网络输出大于1的数,就有可能变成负数。 所以加上一行就行了 out1 = F.softmax(out1, dim=1) 补充知识:在pytorch...
关于交叉熵损失函数的视频介绍
在介绍交叉熵之前首先介绍熵(entropy)的概念。熵是信息论中最基本、最核心的一个概念,它衡量了一个概率分布的随机程度,或者说包含的信息量的大小。 首先来看离散型随机变量。考虑随机变量取某一个特定值时包含...
通用的说,熵(Entropy)被用于描述一个系统中的...要想明白交叉熵(Cross Entropy)的意义,可以从熵(Entropy) -> KL散度(Kullback-Leibler Divergence) -> 交叉熵这个顺序入手。 当然,也有多种解释方法...
我觉得讲清交叉熵根本不需要一堆公式和各种术语。 前言 交叉熵损失常用于分类任务。 优点是误差较大时,学习速度较快。 本文以pytorch中自带的实现函数为依据,解释下交叉熵损失的计算过程。 二分类任务单样本 以...
首先是交叉熵损失函数,语义分割其实是一个逐像素分类的一个分类问题,做过图像分类的应该都比较熟悉交叉熵损失函数。 pytorch中自带有写好的交叉熵函数,只需要调用就行: loss_func = nn.CrossEntropyLoss() ...
交叉熵损失函数的直观理解是计算神经网络预测的标签分布与真实标签分布之间的距离。在神经网络的训练过程中,交叉熵损失越小,表示神经网络的预测结果与真实结果的误差越小。交叉熵(Cross Entropy)损失函数是一种...
交叉熵损失函数 tf.nn.softmax_cross_entropy_with_logits 形式: tf.nn.softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, dim=-1, name=None) 作用:计算labels和logits之间的交叉熵...
说起交叉熵损失函数「Cross Entropy Loss」,相信大家都非常熟悉,但是要深入理解交叉熵损失函数的原理和作用,还得溯本追源才能对其有一个真实的理解与认知。 交叉熵 交叉熵是用来度量两个概率分布的差异性的,...
Sklearn 中二分类问题的交叉熵计算二分类问题的交叉熵在二分类问题中, 损失函数 (loss function) 为交叉熵 (cross entropy) 损失函数. 对于样本点 (x,y) 来说, y 是真实的标签, 在二分类问题中, 其取值只可能为集合{...
深度学习中的交叉熵误差原理
标签: 交叉熵
深度学习中的交叉熵误差原理
转自:https://blog.csdn.net/QW_sunny/article/details/72885403Tensorflow交叉熵函数:cross_entropy注意:tensorflow交叉熵计算函数输入中的logits都不是softmax或sigmoid的输出,而是softmax或sigmoid函数的输入...

交叉熵损失函数的推导
标签: 机器学习
文章目录前言一、交叉熵是什么?二、解决sigmoid激活函数的问题1.sigmoid损失函数存在的问题2.交叉熵的引入2.读入数据总结 前言 最近在学习自然语言处理,其中大量模型涉及到了用softmax层作为输出,再用交叉熵...
标准的交叉熵是 ,其中n代表n种类别,代表该类别的标签值,该样本属于这一类别的概率 原始GAN的目标函数是两个交叉熵期望的简化形式,即真实样本和生成样本的交叉熵相加。 真实样本:其完整交叉熵是,...
1. 信息熵 信息熵就是信息的不确定程度,信息熵越小,信息越确定 信息熵=∑事件x发生的概率∗验证事件x需要的信息量信息熵=\sum 事件x发生的概率*验证事件x需要的信息量信息熵=∑事件x发生的概率∗验证事件x需要的...
交叉熵,torch.nn.CrossEntropyLoss()
聊一聊损失函数什么是损失函数损失函数重要吗有哪些损失函数 什么是损失函数 损失函数(loss function)是用来估量模型的预测值与真实值的不一致程度,它是一个非负函数,记为一般来说,损失函数越小,模型的鲁棒性...
推荐文章
- 反编译delphi_反编译Delphi(1/3)-程序员宅基地
- node_acl用法示例_node acl-程序员宅基地
- 使用STM32提供的DSP库进行FFT_stm32的dsp库 直流分量-程序员宅基地
- VScode 报错 :crbug/1173575, non-JS module files deprecated._crbug/1173575是什么原因-程序员宅基地
- C++学习_3-程序员宅基地
- eigen 构造变换矩阵(Eigen::Isometry3d或者Eigen::Matrix4d)的几种方式-程序员宅基地
- C++ 如何初始化静态类成员(静态成员必须在.cpp文件中初始化)_c++ 静态成员变量初始化-程序员宅基地
- 48,原子核物理实验方法篇_短时间的高剂量照射后果-程序员宅基地
- el-dialog修改默认内边距_el-dialog__body修改padding-程序员宅基地
- 公网下远程树莓派Raspberry Pi的SSH/WOL/监控/桌面的实现_ssh wol-程序员宅基地