密度聚类,本质上就是基于一种密度的概念来进行聚类。而密度的定义本质上也是来自于两点的距离,所以其实对于聚类的算法来看,大家本质上都差不多,谁也别笑话谁。下面我们来总结介绍一种叫做DBSCAN的密度算法。 ...
”密度聚类“ 的搜索结果

通过采集风电和负荷的历史数据,并采用DBSCAN密度聚类的数据预处理方法,消除异常或小概率的电负荷和风电数据。随后,根据风电的波动性和电负荷的时序性和周期性特点,将场景提取分为电负荷场景提取和风电场景提取。...
本文基于DBSCAN密度聚类算法,提出了一种创新的风电-负荷场景生成与削减模型,通过对风电、电负荷历史数据的采集和预处理,实现了对异常数据和小概率数据的消除。然后,根据风电和电负荷的特点,将场景提取分为电...
基于密度的聚类算法 JAVA实现 能发现任何形状的聚类
基于迭代密度聚类以及SURF算子的多个弱小目标检测
人工智能/机器学习基础知识——聚类(原型聚类、密度聚类、层次聚类)
【资源说明】 1、该资源包括项目的全部源码,下载可以直接使用! 2、本项目适合作为...由时间空间成对组成的轨迹序列+循环神经网络lstm+自编码器auto-encode+时空密度聚类st-dbscan做异常检测(源码+项目说明).zip
DBSCAN算法的matlab 实现。。基于密度的聚类算法。。。

我们相信,通过我们提出的基于DBSCAN密度聚类的风电-负荷场景削减方法,能够为风电和电负荷的管理和优化提供更好的解决方案,为能源领域的发展做出积极的贡献。在能源领域,风电和电负荷是两个重要的研究方向。
因此,本文提出了一种基于DBSCAN密度聚类的风电-负荷场景削减方法,以降低风电-负荷场景的复杂性,提高电力系统的可靠性。实验结果表明,基于DBSCAN密度聚类的方法能够有效地降低场景的复杂性,提高电力系统的可靠性...
#资源达人分享计划#
基于网络化密度聚类的船舶停泊点数据挖掘.pdf
通过应用DBSCAN算法,我们可以去除那些不符合我们场景生成要求的数据点,从而提高我们模型的...[3]主要内容:代码主要做的是一个基于DBSCAN密度聚类的风电-负荷场景生成与削减模型,首先,采集风电、电负荷历史数据。
第1关:两点之间距离及相邻条件判断。

能较好地代表当前网格相对密度,然后利用它来识别具有不同密度聚簇的高密度网格单元,并从高密度单元网格进行扩展,直至生成一个聚簇骨架,对边缘网格边界点进行识别和提取,提高网格聚类精度。通过实验验证,新算法...
如果你也是看准了Python,想自学Python,在这里为大家准备了丰厚的免费。
现有大学校园网的日志数据,290条大学生的校园网使用情况数据,数据包括用户ID,设备的MAC地址,IP地址,开始上网时间,停止上网时间,上网时长,校园网套餐等。利用已有数据,分析学生上网的模式。

密度峰值聚类算法python源码,生成decision graph和聚类结果图
论述了医学图像挖掘在计算机辅助诊断中的作用,提出了采用灰度级作为 CT 图像...了采用决策树分类算法和基于密度的聚类算法对胸部和头部 CT 图像进行分类和聚类的结果及其分析,给出了分析的结论和进一步的研究方向。
鸢尾花(Iris)数据集是一个经典的数据集,用于机器学习和统计学习中的分类和聚类问题。该数据集包含了三种不同类型的鸢尾花(山鸢尾、变色鸢尾和维吉尼亚鸢尾)的测量数据,每种花各有50个样本。每个样本包含四个...
计算图像的正交多项式密度,可以根据此图确定分割图像聚类个数,更加详细的图像信息
在本文中,我们将使用 DBSCAN 算法对一个数据集进行聚类,并分析结果。epsilon 是 DBSCAN 算法中的“邻域半径”,它定义了一个数据点必须包含的数据点数量。综上所述,DBSCAN 算法是一种强大的聚类算法,它比传统的 ...
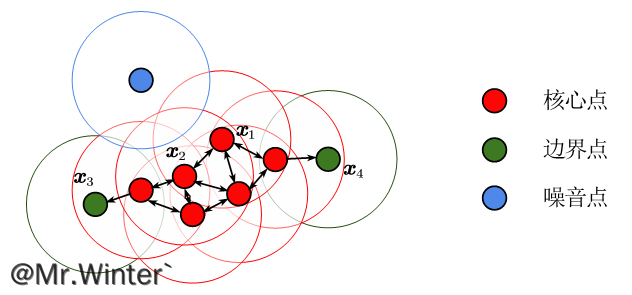

周围计算matlab代码聚类--基于--密度--峰值 一种通过快速搜索和查找密度峰值的聚类算法 来自科学的原始论文 《通过快速搜索和查找密度峰值进行聚类》 包括 这个集群存储库包括一个名为rawdata.dat的数据集和一个用于...

推荐文章
- Python Django 版本对应表以及Mysql对应版本_django版本和mysql对应关系-程序员宅基地
- Maven的pom.xml文件结构之基本配置packaging和多模块聚合结构_pom <packaging>-程序员宅基地
- Composer 原理(二) -- 小丑_composer repositories-程序员宅基地
- W5500+F4官网TCPClient代码出现IP读取有问题,乱码问题_w5500 ping 网络助手 乱码 send(sock_tcps,tcp_server_buff,-程序员宅基地
- Python 攻克移动开发失败!_beeware-程序员宅基地
- Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
- 元素三大等待-程序员宅基地
- Java软件工程师职位分析_java岗位分析-程序员宅基地
- Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
- 标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地