第八章 密度聚类、谱聚类 第九章 深度学习、TensorFlow安装和实现 第十章 TensorFlow深入、TensorBoard 十一章 DNN深度神经网络手写图片识别 十二章 TensorBoard可视化 十三章 卷积神经网络、CNN识别图片 十四章 ...
”密度聚类“ 的搜索结果
快速搜索与发现密度峰值聚类方法来确定聚类中心


目录理论部分1.1 提出背景1.2 常见算法1.3 DBSCAN算法1.3.1 基本概念1.3.2 ...基于距离的聚类方法只适用于凸型数据尤其是球状分布的数据,而难以处理非凸数据,而密度聚类法可以很好地解决这个问题,密度聚类法的基本思
周围计算matlab代码DLORE-DP Dense Members of Local Cores-based Density ...用于绘制聚类结果。 SNNDPC2.m 包含我们在实验中比较的 SNN-DPC 算法。 合成数据集 pacake 包括我们在实验中使用的合成数据集


DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密度聚类算法,和K-Means,BIRCH这些一般只适用于凸样本集的聚类相比,DBSCAN既可以适用于凸...
针对社会安全事件中异常行为信息识别挖掘难等问题,提出一种基于改进密度聚类与模式信息挖掘的异常轨迹识别方法。首先,针对采样问题,结合Hausdorff距离思想重新定义一种改进型DTW距离,用于描述轨迹具体行为,而...

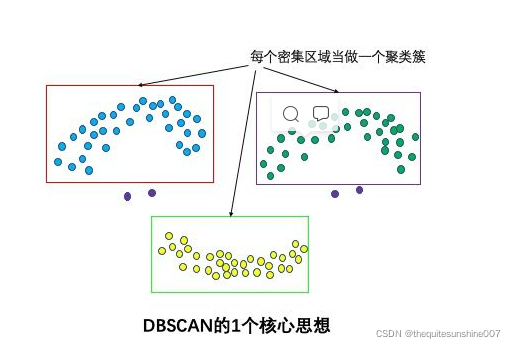
基于密度的聚类分析典型算法--DBSCAN

k-means: 优点: 1,简单,易于理解和实现; 2,时间复杂度低 缺点: 1,需要对均值给出定义, 2,需要指定要聚类的数目; 3,一些过大的异常值会...密度聚类 优点: 1, 可以对任意形状的稠密数据集进行聚类,相对的,
名称:DPC聚类算法 功能:聚类数据集 类别:密度聚类算法
结合基于视觉原理的密度聚类算法对初始化参数不敏感、能发现任意形状的聚类、能够找出最优聚类及一趟聚类算法快速高效的特点,研究可以处理混合属性的高效聚类算法.首先简单改进基于视觉原理的密度聚类算法,使之可以...
密度聚类:只要临近区域的密度、对象、或者数据点的数目超过耨个阈值,就继续聚类,可以根据与周伟特点进行聚类 kmeans和分层聚类都是基于距离进行聚类,只能发现球状的簇,五发现其他形式的簇 ...
基于matlab密度聚类算法
标签: 聚类算法
matlab密度聚类算法,内含测试数据,记得要把两个文件放在同一目录下

目录理论部分1.1 提出背景1.2...该聚类算法同样也是基于密度聚类的算法,与DBSCAN不同的是,该算法的设计使得其对初始超参数的设定敏感度较低。 1.2 OPTICS算法 1.2.1 基本概念 ·核心距离 一个对象ppp的核心距离定义为



基于密度的聚类算法DBSCAN,matlab官方程序,欢迎下载。
DBSCAN(Density—Based Spatial Clustering of Application with Noise)算法是一种典型的基于密度的聚类方法,即要求聚类空间中的一定区域内所包含对象(点或其他空间对象)的数目不小于某一给定阈值,它将簇定义...

本人在此就不搬运书上关于密度聚类的理论知识了,仅仅实现密度聚类的模板代码和调用skelarn的密度聚类算法。 有人好奇,为什么有sklearn库了还要自己去实现呢?其实,库的代码是比自己写的高效且容易,但自己实现...
推荐文章
- Python Django 版本对应表以及Mysql对应版本_django版本和mysql对应关系-程序员宅基地
- Maven的pom.xml文件结构之基本配置packaging和多模块聚合结构_pom <packaging>-程序员宅基地
- Composer 原理(二) -- 小丑_composer repositories-程序员宅基地
- W5500+F4官网TCPClient代码出现IP读取有问题,乱码问题_w5500 ping 网络助手 乱码 send(sock_tcps,tcp_server_buff,-程序员宅基地
- Python 攻克移动开发失败!_beeware-程序员宅基地
- Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
- 元素三大等待-程序员宅基地
- Java软件工程师职位分析_java岗位分析-程序员宅基地
- Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
- 标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地