traclus-master_密度聚类_轨迹预测_轨迹聚类_traclus.zip
”密度聚类“ 的搜索结果
聚类(Clustering)简单来说就是一种分组方法,将一类事物中具有相似性的个体分为一类,将另一部分比较相近的个体分为另一类。例如人和猿都是灵长目动物,但是根据染色体数目不同可以将人和猿分类不同的两类。虽然人...

基于密度的点云聚类算法可以识别三维点云物体,也可以对三维点云去噪处理。 本文研究了两种基于密度的点云聚类方法,先简单介绍一下两种算法,后面会详细的介绍算法原理以及效果。 第一种方法叫做减法聚类 功能:能...
电信设备-一种基于密度与紧密度聚类的用户移动行为确定方法.zip
基于密度聚类的多目标粒子群优化算法.pdf
1 聚类概述 样本 没有训练的样本 没有标注的样本 1.1 相似度度量 1.1.1 距离相似度度量 距离度量 dist(oi,oj)dist(o_{i},o_{j})dist(oi,oj) 欧式距离 距离相似度度量 sim(oi,oj)=11+dist(oi,oj)sim(o_{i},...
基于密度聚类的城市大气污染数据驱动区域分析
被用来识别在终端区域空间轨迹模式。利用数据的一个子集用于减少计算工作量。纽约大都会区机场使用16天。...表1显示了DBSCAN聚类过程中使用的参数设定的轨迹到达每个机场和由此产生的聚类输出的数量的集群识...
前言:Density Peaks聚类算法和DBSCAN聚类算法有相似的地方,两者都是基于密度的聚类方式。自己是在学习无监督学习过程中,无意间见到介绍这种聚类算法的文章,感觉Density Peaks聚类算法方法很新奇,操作也很简答,...
基于FAST和BRIEF的密度聚类图像匹配算法改进.pdf
密度聚类算法是一种基于密度的聚类方法,能够自动识别具有相似密度的数据点,并将其划分为不同的簇。本文将介绍DBSCAN算法的原理、实现以及在实际应用中的应用场景。本文介绍了密度聚类算法中的DBSCAN算法,包括其...
网络游戏-基于密度聚类的容迟网络路由方法.zip
层次聚类的思想有两种:凝聚的层次聚类、分裂的层次聚类。 以有A, B, C, D,E, F, G这7个样本为例。 凝聚的层次聚类 1, 将每个对象作为一个簇,这时就有7个簇。 2, 自底向上合并接近的簇,假设合并成了三...
#资源达人分享计划#
DBSCAN密度聚类的相关的知识内容可以参考 http://blog.csdn.net/luanpeng825485697/article/details/79438025 DBSCAN The DBSCAN 算法将聚类视为被低密度区域分隔的高密度区域。由于这个相当普遍的观点, ...
使用基于密度的聚类算法,进行高维特征的聚类分析,从高维数据中提取出类似的有用信息,从而简化了特征数量,并且去除了部分冗余信息。 在聚类算法中,有这样几种算法: 划分的算法, K-Means 层次的方法, CURE 基于密度的...
这些函数实现了一种距离缩放方法,由 Ye Zhu、Kai Ming Ting 和 Maia Angelova 提出,“A Distance Scaling Method to Improvement Density-Based Clustering”,PAKDD2018 会议记录: ...
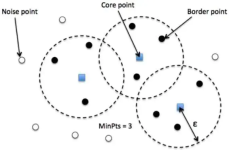
算法思想基于密度的聚类算法从样本密度的角度考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇得到最终结果。 几个必要概念: ε-邻域:对于样本集中的xj, 它的ε-邻域为样本集中与它距离小于ε的样本所...
对基于密度的分布式聚类算法 DBDC进行改进,提出了一种基于密度的分布式隐私保护聚类算法 DBPPDC。 在由局部模型确定全局模型时,通过相关安全协议有效地保护了局部模型,同时不影响全局聚类。在利用全局模型 更新局部...
提出了一种基于网格密度的混合聚类算法。该算法使用平方误差密度函数作为密度评估标准,避免了传统密度算法由于Eps和MinPts设置不当给聚类效果带来的不稳定因素。提出了动态邻域半径策略,解决了传统密度算法采用全局...

1.密度聚类的简单介绍: 常见的密度聚类包括DBSCAN聚类和密度最大值聚类等。本文主要讲的是DBSCAN聚类。DBSCAN聚类是一个比较有代表性的基于密度的聚类算法,与划分和层次聚类方法不同,它将簇定义为密度相连的点的...
1.密度聚类 基于密度的聚类算法由于能够发现任意形状的聚类,识别数据集中的噪声点,可伸缩性好等特点,在许多领域有着重要的应用。 密度算法概念: 1)如果一个数据点周围足够稠密,也就是以这个点为中心,给定半径...
基于密度聚类的DBSCAN和kmeans算法比较-附件资源
DBSCAN算法是一种基于密度的聚类算法。针对该算法在处理混合属性数据上的不足,采用面向维度的距离的思想,对不同类型的数据定义不同的相似度度量方法和不同的相似度阚值,减少了对全局相似度阈值的依赖,提出了一种...
推荐文章
- c语言链表查找成绩不及格,【查找链表面试题】面试问题:C语言学生成绩… - 看准网...-程序员宅基地
- 计算机网络:20 网络应用需求_应用对网络需求-程序员宅基地
- BEVFusion论文解读-程序员宅基地
- multisim怎么设置晶体管rbe_山东大学 模电实验 实验一:单极放大器 - 图文 --程序员宅基地
- 华为OD机试真题-灰度图恢复-2023年OD统一考试(C卷)-程序员宅基地
- 【机器学习】(周志华--西瓜书) 真正例率(TPR)、假正例率(FPR)与查准率(P)、查全率(R)_真正例率和假正例率,查准率,查全率,概念,区别,联系-程序员宅基地
- Python Django 版本对应表以及Mysql对应版本_django版本和mysql对应关系-程序员宅基地
- Maven的pom.xml文件结构之基本配置packaging和多模块聚合结构_pom <packaging>-程序员宅基地
- Composer 原理(二) -- 小丑_composer repositories-程序员宅基地
- W5500+F4官网TCPClient代码出现IP读取有问题,乱码问题_w5500 ping 网络助手 乱码 send(sock_tcps,tcp_server_buff,-程序员宅基地