1. 字典特征抽取 代码 from sklearn.feature_extraction import DictVectorizer def dictvec(): #字典数据抽取 #实例化 dict=DictVectorizer(sparse=False) #调用fit_transform,字典储存在列表中 ...
”机器学习算法“ 的搜索结果
贝叶斯系列算法的优缺点 决策树的优缺点 支持向量机的优缺点 神经网络的优缺点 降维算法的优缺点 聚类算法的优缺点 kNN的优缺点 线性模型的优缺点
写这篇文章的目的,就是希望它可以让有志于从事数据科学和机器...我也会写下对于各种机器学习算法的一些个人理解,并且提供R和Python的执行代码。读完这篇文章,读者们至少可以行动起来亲手试试写一个机器学习的程序。
一般来说,在训练样本不同时给定的情况下,比起将所有的训练样本集中起来同时进行学习,把训练样本逐个输入到学习算法中,并在新的数据进来的时候马上对现在的学习结果进行更新,这样的逐次学习算法更加有效。...
其它机器学习、深度学习算法的...文章《机器学习算法地图》系SIGAI原创,仅供个人学习使用,未经允许,不得转载,不能用于商业目的。如需获取原版PDF全文,可搜索关注VX公众号SIGAICN。(https://0x9.me/dxRg5) ...
查看原图
来源:智车科技机器学习算法已经被广泛应用于自动驾驶各种解决方案,电控单元中的传感器数据处理大大提高了机器学习的利用率,也有一些潜在的应用,比如利用不同外部和内部的传感器的...
传统机器学习算法优缺点总结 算法 优点 缺点 K-最近邻 算法实现简单,预测的精度一般也较高 对预测集的每个样本都需要计算它和每个训练样本的相似度,计算量较大,尤其是训练集很大的时候,计算量会严重影响...
在实际应用中,通过梯度下降法求解的模型一般都是需要归一化的,比如线性回归、logistic回归、KNN、SVM、神经网络等模型。 但树形模型不需要归一化,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件...
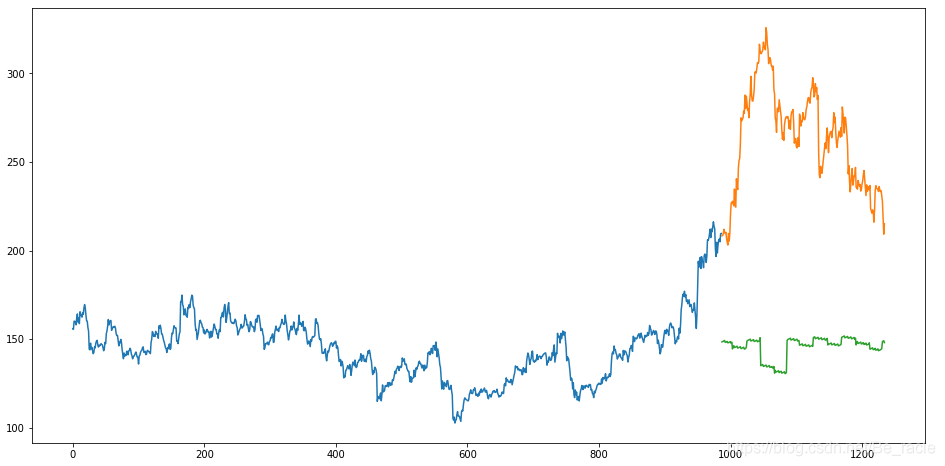
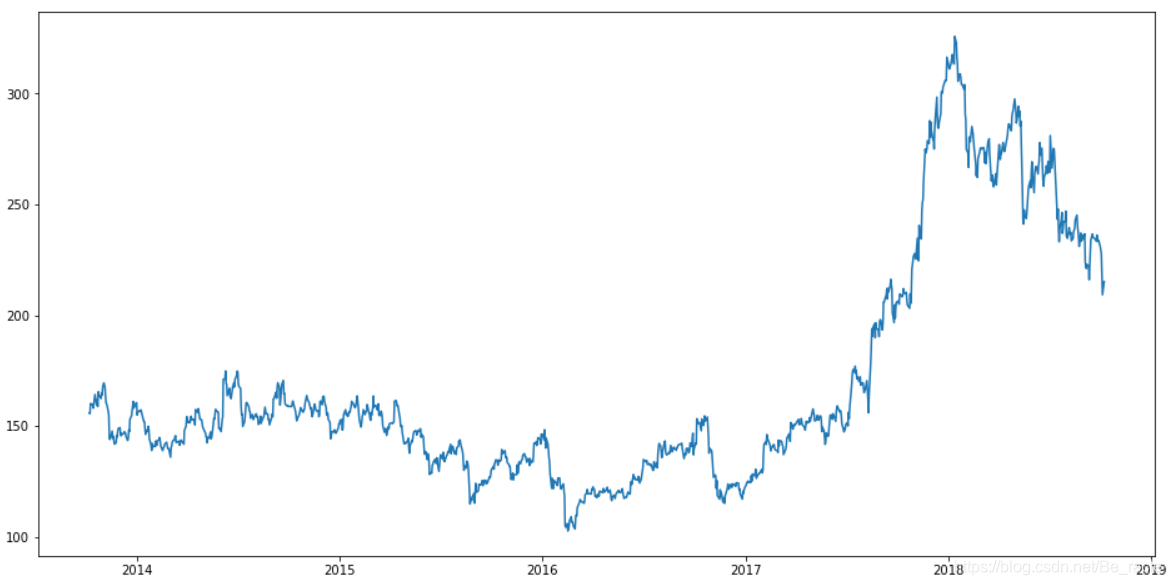
然后就开始考虑要不要使用一些其他比较简单的机器学习算法来尝试一下。打算把一些常用的机器学习算法写一个系列来跟大家分享交流,今天主要讨论的就是线性回归算法。ps:最近刚刚从组长那里知道csdn可以直接写数学...
机器学习算法的广义分类大概有三种:监督式学习、无监督学习、强化学习。 监督学习由一个目标变量或结果变量(或因变量)组成。这些变量由已知的一系列预示变量(自变量)预测而来。利用这一系列变量,我们生成一个...
在介绍如何利用机器学习算法分析和预测大数据之前,首先需要了解机器学习算法的基本原理和分类。机器学习算法主要分为监督学习、无监督学习和强化学习三大类。监督学习是利用有标签的训练数据来建立模型,通过学习...
一、朴素贝叶斯 ...3)对缺失数据不太敏感,算法也比较简单,常用于文本分类。 1.2主要缺点: 1) 理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因...
没有任何一种机器学习算法,能够做到针对任何数据集都是最佳的。通常,拿到一个具体的数据集后,会根据一系列的考量因素进行评估。这些因素包括 :要解决的问题的性质、数据集大小、数据集特征、有无标签等。有了...


LightGBM是GBDT的进化版本,在效率、内存、准确率方面表现优秀。本文讲解LightGBM的动机、优缺点及优化点、决策树算法及生长策略、类别性特征支持、并行支持与优化等重要知识点。
常见机器学习算法分类及名称
标签: 机器学习
机器学习算法 类型 缩写 全称 中文名称 分类 NN Neural Network 神经网络 Decision Tree 决策树 SVM Support Vector Machine 支持向量机 XGBoost XGBoost RF...
转自 【机器学习】 Matlab 2015a 自带机器学习算法汇总 http://blog.csdn.net/u014734238/article/details/52859581 之前一直在网上苦苦寻找各种分类器的代码,直至发现了这篇博文,发现找到了捷径,不过...
自从 MIT Technology Review(麻省理工...人工智能、机器学习、深度学习、强化学习,成为了这几年计算机行业、互联网行业最火的技术名词。 其中,深度学习在图像处理、语音识别领域掀起了前所未有的一场革命。我本人...
KNN算法(K近邻算法)是一种很朴实的机器学习方法,既可以做分类,也可以做回归。本文详细讲解KNN算法相关的知识,包括:核心思想、算法步骤、核心要素、缺点与改进等。
监督学习是机器学习中最常用的一种重要方法,它利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程。简单来说,监督学习就是从已有的标记数据中学习模型,然后利用这个模型对新的未知数据进行预测。...
本文是作者阅读《图解机器学习算法》([日] 秋庭伸也、杉山阿圣、寺田学)的相关读书笔记。读完的感受是:如果作为机器学习的入门书籍,行文和内容有点突兀,初学者通过几幅图也并不一定能懂多少。稍微有一点机器...
机器学习是人工智能领域的重要分支,它通过利用数据和统计方法让机器从经验中学习,提高其在特定任务上的性能。...本文将介绍常见的机器学习算法以及它们适用的应用领域,帮助读者了解各种算法的特点和优势。


机器学习十大算法 http://www.52cs.org/?p=1835 作者 James Le ,译者 尚剑 , 本文转载自infoQ 毫无疑问,机器学习/人工智能的子领域在过去几年越来越受欢迎。目前大数据在科技行业已经炙手可热,而...
推荐文章
- 机器学习之超参数优化 - 网格优化方法(随机网格搜索)_网格搜索参数优化-程序员宅基地
- Lumina网络进入SDN市场-程序员宅基地
- python引用传递的区别_php传值引用的区别-程序员宅基地
- 《TCP/IP详解 卷2》 笔记: 简介_tcpip详解卷二有必要看吗-程序员宅基地
- 饺子播放器Jzvd使用过程中遇到的问题汇总-程序员宅基地
- python- flask current_app详解,与 current_app._get_current_object()的区别以及异步发送邮件实例-程序员宅基地
- 堪比ps的mac修图软件 Pixelmator Pro 2.0.6中文版 支持Silicon M1_pixelmator堆栈-程序员宅基地
- 「USACO2015」 最大流 - 树上差分_usaco 差分-程序员宅基地
- Leetcode #315: 计算右侧小于当前元素的个数_找元素右边比他小的数字-程序员宅基地
- HTTP图解读书笔记(第六章 HTTP首部)响应首部字段_web响应的首部内容-程序员宅基地