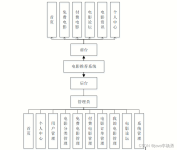
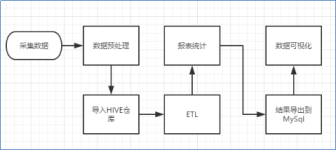
本电影院订票系统是针对目前电影院订票系统的实际需求,从实际工作出发,对过去的订票系统存在的问题进行分析,结合计算机系统的结构、概念、模型、原理、方法,在计算机各种优势的情况下,采用目前最流行的B/S结构...
”电影“ 的搜索结果
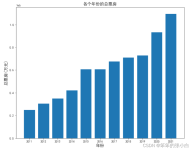
本次实验通过使用爬虫获取2016年-2023年的电影数据,并可视化分析的得出以下结论:1.2016年-2019年电影数量逐渐增大,2019年达到最大值,从2020年开始迅速逐年下降。2.发布电影数量最多的国家是中国和美国。3.电影...
豆瓣电影数据,包含电影名称、评分、评价人数、短评数量、影评、数量类型、导演、编剧、主演、上映日期等等....
由真人真事改编,程勇卖药的目的,一开始是为了自己的生计...看完电影你会发现,展现在面前的,绝不仅仅是一部电影,它分明就是一部浪漫而悠长的史诗,它不是看完之后的唏嘘叹息或捧腹大笑,它是直击灵魂的孤独......。
这些电影各具特色,涵盖了不同的题材和风格,都是中国电影的经典之作,值得观众们一一品味。
本项目实现:python+sqlite+Echarts+Wordcloud爬取豆瓣电影Top250并做简单的数据可视化处理
豆瓣电影数据集(截至2019年3月),共91369条。 包含[电影名称,评分,评价人数,各星级占比,短评数量,影评数量,类型,导演,编剧,主演,制片国家/地区,语言,上映日期,片长,网址,剧情简介]
本文基于Python的网络爬虫手段对豆瓣电影网站进行数据的抓取,通过合理的分析豆瓣网站的网页结构,并设计出规则来获取电影数据的JSON数据包,采用正态分布的延时措施对数据进行大量的获取。并利用Python的Pandas数据...
本次程序只爬取了豆瓣top250电影的展示页面的数据,没有爬取电影详情页的数据。在前面我们已经获取了每一部电影详情页的链接links,如果想要爬取电影的详情页,可以通过for循环遍历列表links,对每一个详情页发起...
对爬取的数据进行可视化
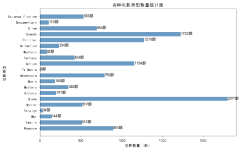
该数据集来源于kaggle,该数据集包含1995年至2018年上映的电影类型统计数据,原始数据集共有300条,9个变量,各变量含义解释如下:Genre:电影的类别或类型。(分类)Year:电影发行的年份。(数字)Movies Released...

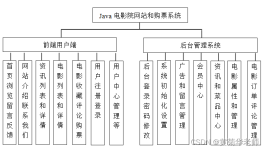
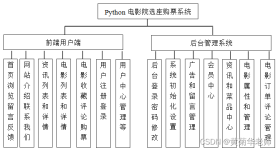
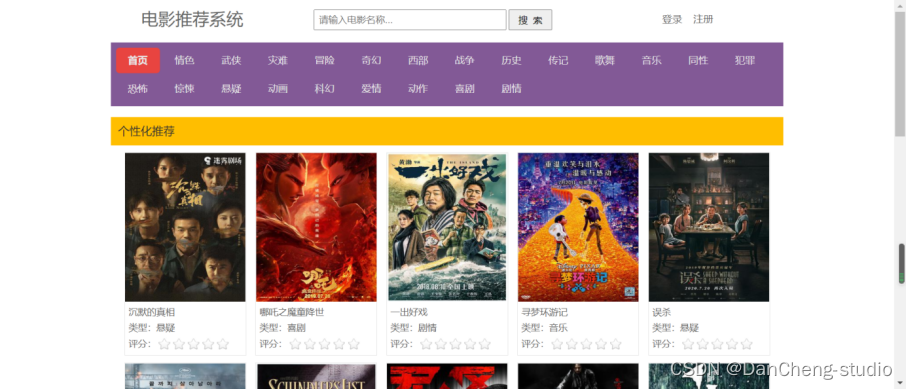
JAVA电影购票系统
标签: java
电影购票系统简介、项目功能演示 日志框架搭建、系统角色分析 首页设计、登录、商家界面、用户界面实现 商家-详情页设计、影片上架、退出 商家-影片下架、影片修改 用户-展示全部影片 用户-购票功能 用户-评分...
针对中国高票房电影,演示了从数据爬虫获取,到清洗整理,再到计算和可视化分析的全流程。
本研究旨在利用随机森林算法构建一种高效的电影票房预测模型,通过综合考虑各种影响因素,提高预测准确性,为电影产业相关方提供科学的决策依据。通过该研究,可以更好地理解影响电影票房的关键因素,为电影从业者...


推荐文章
- yolov3系列(四)-keras-yolo3-实时眼睛鼻子嘴巴监测系统_眼睛 嘴巴 yolo-程序员宅基地
- C++类型支持之std::decltype-程序员宅基地
- GB/T28181国标视频监控平台TINYGBS支持4G执法记录仪接入大型可视指挥调度平台-程序员宅基地
- 毕设项目 基于wifi的室内定位算法设计与实现-程序员宅基地
- 【.Net】C# 根据绝对路径获取 带后缀文件名、后缀名、文件名、不带文件名的文件路径...-程序员宅基地
- c语言比用delay更好的延时,PIC单片机C语言程序设计(15)-程序员宅基地
- 微型计算机的细思维特征,详细版2014计算机基础期末考试大纲-程序员宅基地
- org.eclipse.wst.common.component_org/eclipse/wst/common/componentcore/resources/ivi-程序员宅基地
- 数据结构乐智教学百度云_数据结构 百度网盘分享-程序员宅基地
- Arcade 绘制全屏-程序员宅基地