空洞卷积(膨胀卷积)的相关知识以及使用建议(HDC原则)-程序员宅基地
技术标签: 面试题(Interview Questions) 计算机视觉 深度学习 深度学习(Deep Learning) 神经网络
1. 空洞卷积的介绍
空洞卷积(Atrous Convolution)又名膨胀卷积(Dilated Convolution)。
dilated 英
[daɪˈleɪtɪd]美[daɪˈleɪtɪd]
v. 扩大; (使)膨胀,扩张;
[词典] dilate的过去分词和过去式;
atrous
adj. 深黑的; 暗灰色的; 纯黑色的;
1.1 空洞卷积和普通卷积的对比
下面是普通的卷积:

下面是空洞卷积:

二者的卷积核大小都是一样的(滑窗的实际大小是一样的),但空洞卷积的滑窗(kernel)元素之间是存在一些间隙的,这些间隙在空洞卷积中成为膨胀因子(dilated ratio)。
如果 dilated ratio=1 时,空洞卷积就是普通卷积。
1.2 膨胀卷积的作用
- 增大感受野
- 保持原输入特征图的高度和宽度
上面的膨胀卷积示意图中,因为没有设置padding,所以特征图变小了。而在实际使用中,一般都会对padding进行设置(将padding设置为1),这样就能保证输入特征图的高度和宽度不变。
1.3 为什么要使用膨胀卷积
在语义分割中,通常会使用分类网络作为backbone。通过backbone之后会对特征图进行一系列的下采样,之后再进行一系列的上采样还原原图的大小。流程如下图所示:

在分类网络中,一般都会对图片的高度和宽度下采样 32 倍。由于后续需要通过上采样还原到原来的尺寸,所以如果下采样的倍率很大时,使用上采样还原回原来的尺寸,这个过程就是导致比较严重的信息丢失。
以 VGG16 为例,该网络通过 MaxPooling 层对特征图进行下采样:
- 通过 MaxPooling 会降低特征图的 shape
- MaxPooling 会丢失特征图的一些细节信息(毕竟是用最大值代替局部值,丢失信息是肯定的)
- 丢失的信息和目标是无法通过上采样进行还原的
这就导致在语义分割任务的效果不理想。
思考:
Q1:既然MaxPooling会损失信息,那么直接不用MaxPooling不就行了?
A1:如果我们简单粗暴地将MaxPooling去掉的话,会引入新的问题:
- 特征图对应原图的感受野变小了
- 为后面的卷积层带来影响(感受野不变,卷积层就无法获取深层的信息)
此时,膨胀卷积就可以解决上面的问题,因为膨胀卷积:
- 增大特征图的感受野
- 保证输入输出特征图的shape不变
Q2:既然膨胀卷积有这样的好处,那我们是否可以简单粗暴地堆叠膨胀卷积层呢?
A2:很明显,不行!
2. gridding effect问题
在膨胀卷积使用的过程中经常会遇到一个名叫 gridding effect 的问题。

2. 1 什么是gridding effect —— 连续使用几个膨胀系数相同的膨胀卷积
如下图所示,连续使用3个膨胀卷积层(卷积核大小都为3×3,膨胀系数均为2)

我们先看一下 Layer2 上,每一个pixel利用到了 Layer1 上的哪些pixels。

我们可以看到,膨胀系数是2表示卷积核每两个数据之间都间隔一行或一列0。
所以Layer2 上一个pixels会使用Layer1的9个pixels。
我们再看一下Layer3

当我们连续使用2个膨胀系数为2的膨胀卷积时,Layer3上一个pixel利用到了Layer1上25个pixels的信息。
每个pixel上的数字表示:通过累加得到Layer3上一个pixel利用到Layer1上该像素的次数
看一下Layer4

当我们连续使用3个膨胀系数为2的膨胀卷积时,Layer4上一个pixel利用到了Layer1上的数据并不是连续的!在每个非零元素之间都存在一定的间隔 —— 这就是gridding effect现象。
也就是说Layer4上的一个像素并没有利用到范围内的所有像素值,而是一部分。
因为没有利用到所有的像素值,所以一定会丢失一部分细节信息 —— 和MaxPooling一样(但是比MaxPooling要轻微)
所以在使用膨胀卷积时要尽可能避免 gridding effect 问题(不要连续使用多个膨胀系数相同的膨胀卷积)。
2.2 连续使用几个膨胀系数不同的膨胀卷积

膨胀系数设置为1就是普通的卷积
看一下Layer2:

因为是普通卷积,所以利用到了卷积核大小窗口内所有Layer1的像素。
看一下Layer3:

Layer3上的一个像素对应Layer1上7×7的区域,而且该区域中每一个像素的利用次数不同(但都利用到了)
看一下Layer4:

Layer4上的一个像素对应Layer1上13×13的区域,而且该区域中每一个像素的利用次数不同(但都利用到了)
2.3 两种使用方法的对比

- 两种方法的参数数量是一样的
- 仅仅是膨胀系数不同而已
对于 r=[2, 2, 2] 这样连续相同的膨胀卷积来说,Layer4的感受野是13×13,但在这个视野下有很多像素值是没有利用到的。我们更加倾向于使用 r=[1, 2, 3] 这样不相同连续的膨胀系数 —— 感受野下使用的区域是连续的。
2.4 如果全部使用普通的卷积

我们发现:
- 直接使用普通卷积Layer4的感受野和前面的两种膨胀卷积不同
- 膨胀卷积的感受野为 13×13
- 普通卷积的感受野为 7×7
- 这说明使用膨胀卷积可以大幅度增加感受野
3. 膨胀卷积使用方法 —— Hybird Dilated Convolution (HDC,混合膨胀卷积)
上面我们讲到,如果我们连续使用多个膨胀系数相同的膨胀卷积时,就会遇到 gridding effect 问题,所以我们建议连续使用多个膨胀系数不同的膨胀卷积。但这样的说法并没有给我一个明确的设计原则,所以接下来讲一下,如果我们想要连续使用多个膨胀卷积时,应该如何设计它们的膨胀系数。
3.1 论文中第一个建议: M 2 ≤ K M_2 \le K M2≤K
通过 2.2 和 2.3 的实验可以得出:使用 r=[1, 2, 3] 的膨胀系数和使用 r=[2, 2, 2] 膨胀系数的感受野是相同的,但前者对于输入信息的利用率高 —— 理论效果更好。

假设我们连续堆叠 N N N个膨胀卷积(它的 kernel_size 都是等于 K × K K \times K K×K 的),每个膨胀卷积的膨胀系数分别对应 [ r 1 , r 2 , . . . , r n ] [r_1, r_2, ..., r_n] [r1,r2,...,rn]。那 HDC 的目标是通过一系列膨胀卷积之后可以完全覆盖底层特征层的方形区域,并且该方形区域中间是没有任何孔洞或缺失的边缘(withou any holes or missing edges)。作者定义了一个叫做"maximum distance between two nonzero values"的公式,即两个非零元素之间最大的距离。
需要注意的是,在计算距离的时候需要+1。举个例子,A→B假设有两行的0元素,那么它们直接的距离就是3,而非2)
公式定义如下:
M i = max [ M i + 1 − 2 r i , M i + 1 − 2 ( M i + 1 − r i ) , r i ] = max [ M i + 1 − 2 r i , 2 r i − M i + 1 , r i ] = max [ 正 , 负 , r i ] \begin{aligned} M_i & = \max [M_{i+1} - 2r_i, M_{i+1} - 2(M_{i+1} - r_i), r_i] \\ & = \max[M_{i+1} - 2r_i, 2r_i - M_{i+1}, r_i] \\ & = \max[正, 负, r_i] \end{aligned} Mi=max[Mi+1−2ri,Mi+1−2(Mi+1−ri),ri]=max[Mi+1−2ri,2ri−Mi+1,ri]=max[正,负,ri]
其中:
- M i M_i Mi 是第 i i i 层两个非零元素之间的最大距离;
- r i r_i ri 为第 i i i 层的膨胀系数;
- 对于最后一层,它的最大距离为 M n = r n M_n = r_n Mn=rn,即最大距离为该层的膨胀率
这么设计的目的是让 M 2 ≤ K M_2 \le K M2≤K,即 第二层的两个非零元素之间的最大距离 ≤ 该层卷积核的大小。
需要注意的是:
- 紧密挨着的距离为 1
- 像
r=[2, 2, 2]中那样,两个非零元素之间的距离为2 —— 意味着二者之间间隔了一行或者一列。
3.2 针对第一个建议给出的两个例子
3.2.1 例子1
当 kernel_size=3,即 K = 3 K=3 K=3 时,对于膨胀系数 r = [ 1 , 2 , 5 ] r=[1, 2, 5] r=[1,2,5] 来说:
M 2 = max [ M i + 1 − 2 r i , M i + 1 − 2 ( M i + 1 − r i ) , r i ] = max [ M 3 − 2 r 2 , M 3 − 2 ( M 3 − r 2 ) , r 2 ] = max [ 5 − 4 , 4 − 5 , 2 ] = max [ 1 , − 1 , 2 ] = 2 ≤ K ( 3 ) \begin{aligned} M_2 & = \max [M_{i+1} - 2r_i, M_{i+1} - 2(M_{i+1} - r_i), r_i]\\ & = \max [M_3 - 2r_2, M_3 - 2(M_3 - r_2), r_2]\\ & = \max [5-4, 4-5, 2]\\ & = \max [1, -1, 2]\\ & =2 \le K(3) \end{aligned} M2=max[Mi+1−2ri,Mi+1−2(Mi+1−ri),ri]=max[M3−2r2,M3−2(M3−r2),r2]=max[5−4,4−5,2]=max[1,−1,2]=2≤K(3)
因为 M 2 ≤ K M_2 \le K M2≤K,所以当 kernel_size=3时,选择 r=[1, 2, 5] 是满足设计要求的。
3.2.2 例子2
当 kernel_size=3,即 K = 3 K=3 K=3,对于膨胀系数 r = [ 1 , 2 , 9 ] r=[1, 2, 9] r=[1,2,9] 来说:
M 2 = max [ M i + 1 − 2 r i , M i + 1 − 2 ( M i + 1 − r i ) , r i ] = max [ M 3 − 2 r 2 , M 3 − 2 ( M 3 − r 2 ) , r 2 ] = max [ 9 − 4 , 4 − 9 , 2 ] = max [ 5 , − 5 , 2 ] = 5 ≥ K ( 3 ) \begin{aligned} M_2 & = \max [M_{i+1} - 2r_i, M_{i+1} - 2(M_{i+1} - r_i), r_i]\\ & = \max [M_3 - 2r_2, M_3 - 2(M_3 - r_2), r_2]\\ & = \max [9 - 4, 4-9, 2]\\ & = \max [5, -5, 2]\\ & = 5 \ge K(3) \end{aligned} M2=max[Mi+1−2ri,Mi+1−2(Mi+1−ri),ri]=max[M3−2r2,M3−2(M3−r2),r2]=max[9−4,4−9,2]=max[5,−5,2]=5≥K(3)
因为 M 2 > K M_2 > K M2>K,所以不满足设计要求,所以这组参数是不合适的。
3.2.3 ️使用代码直观展示元素间的最大距离
代码如下:
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import LinearSegmentedColormap
def dilated_conv_one_pixel(center: (int, int),
feature_map: np.ndarray,
k: int = 3,
r: int = 1,
v: int = 1):
"""
膨胀卷积核中心在指定坐标center处时,统计哪些像素被利用到,
并在利用到的像素位置处加上增量v
Args:
center: 膨胀卷积核中心的坐标
feature_map: 记录每个像素使用次数的特征图
k: 膨胀卷积核的kernel大小
r: 膨胀卷积的dilation rate
v: 使用次数增量
"""
assert divmod(3, 2)[1] == 1
# left-top: (x, y)
left_top = (center[0] - ((k - 1) // 2) * r, center[1] - ((k - 1) // 2) * r)
for i in range(k):
for j in range(k):
feature_map[left_top[1] + i * r][left_top[0] + j * r] += v
def dilated_conv_all_map(dilated_map: np.ndarray,
k: int = 3,
r: int = 1):
"""
根据输出特征矩阵中哪些像素被使用以及使用次数,
配合膨胀卷积k和r计算输入特征矩阵哪些像素被使用以及使用次数
Args:
dilated_map: 记录输出特征矩阵中每个像素被使用次数的特征图
k: 膨胀卷积核的kernel大小
r: 膨胀卷积的dilation rate
"""
new_map = np.zeros_like(dilated_map)
for i in range(dilated_map.shape[0]):
for j in range(dilated_map.shape[1]):
if dilated_map[i][j] > 0:
dilated_conv_one_pixel((j, i), new_map, k=k, r=r, v=dilated_map[i][j])
return new_map
def plot_map(matrix: np.ndarray):
plt.figure()
c_list = ['white', 'blue', 'red']
new_cmp = LinearSegmentedColormap.from_list('chaos', c_list)
plt.imshow(matrix, cmap=new_cmp)
ax = plt.gca()
ax.set_xticks(np.arange(-0.5, matrix.shape[1], 1), minor=True)
ax.set_yticks(np.arange(-0.5, matrix.shape[0], 1), minor=True)
# 显示color bar
plt.colorbar()
# 在图中标注数量
thresh = 5
for x in range(matrix.shape[1]):
for y in range(matrix.shape[0]):
# 注意这里的matrix[y, x]不是matrix[x, y]
info = int(matrix[y, x])
ax.text(x, y, info,
verticalalignment='center',
horizontalalignment='center',
color="white" if info > thresh else "black")
ax.grid(which='minor', color='black', linestyle='-', linewidth=1.5)
plt.show()
plt.close()
def main():
# bottom to top
dilated_rates = [1, 2, 5]
# init feature map
size = 31
m = np.zeros(shape=(size, size), dtype=np.int32)
center = size // 2
m[center][center] = 1
# print(m)
# plot_map(m)
for index, dilated_r in enumerate(dilated_rates[::-1]):
new_map = dilated_conv_all_map(m, r=dilated_r)
m = new_map
print(m)
plot_map(m)
if __name__ == '__main__':
main()
3.2.3.1 r = [1, 2, 5] 的效果图

很明显,这组参数最后一层的感受野包含了所有像素,输入的每一个像素都利用到了,不存在gridding effect问题。
3.2.3.2 r = [1, 2, 9] 的效果图

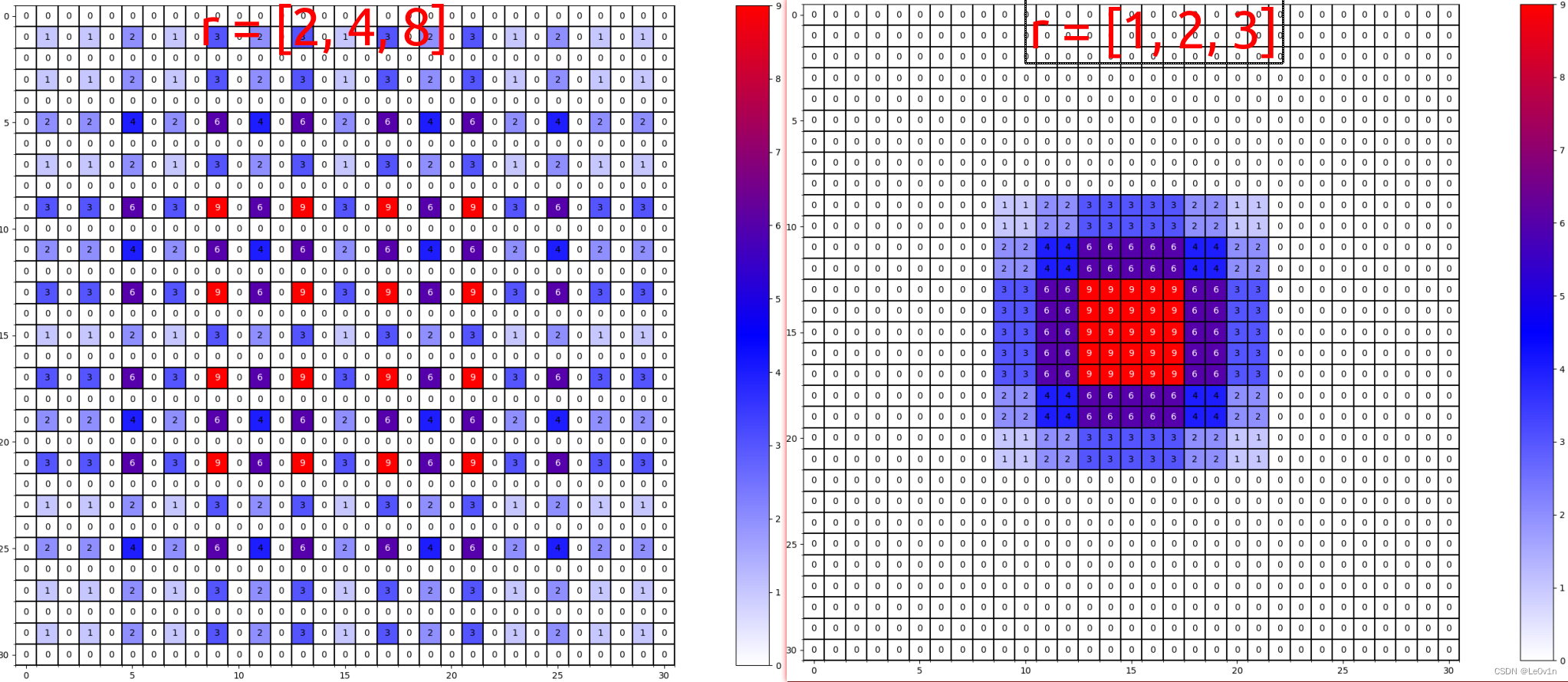
这里并不是有9个感受野,实际上这9个小块合起来才是真正的感受野。很明显,两个小块之间非零元素的最大距离为3,这与我们的期望1不符,所以该组参数是不合适的。
3.3 为什么例子中的 r r r 都是从 1 开始的?
我们希望在高层特征图的每个像素可以利用到底层特征图的感受野内的所有像素,那么 M 1 M_1 M1应该等于1。因为 M 1 = 1 M_1 = 1 M1=1意味着非零元素之间是相邻的(没有间隙的),而 M 1 M_1 M1的计算公式如下:
M 1 = max [ M 2 − 2 r 1 , M 2 − 2 ( M 2 − r 1 ) , r 1 ] = max [ M 2 − 2 r 1 , 2 r 1 − M 2 , r 1 ] = max [ 正 , 负 , r 1 ] \begin{aligned} M_1 & = \max [M_{2} - 2r_1, M_{2} - 2(M_{2} - r_1), r_1] \\ & = \max[M_{2} - 2r_1, 2r_1 - M_{2}, r_1] \\ & = \max[正, 负, r_1] \end{aligned} M1=max[M2−2r1,M2−2(M2−r1),r1]=max[M2−2r1,2r1−M2,r1]=max[正,负,r1]
既然我们希望 M 1 = 1 M_1 = 1 M1=1,那么 M 1 M_1 M1 应该 ≥ r 1 \ge r_1 ≥r1,即 1 ≥ r 1 1 \ge r_1 1≥r1,所以 r 1 r_1 r1被迫等于1。因此在设计连续膨胀卷积时,第一个膨胀率一般都是从1开始的。
3.4 论文中第二个建议:将膨胀系数设置为锯齿形状

第二个建议为:将膨胀系数设置为锯齿形状。如:r=[1, 2, 3, 1, 2, 3]。

3.4 论文中第三个建议: r r r 的公约数 ≤ 1

论文中的第三个建议:公约数不能大于1。如:
- r = [ 1 , 2 , 3 ] r = [1, 2, 3] r=[1,2,3]:它们的公约数为 1 1 1,符合①②③建议 → 设计合理
- r = [ 2 , 4 , 8 ] r=[2, 4, 8] r=[2,4,8]:它们的公约数为 2 2 2,不符合③的建议 → 设计不合理
4. 遵循HDC原则前后效果对比

- 没有按照HDC设计准则的模型(第二行),它分割的效果不是很好
- 符合HDC设计准则的模型(第三行)相比第二行来说,效果要层好不少。
5. 膨胀卷积输出特征图计算公式
5.1 普通卷积
O i c o n v / p o o l = O i i n + 2 p i − k i s i + 1 O_i^{\mathrm{conv/pool}} = \frac{O_i^{\mathrm{in}} + 2p_i - k_i}{s_i} + 1 Oiconv/pool=siOiin+2pi−ki+1
5.2 膨胀卷积
O i d i l a t e d c o n v = O i i n + 2 p i − d i × ( k i − 1 ) s i + 1 O_i^{\mathrm{dilated \ conv}} = \frac{O_i^{\mathrm{in}} + 2p_i - d_i \times (k_i-1)}{s_i} + 1 Oidilated conv=siOiin+2pi−di×(ki−1)+1
5.3 转置卷积
5.3.1 不带膨胀卷积
O i t r a n s c o n v = ( O i i n − 1 ) × s i − 2 × p i + k i O_i^{\mathrm{trans \ conv}} = (O_i^{\mathrm{in}} - 1) \times s_i - 2 \times p_i + k_i Oitrans conv=(Oiin−1)×si−2×pi+ki
5.3.2 带有膨胀卷积
O i t r a n s c o n v = ( O i i n − 1 ) × s i − 2 × p i + d i × ( k i − 1 ) + output_padding i + 1 O_i^{\mathrm{trans \ conv}} = (O_i^{\mathrm{in}} - 1) \times s_i - 2 \times p_i + d_i \times (k_i - 1) + \text{output\_padding}_i + 1 Oitrans conv=(Oiin−1)×si−2×pi+di×(ki−1)+output_paddingi+1
6. 总结
6.1 设计准则
- 第二层的两个非零元素之间的最大距离小于等于该层卷积核的大小,即 M 2 ≤ K M_2 \le K M2≤K。
其中 M i = max [ M i + 1 − 2 r i , 负 , r i ] M_i = \max [M_{i+1} - 2r_i, 负, r_i] Mi=max[Mi+1−2ri,负,ri] - 将膨胀系数设置为锯齿形状。如:
r=[1, 2, 3, 1, 2, 3] - 膨胀系数的公约数 ≤ 1,如:采用
r=[1, 2, 3]而不是r=[2, 4, 6]
6.2 实际使用
在连续使用膨胀卷积时,我们应该参考 HDC 的设计准则以保证高层可以有效利用低层的信息。
参考
- https://www.bilibili.com/video/BV1Bf4y1g7j8?spm_id_from=333.999.0.0
- https://github.com/vdumoulin/conv_arithmetic
智能推荐
阅读笔记:Exploiting High-Level Semantics for NR Image Quality Assessment of Realistic Blur Image_exploiting high-level semantics for no-reference i-程序员宅基地
文章浏览阅读3.5k次。摘要:针对这一问题,我们利用高级语义学,提出了一种新的对于真实模糊图像的无参考图像质量评价方法。1.将整个图像分成多个不重叠的补丁;2.每个补丁由从训练好的DCNN模型提取高级语义特征;3.采用三种不同的统计结构对来自不同的补丁信息进行统计,主要包含一切常见的统计方法;4聚集的特征作为线性回归模型的输入预测图像质量。1.提出的方法图像表示、特征提取、特征聚合和质量预测1.1图像表示预先训练的 dcnn 模型(例如 alexnet)需要一个固定的输入大小。为了满足这个要求,图像可以裁剪,._exploiting high-level semantics for no-reference image quality assessment of
新加入同学期待已久的YOLO V3-程序员宅基地
文章浏览阅读159次。欢迎关注“计算机视觉研究院”计算机视觉研究院专栏作者:Edison_G计算机视觉研究院长按扫描二维码关注我们好久不见各位研友(研究好友,不是考研的小伙伴,嘿嘿)!最近,因为博主事情比较繁..._yolov3 softmax loss logistic loss
深搜回溯与不回溯的区别_深搜什么时候需要回溯-程序员宅基地
文章浏览阅读1.8k次,点赞2次,收藏10次。一、需要不断尝试以达到最终目的时需要回溯,比如数独、全排列。以下为全排列代码:#include <iostream>#include <vector>#include <algorithm>using namespace std;string str;string temp;vector<bool> vis;void dfs(..._深搜什么时候需要回溯
IntelliJ IDEA 2021.2 : 更新Docker 和 Kubernetes_idea中docker-compose有个x-程序员宅基地
文章浏览阅读810次。除了我们在 EAP 期间描述的其他有用功能外,IntelliJ IDEA 2021.2还包含一些对 Kubernetes 和 Docker 有用的更新。下载IntelliJ IDEA最新版本以下功能概述将帮助您浏览众多更改。Docker 撰写服务同步以前,您的 IDE 仅在“服务”工具窗口中显示正在运行的服务。从这个 EAP 开始,你可以让你的所有 Docker Compose 应用程序出现在那里,即使它们没有运行。要显示它们,您可以单击编辑器窗口右侧的循环箭头图标。服务状态的._idea中docker-compose有个x
程序员必须掌握的核心算法有哪些?_程序的核心算法有什么-程序员宅基地
文章浏览阅读126次。From:https://blog.csdn.net/m0_37907797/article/details/102661778?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task ..._程序的核心算法有什么
pm2 常用命令_pm2 删除进程-程序员宅基地
文章浏览阅读2.6k次。先说一些废话之前学习Nodejs项目的时候使用了pm2作为生产环境的进程管理工具,最近服务器崩了需要重启一些服务,发现有些命令记得不是特别清楚,所以这里写一篇文章帮助自己记忆整理一下pm2的常用命令,后续有需要查阅一下即可~常用命令进入bin目录启动:pm2 start www / pm2 start app.jspm2 start app.js --name="fx67ll" 启动并命名为fx67ll,没有命名的话后续可以用id替代namepm2 start app.js --watch 当_pm2 删除进程
随便推点
Dex-Net 2.0 论文翻译_deep learning a grasp function for grasping under -程序员宅基地
文章浏览阅读7.9k次,点赞3次,收藏32次。一、绪论1)本文的主要贡献 1、制作dex-net2.0数据集,该数据集包括670万点云数据,又从1500个 3D模型通过GWS(抓手运行空间分析)得到手爪的运行规划 2、设计Grasp Quality Convolutional Neural Network (GQ-CNN),去得到一系列鲁棒性良好的抓取规划 3、设置一种抓取机制,可以对得到的鲁棒性良好的一组抓取规划进行 rank排序,_deep learning a grasp function for grasping under gripper pose uncertainty
JJwt生成Token-程序员宅基地
文章浏览阅读646次。JJwt生成tokenjava中通过jjwt生成tokenpackage com.zom.statistics.tools;import com.zom.statistics.DTO.JwtParams;import com.zom.statistics.DTO.RtvConsoleUser;import com.zom.statistics.exception.LogonException;import io.jsonwebtoken.*;import org.slf4j.Logger_jjwt生成token
电池充电方案总结-程序员宅基地
文章浏览阅读1.3w次。锂离子电池低电压充电(12V以下):多种化学成分电池充电器电路+源码+上位机等http://www.cirmall.com/circuit/3673/%E5%A4%9A%E7%A7%8D%E5%8C%96%E5%AD%A6%E6%88%90%E5%88%86%E7%94%B5%E6%B1%A0%E5%85%85%E7%94%B5%E5%99%A8%E7%94%B5%E8%B7%AF%2B%..._stm32单片机支持13种快冲协议的充电器源码和原理图
如何替换Citrix XenDesktop中使用的vCenter server地址-程序员宅基地
文章浏览阅读477次。一、问题描述:客户重装Vcenter之后(Hostname与之前保持一致)出现如下报错:1.计算机目录显示无法联系到vCenter server2.VM电源状态未知3.测试connection出现如下错误:Attempting to connect to the VCenter server failed due to a certificate error. Check ..._citrix vcenter替换
Android Studio Lint 工具看完这一篇还不够-程序员宅基地
文章浏览阅读6.5k次,点赞12次,收藏24次。前言以前对下面的问题,我的态度是,不报错就是没问题,报错就用快捷键,根据Android Studio提示修复问题,从来不去问个为什么?现在代码洁癖症越来越严重的我,忍不住想看清什么东西在搞鬼。认真看完本文,一定可以学到最新的知识。就算看不下去,也要点个赞收藏,绝对不亏。本文并不是吐槽Lint的不好,而是在学习Lint过程碰到问题,心态是奔溃的,以及解决每个问题带来的喜感。不知道大家有没有注意..._android studio lint
CDH激活分发parcel时因为意外错误卡住不能修改问题解决方案_cdh parcel激活一直卡住-程序员宅基地
文章浏览阅读2.7k次。问题背景:今天因为业务需求需要在CDH集群上安装StreamSets,结果因为权限的原因,之前我把这个parcel文件的权限变更为cloudera-scm,结果后面遇到这个问题了,问了之前部署CDH的人才知道他那时候用的权限是Root用户,所以现在卡在这里,也没有地方可以直接暂停:然后我点进去看详细的信息:可以看到cluster2-1这个结点因为权限的问题,导致不能激活。解决方案:Cloudera并没有在控制台开发Cancel或者回滚的入口,此时服务状态就是卡住页面无法操作。通过_cdh parcel激活一直卡住